1. 简介
Opacity Micromap (OMM) 是一种用来提供更细致透明度信息的技术,适用于加速结构中的三角形几何体。当光线与这些几何体相交时,会使用 micromap 来决定透明度,而不是单纯依赖 VK_GEOMETRY_OPAQUE_BIT_KHR。
这些 micromap 的透明度信息是透过光线与三角形相交点的 u 和 v 坐标来存取。u 和 v 坐标会被转换成整数,并映射到一条空间填充曲线上,这种曲线被称为 “bird curve”,类似于 Morton 空间填充曲线。这种编码方式具有空间连续性和层次结构,允许在光线追踪过程中高效地查找透明度状态。
每个 micromap 元素 (Figure 1-1.) 可以是透明 (T)、不透明 (O)、未知透明 (UT) 或未知不透明 (UO)。当光线击中三角形时,会查找相应的 micromap 状态。如果状态是透明,光线查询将继续进行,彷佛没有击中任何物体。如果状态是不透明,表面将被视为不透明,并更新光线的最大距离 maxT。若状态为未知透明或未知不透明,则需要进一步由 Ray Query 来决定透明度。
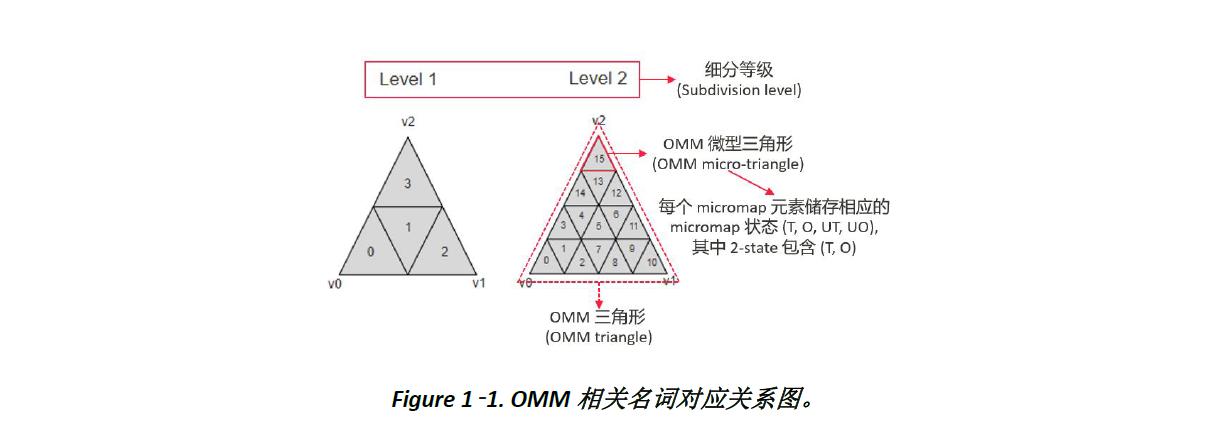
Opacity Micromap 支持多达 12 级细分,每级细分会生成 2^(2*N) 个微型三角形,构成一个OMM 三角形。这种技术能显著减少光线追踪过程中的 any hit/non-opaque 调用数量,提高整体性能。
总结来说,Opacity Micromap 透过细分三角形并使用高效编码方式来提供精细透明度信息,从而优化光线追踪性能。
接下来,本篇举例Vulkan Opacity Micromap的透明效果使用情境,并基于使用2-state (T 和 O) OMM,分为快速入门指南以协助开发者整合Vulkan OMM功能,和最佳实务提供质量、性能与带宽的OMM API和内容建议。
1.1 光追OMM游戏的优势
对于阴影效果,使用光追搭配OMM可以提升更好的质量,相比于传统Cascaded Shadow Map (CSM)。
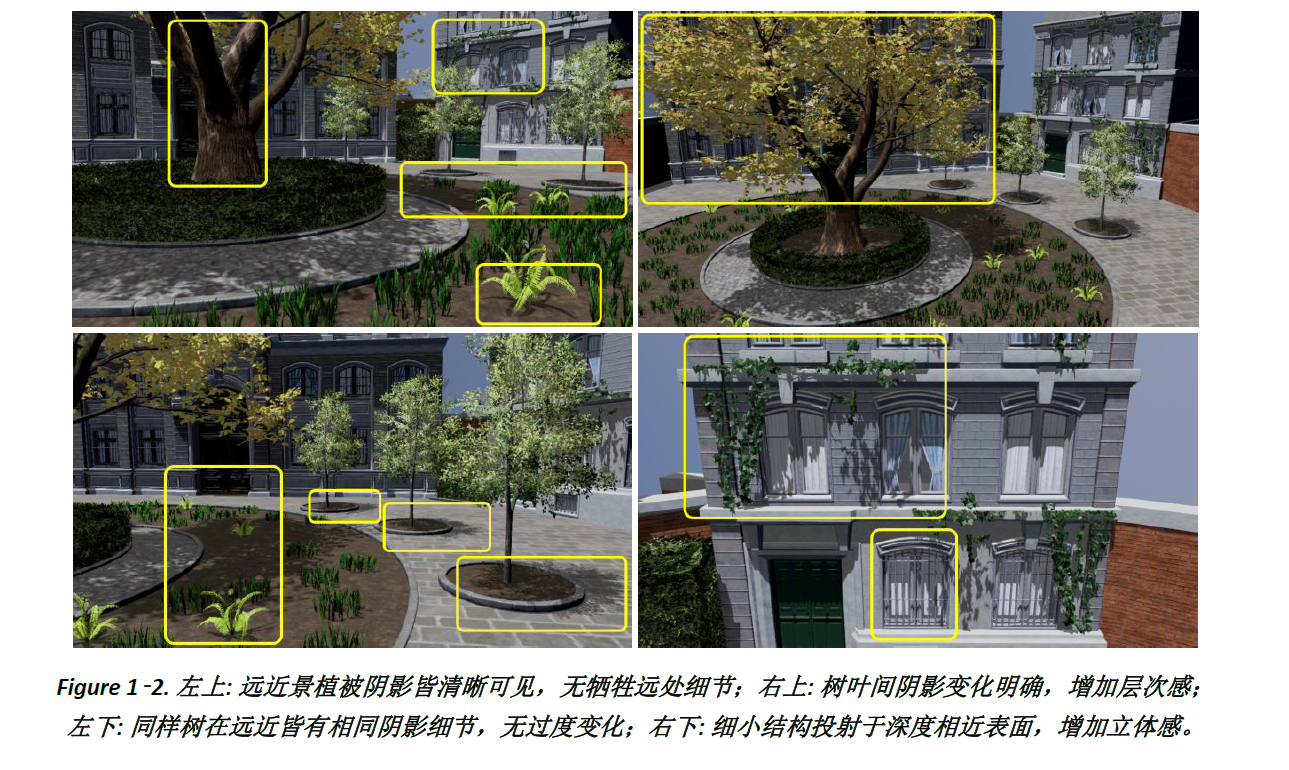
而在暗区突围,游戏对于植被使用光追搭配OMM,带来更细致的树叶光影呈现,和更拟真的对象镜射。

2. 快速入门指南
快速应用2-state OMM 步骤可分为
1. 素材准备 (§2-1): 开发基础baker工具并产生OMM数据 (*.omm)
2. 代码整合 (§2-2): 透过 OMM 扩展 API ,建置 OMM 并将数据带进 BLAS

Figure 2‑1. 快速入门指南总揽。参考来源: NVIDIA Opacity-MicroMap-SDK。
|
关于 OMM 扩展对于 2-state 的详细定义,请参阅以下连结: |
2.1 素材准备
在使用 OMM 前,需针对 asset 做预处理,透过 baker 工具将材质 opacity texture bake 至 sub-triangles。
本章范例baker工具接口定义如下:
1. 输入: 模型为gltf,工具支持 meshes为一个,且预设使用base color纹理的alpha作为 opacity
data
|- ivy
|- textures
|- Foliage_Ivy_leaf_a_BaseColor-Foliage_Ivy_leaf_a_BaseColor.png
|- ...
|- Foliage_Ivy_leaf_a.DoubleSided.bin
|- Foliage_Ivy_leaf_a.DoubleSided.gltf
|- Foliage_Ivy_leaf_a.DoubleSided_lv7.omm (output file)
2. 输出: 2-state OMM资料 (*.omm)
2.1.1 建置基础Baker工具
本节旨在透过step-by-step教学,教读者使用NVIDIA Opacity-MicroMap-SDK v1.1.1 建置范例baker工具,并支持下列输入选项:
Table 2‑2. 基础OMM baker工具 (Baker.exe) 的输入选项。
|
选项 |
型别 |
说明 |
范例 |
|---|---|---|---|
|
-f |
字符串 |
glTF模型路径,需另存纹理至文件夹,且透明纹理存于baseColorTexture,其格式为RGBA。 |
./data/ivy/Foliage_Ivy_leaf_a.DoubleSided.gltf |
|
--max-subdivision-level |
整数 |
OMM三角形的最大subdivision level,范围介于0至12。 |
7 |
|
--dyn-subdivision-scale |
浮点数 |
动态调整OMM三角形的subdivision level的阀,当<= 0时关闭。 |
2 |
前置准备工具
1. Visual Studio 17 2022
2. CMake 3.22.1
建置NVIDIA Opacity MicroMap SDK
1. 下载NVIDIA Opacity-MicroMap-SDK 。
// Assume current directory is
git clone --branch v1.1.1 --recursive https://github.com/NVIDIAGameWorks/Opacity-MicroMap-SDK.git
2. 使用CMake建置Visual Studio项目。
cd Opacity-MicroMap-SDK
cmake -G "Visual Studio 17 2022" -A x64 -S . -Bbuild/windows
cmake --build build/windows --config Release --target install
建置基础baker工具
1. 下载 BakerSample.rar 并解压缩至 D:\BakerSample。
2. 复制Opacity-MicroMap-SDK, math.h, glm 相关档案
- Opacity-MicroMap-SDK\build\windows\install\* 至D:\BakerSample
- Opacity-MicroMap-SDK\shared\shared\math.h 至 D:\BakerSample\shared\shared
- Opacity-MicroMap-SDK\thirdparty\glm\glm至D:\BakerSample\include
BakerSample ❸|- bin
|- omm-sdk.dll
|- include ❸ |- glm
|- detail
|- ...
|- tinygltf
|- CLI11.hpp ❸ |- omm.h ❸ |- omm.hpp ❸|- lib
|- omm-sdk.lib ❸|- shared
|- shared
|- math.h
|- CMakeLists.txt
|- ...
3. 使用CMake建置Visual Studio项目,产出执行档位于build\windows\install\bin\Baker.exe和Parser.exe。
cd BakerSample
cmake -G "Visual Studio 17 2022" -A x64 -S . -Bbuild/windows
cmake --build build/windows --config Release --target install
4. 使用baker测试范例数据。
Baker.exe -f path/to/data/ivy/Foliage_Ivy_leaf_a.DoubleSided.gltf
5. 使用parser检查输出文件格式,最后一行log为Success代表正确。
Parser.exe -f path/to/data/ivy/Foliage_Ivy_leaf_a.DoubleSided_lv7.omm
2.1.2 基础Baker工具实作细节
baker.cpp分为3部分
1. 使用CLI11提供接口需要的输入选项 (Table 2-2.)。
2. 使用tinygltf读取gltf模型的纹理坐标和索引坐标,与stb_image.h读取base color纹理的alpha (Table 2-1.)。此外,基础baker工具仅支持读取单一模型,且使用一张包含alpha的纹理。
3. 修改NVIDIA Opacity-MicroMap-SDK的tests/test_minimal_sample.cpp产生2-state OMM数据。
|
注意,OMM subdivision level统一的输入设定为maxSubdivisionLevel。 |
|---|
int main(int argc, char** argv)
{
// Step 1: CLI11输入选项
// Step 2: tinygltf读取模型
// Step 3
// 设定alpha纹理
omm::Cpu::TextureMipDesc mipDesc;
mipDesc.width = img_width;
mipDesc.height = img_height;
mipDesc.textureData = alphaTextureData.data();
omm::Cpu::TextureDesc texDesc;
texDesc.format = omm::Cpu::TextureFormat::UNORM8;
texDesc.mipCount = 1;
texDesc.mips = &mipDesc;
// 设定纹理坐标
bakeDesc.texCoordFormat = omm::TexCoordFormat::UV32_FLOAT;
bakeDesc.texCoordStrideInBytes = sizeof(float2);
bakeDesc.texCoords = texCoordBuffer.data();
bakeDesc.indexBuffer = indexBuffer.data();
bakeDesc.indexCount = vertex_indices;
bakeDesc.indexFormat = (index_format == 0) ? omm::IndexFormat::I16_UINT : omm::IndexFormat::I32_UINT;
bakeDesc.format = omm::Format::OC1_2_State;
bakeDesc.unknownStatePromotion = omm::UnknownStatePromotion::ForceOpaque;
// 设定输入选项
bakeDesc.maxSubdivisionLevel = max_subdivision_level;
bakeDesc.dynamicSubdivisionScale = dyn_subdivision_scale;
// 输出文件格式 (.omm)
uint32_t indexFormat = (bakeResultDesc->indexFormat == omm::IndexFormat::I16_UINT) ? 0 : 1;
std::string outputFolder = std::filesystem::path(filename).parent_path().string();
std::ofstream outputFile(outputFolder + "/" + std::filesystem::path(filename).stem().string() + "_lv" + std::to_string(max_subdivision_level) + ".omm", std::ios::out | std::ios::binary);
outputFile.write((char*)&bakeResultDesc->arrayDataSize, sizeof(uint32_t));
outputFile.write((char*)&bakeResultDesc->descArrayCount, sizeof(uint32_t));
outputFile.write((char*)&bakeResultDesc->descArrayHistogramCount, sizeof(uint32_t));
outputFile.write((char*)&bakeResultDesc->indexCount, sizeof(uint32_t));
outputFile.write((char*)&bakeResultDesc->indexHistogramCount, sizeof(uint32_t));
outputFile.write((char*)&bakeResultDesc->indexFormat, sizeof(uint32_t));
// ...
}
2.2 应用代码整合
2.2.1 开启OMM扩展
为使用OMM,在创建VkDevice前,在设定ray query (RQ) 相关扩展后,需开启VK_EXT_opacity_micromap 扩展
1. 将VK_KHR_SYNCHRONIZATION_2_EXTENSION_NAME和VK_EXT_OPACITY_MICROMAP_EXTENSION_NAME加入至需要启用的扩展。
std::vector<const char*> enabled_extensions;
enabled_extensions.push_back(VK_KHR_SYNCHRONIZATION_2_EXTENSION_NAME);
enabled_extensions.push_back(VK_EXT_OPACITY_MICROMAP_EXTENSION_NAME);
2. 将VkPhysicalDeviceOpacityMicromapFeaturesEXT中的micromap设定为VK_TRUE。
VkPhysicalDeviceOpacityMicromapFeaturesEXT
requested_gpu_features{VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_OPACITY_MICROMAP_FEATURES_EXT};
requested_gpu_features.micromap = VK_TRUE;
3. 设定VkDeviceCreateInfo中ppEnabledExtensionNames为需要启用的扩展,和pNext为VkPhysicalDeviceOpacityMicromapFeaturesEXT*。
VkDeviceCreateInfo ci{VK_STRUCTURE_TYPE_DEVICE_CREATE_INFO};
// ...
// 启用扩展
ci.ppEnabledExtensionNames = enabled_extensions.data();
// 启用 feature
ci.pNext = &requested_gpu_features;
4. 若无法找到vkCreateMicromapEXT等OMM相关device-level function,需先宣告PFN_vkCreateMicromapEXT 的变量再透过vkGetDeviceProcAddr赋予其值。
// 宣告于 .h
#define DEVICE_LEVEL_VULKAN_FUNCTION(name) extern PFN_##name name;
// 定义于 .cpp
#define DEVICE_LEVEL_VULKAN_FUNCTION(name) name = (PFN_##name)vkGetDeviceProcAddr(device, #name);
2.2.2 使用基础Baker输出建置OMM
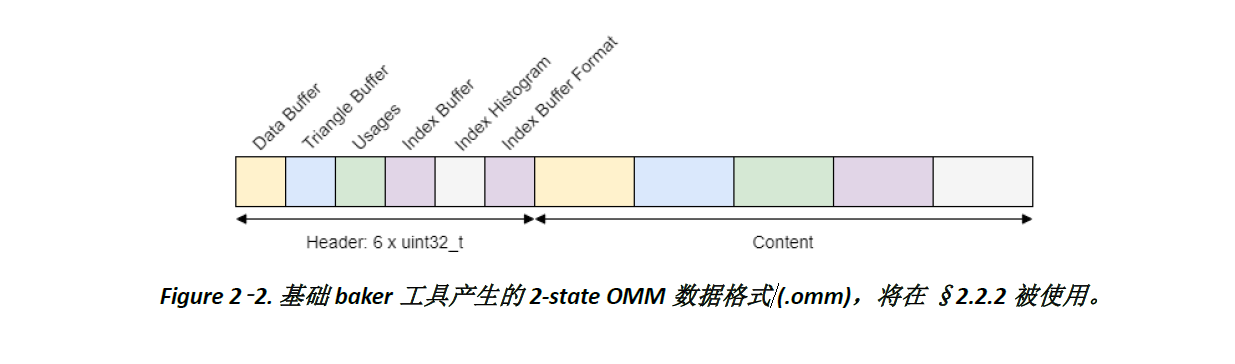
在呼叫Vulkan API建置OMM前,读取2-state OMM的数据报括data buffer, triangle buffer, usages和index buffer (§2.2.2.1),并在OMM相关API中使用这些数据来建置OMM (§2.2.2.2) 和BLAS (§2.2.3),如Figure 2-3.。

Figure 2‑3. 相同字母符号代表对应的2-state OMM数据与Vulkan API关系。图片来源: Ray Opacity Micromap。
流程如下:
1. 从Figure 2-2. 读取 §2.1.1描述的2-state OMM数据,并准备建置OMM需要的data buffer, triangle buffer和usages,并建置使用OMM的BLAS需要的index buffer,请见 §2.2.2.1。
void ReadOpacityMicromapData(vkb::Device& device, const std::string fname, OpacityMicromapData& omm_data) {
// 1. Load binary file
// 2. Read OMM header
// 3. Read data buffer
// 4. Read triangle buffer
// 5. Read usages
// 6. Read index buffer
}
2. 使用第一步读取的数据来建置OMM,请见 §2.2.2.2。
struct OpacityMicromapData {
uint32_t arrayDataSize;
// ...
} omm_data;
ReadOpacityMicromapData(device, "opacity_micromap/sponza_thorn_lv7.omm", omm_data);
OpacityMicromap opacity_micromap;
opacity_micromap->build(queue, omm_data->usages, omm_data->data_buffer, omm_data->triangle_buffer);
3. 使用第一步读取的数据来建置使用OMM的BLAS,请见 §2.2.3。
AccelerationStructure bottom_level_acceleration_structure(...);
bottom_level_acceleration_structure->add_triangle_geometry(..., omm_data, ...);
bottom_level_acceleration_structure->build(queue, ...);
2.2.2.1 读取OMM数据
为使用2-state OMM数据 (*.omm) 于后续的建置OMM和BLAS中,需解析档案中的数据。
1. 读取header以计算data buffer, triangle buffer, usages和index buffer大小以及型别。
std::vector<uint8_t> raw_data = read_binary(fname);
uint32_t* raw_data_ptr = reinterpret_cast<uint32_t*>(raw_data.data());
omm_data.arrayDataSize = raw_data_ptr[0];
omm_data.descArrayCount = raw_data_ptr[1];
omm_data.descArrayHistogramCount = raw_data_ptr[2];
omm_data.indexCount = raw_data_ptr[3];
omm_data.indexHistogramCount = raw_data_ptr[4];
omm_data.indexFormat = raw_data_ptr[5];
2. 读取data buffer,注意buffer usage须包含VK_BUFFER_USAGE_MICROMAP_BUILD_INPUT_READ_ONLY_BIT_EXT和VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT。
uint32_t offset = 6 * sizeof(uint32_t);
std::vector<uint8_t> arrayData(raw_data.data() + offset, raw_data.data() + offset + omm_data.arrayDataSize);
omm_data.data_buffer = std::move(setupBuffer(device, VK_BUFFER_USAGE_MICROMAP_BUILD_INPUT_READ_ONLY_BIT_EXT|
VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT, arrayData));
3. 读取triangle buffer。
struct MicromapTriangle {
uint32_t offset;
uint16_t subdivisionLevel;
uint16_t format;
};
offset += omm_data.arrayDataSize;
uint32_t descArraySize = omm_data.descArrayCount * sizeof(MicromapTriangle);
std::vector<uint8_t> descArray(raw_data.data() + offset, raw_data.data() + offset + descArraySize);
MicromapTriangle* descArrayPtr = reinterpret_cast<MicromapTriangle*>(descArray.data());
std::vector<VkMicromapTriangleEXT> triangles;
triangles.reserve(omm_data.descArrayCount);
for (uint32_t i = 0; i < omm_data.descArrayCount; ++i)
triangles.push_back({descArrayPtr[i].offset, descArrayPtr[i].subdivisionLevel,
descArrayPtr[i].format});
omm_data.triangle_buffer = std::move(setupBuffer(device,
VK_BUFFER_USAGE_MICROMAP_BUILD_INPUT_READ_ONLY_BIT_EXT |VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT, triangles));
4. 读取VkMicromapUsageEXT usages,注意此信息亦会在建置OMM和BLAS使用到,需保留至GPU建置完成,而非CPU执行至VK API。
struct MicromapUsage {
uint32_t count;
uint16_t subdivisionLevel;
uint16_t format;
};
offset += descArraySize;
uint32_t descArrayHistogramSize = omm_data.descArrayHistogramCount * sizeof(MicromapUsage);
std::vector<uint8_t> descArrayHistogram(raw_data.data() + offset, raw_data.data() + offset + descArrayHistogramSize);
MicromapUsage* descArrayHistogramPtr = reinterpret_cast<MicromapUsage*>(descArrayHistogram.data());
omm_data.usages.reserve(omm_data.descArrayHistogramCount);
for (uint32_t i = 0; i < omm_data.descArrayHistogramCount; ++i)
omm_data.usages.push_back({descArrayHistogramPtr[i].count,
descArrayHistogramPtr[i].subdivisionLevel, descArrayHistogramPtr[i].format});
|
GPU建置完成的定义为当command buffer经vkQueueSubmit后,透过带入的fence,以vkGetFenceStatus取得结过为VK_SUCCESS,而非command buffer录VK API时的执行,如vkCmdBuildMicromapsEXT,范例如下: |
|---|
// 非CPU执行至VK API
vkCmdBuildMicromapsEXT(command_buffer, 1, &build_info);
VkSubmitInfo submit_info{};
submit_info.commandBufferCount = 1;
submit_info.pCommandBuffers = &command_buffer;
// ...
VkFenceCreateInfo fence_info{};
fence_info.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
fence_info.flags = VK_FLAGS_NONE;
VkFence fence;
vkCreateFence(device, &fence_info, nullptr, &fence);
VkResult result = vkQueueSubmit(queue, 1, &submit_info, fence);
// vkGetFenceStatus(device, fence))) returns VK_NOT_READY
// GPU建置完成! 为了展示CPU等待GPU完成而使用vkWaitForFences
vkWaitForFences(device, 1, &fence, VK_TRUE, DEFAULT_FENCE_TIMEOUT);
// vkGetFenceStatus(device, fence))) returns VK_SUCCESS
5. 读取index buffer,并于最后检查档案与解析的大小相同,以验证正确性。
offset += descArrayHistogramSize;
uint32_t indexBufferSize = omm_data.indexCount * (omm_data.indexFormat == 0 ? sizeof(uint16_t) : sizeof(uint32_t));
std::vector<uint8_t> indexBuffer(raw_data.data() + offset, raw_data.data() + offset + indexBufferSize);
omm_data.index_buffer = std::move(setupBuffer(device, VK_BUFFER_USAGE_MICROMAP_BUILD_INPUT_READ_ONLY_BIT_EXT |
VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT, indexBuffer));
offset += indexBufferSize;
uint32_t indexHistogramSize = omm_data.indexHistogramCount * sizeof(MicromapUsage);
offset += indexHistogramSize;
assert(offset == raw_data.size());
2.2.2.2 建置OMM
由 §2.2.2.1的data buffer, triangle buffer和usages建置OMM。
1. 根据usages取得OMM大小。
VkMicromapBuildSizesInfoEXT build_sizes_info{VK_STRUCTURE_TYPE_MICROMAP_BUILD_SIZES_INFO_EXT};
VkMicromapBuildInfoEXT build_info{VK_STRUCTURE_TYPE_MICROMAP_BUILD_INFO_EXT};
build_info.mode = VK_BUILD_MICROMAP_MODE_BUILD_EXT;
build_info.flags = VK_BUILD_MICROMAP_PREFER_FAST_TRACE_BIT_EXT;
build_info.usageCountsCount = static_cast<uint32_t>(omm_data.usages.size());
build_info.pUsageCounts = omm_data.usages.data();
build_info.type = VK_MICROMAP_TYPE_OPACITY_MICROMAP_EXT;
vkGetMicromapBuildSizesEXT(device, VK_ACCELERATION_STRUCTURE_BUILD_TYPE_DEVICE_KHR, &build_info, &build_sizes_info);
2. 根据OMM大小创建handle buffer,然后使用该buffer创建OMM。
// 创建handle buffer
VkBuffer handle_buffer = CreateBuffer(VK_BUFFER_USAGE_MICROMAP_STORAGE_BIT_EXT, build_sizes_info.micromapSize);
// 创建OMM
VkMicromapEXT omm_handle;
VkMicromapCreateInfoEXT mm_create_info{VK_STRUCTURE_TYPE_MICROMAP_CREATE_INFO_EXT};
mm_create_info.buffer = handle_buffer;
mm_create_info.size = build_sizes_info.micromapSize;
mm_create_info.type = build_info.type;
VkResult result = vkCreateMicromapEXT(device, &mm_create_info, nullptr, &omm_handle);
3. 根据OMM大小创建scratch buffer,然后使用该buffer建置OMM。
// 创建scratch buffer
VkBuffer scratch_buffer = CreateBuffer(VK_BUFFER_USAGE_MICROMAP_STORAGE_BIT_EXT |
VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT, build_sizes_info.buildScratchSize);
// 建置OMM
build_info.dstMicromap = omm_handle;
build_info.scratchData.deviceAddress = GetDeviceAddress(scratch_buffer);
build_info.data.deviceAddress = GetDeviceAddress(omm_data.data_buffer);
build_info.triangleArray.deviceAddress = GetDeviceAddress(omm_data.triangle_buffer);
build_info.triangleArrayStride = sizeof(VkMicromapTriangleEXT);
vkCmdBuildMicromapsEXT(command_buffer, 1, &build_info);
4. 建置OMM,注意需要与使用该OMM的BLAS之间设置barrier同步。
VkMemoryBarrier2 barrier{};
barrier.sType = VK_STRUCTURE_TYPE_MEMORY_BARRIER_2;
barrier.srcAccessMask = VK_ACCESS_2_MICROMAP_WRITE_BIT_EXT;
barrier.dstAccessMask = VK_ACCESS_2_MICROMAP_READ_BIT_EXT | VK_ACCESS_2_MICROMAP_WRITE_BIT_EXT;
barrier.srcStageMask = VK_PIPELINE_STAGE_2_MICROMAP_BUILD_BIT_EXT | VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT;
barrier.dstStageMask = VK_PIPELINE_STAGE_2_MICROMAP_BUILD_BIT_EXT | VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT;
VkDependencyInfo dep_info{};
dep_info.sType = VK_STRUCTURE_TYPE_DEPENDENCY_INFO;
dep_info.memoryBarrierCount = 1;
dep_info.pMemoryBarriers = &barrier;
// 或使用vkCmdPipelineBarrier2
vkCmdPipelineBarrier2KHR(command_buffer, &dep_info);
|
5. 当程序结束前,释放OMM。 |
|---|
vkDestroyMicromapEXT(device, omm, nullptr);
2.2.3 建置使用OMM的BLAS
由 §2.2.2.1的index buffer和 §2.2.2.2的OMM建置BLAS。
1. 准备BLAS中需要使用OMM的geometry信息 (VkAccelerationStructureTriangleOpacityMicromapEXT),注意此信息需保留至GPU建置完成,而非CPU执行至VK API。
VkAccelerationStructureTrianglesOpacityMicromapEXT mmi{};
mmi.sType = VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_TRIANGLES_OPACITY_MICROMAP_EXT;
// 依据范例baker输出的index型别决定
mmi.indexType = (omm_data.indexFormat == 0) ? VK_INDEX_TYPE_UINT16 : VK_INDEX_TYPE_UINT32;
mmi.indexBuffer.deviceAddress = GetDeviceAddress(omm_data.index_buffer);
mmi.indexStride = (omm_data.indexFormat == 0) ? sizeof(uint16_t) : sizeof(uint32_t);
// 因目前范例baker的OMM只包含一个几何对象,故不会使用
mmi.baseTriangle = 0;
mmi.micromap = omm_handle;
// 注意! 若BLAS中有多个geometry使用不同OMM,需个别保留对象至建置完成
mmi.usageCountsCount = static_cast<uint32_t>(omm_data.usages.size());
mmi.pUsageCounts = omm_data.usages.data();
2. 将该OMM 信息加入至geometry后建置BLAS,注意需要与依赖此BLAS的资源或指令设置barrier。
std::vector<VkAccelerationStructureGeometryKHR> geometries;
VkAccelerationStructureGeometryKHR geometry{};
geometry.sType = VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_GEOMETRY_KHR;
// ...
// 注意! mmi必须保留至建置完成后才可释放
geometry.geometry.triangles.pNext = &mmi;
geometries.push_back(geometry);
// 其余与原本AS处理相同
VkAccelerationStructureKHR blas;
VkAccelerationStructureBuildGeometryInfoKHR build_geometry_info{};
build_geometry_info.sType = VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_BUILD_GEOMETRY_INFO_KHR;
build_geometry_info.pGeometries = geometries.data();
// ...
build_geometry_info.dstAccelerationStructure = blas;
vkCmdBuildAccelerationStructuresKHR(..., &build_geometry_info, ...);
// ...
vkCmdPipelineBarrier(...);
2.2.4 RQ Shader自动启用OMM效果
只需更改原本shader中的一行代码,即可对 §2.2.3中使用OMM的BLAS进行求交。
1. 启用GLSL中的GL_EXT_opacity_micromap扩展,并将其转换成符合SPIR-V 1.4的格式 (SPV_EXT_opacity_micromap)。
#extension GL_EXT_opacity_micromap : enable
2. 其余部分不需要额外改动,在opaque下可以直接取得2-state OMM求交结果。
rayQueryEXT rq;
rayQueryInitializeEXT(rq, TLAS,
// 当效果需取得最近的求交,如反射,移除ray flags中的gl_RayFlagsTerminateOnFirstHitEXT
gl_RayFlagsTerminateOnFirstHitEXT | gl_RayFlagsSkipAABBEXT,
cullMask, origin, tMin, direction, tMax);
rayQueryProceedEXT(rq);
if (rayQueryGetIntersectionTypeEXT(rq, true) == gl_RayQueryCommittedIntersectionNoneEXT) {
// Not shadow!
}
else {
// Shadow!
}
2.2.5 节省不须OMM效果的Pipeline
为了提升不使用OMM效果的pipeline效能
1. 将VK_ARM_pipeline_opacity_micromap加入至需要启用的扩展。
// #define VK_ARM_PIPELINE_OPACITY_MICROMAP_EXTENSION_NAME "VK_ARM_pipeline_opacity_micromap"
enabled_extensions.push_back(VK_ARM_PIPELINE_OPACITY_MICROMAP_EXTENSION_NAME);
2. 透过VkPipelineCreateFlags2CreateInfoKHR将VK_PIPELINE_CREATE_2_DISALLOW_OPACITY_MICROMAP_BIT_ARM加入至vkCreateGraphicsPipelines,以提升不使用OMM效果的pipeline效能。注意,若使用pipeline cache,需建立新的。
// static const VkPipelineCreateFlagBits2KHR VK_PIPELINE_CREATE_2_DISALLOW_OPACITY_MICROMAP_BIT_ARM = 0x2000000000ULL;
VkPipelineCreateFlags2CreateInfoKHR pipeline_create_flags_info{};
pipeline_create_flags_info.sType = VK_STRUCTURE_TYPE_PIPELINE_CREATE_FLAGS_2_CREATE_INFO_KHR;
pipeline_create_flags_info.flags = VK_PIPELINE_CREATE_2_DISALLOW_OPACITY_MICROMAP_BIT_ARM;
pipeline_create_info.pNext = &pipeline_create_flags_info;
vkCreateGraphicsPipelines(device.get_handle(), VK_NULL_HANDLE, 1, &pipeline_create_info, nullptr, &pipeline);
3. 常见问题
- OMM与alpha 纹理坐标、模型索引相关,若无改变,不须更新OMM。
- 2-state OMM大小计算公式为2^(2 * subdivision level) / 8 (byte)。以暗区突围为例,最大值为0.4MiB (约310个OMM三角形)。
3. 为什么vkGetMicromapBuildSizesEXT回传的micromapSize过大 (~0.1 PB)?
- 可能因为VkMicromapUsageEXT设置型别错误导致解读差异,如subdivisionLevel正常值小于12,但变成4,261,281,277,而遇到OUT_OF_DEVICE_MEMROY。请检查OMM baker输出的结构数组 (如Table 3-1. 左) ,subdivisionLevel与format型别须为uint32_t,才能直接将数组指针转型为VkMicromapUsageEXT* 用作VkMicromapBuildInfoEXT中的pUsageCounts,否则若将两个16位解读为一个32位,可能产生异常大的数值。
Table 3‑1. Baker与Vulkan API的变数型别不同。
|
struct MyMicromapUsage { uint32_t count; uint16_t subdivisionLevel; uint16_t format; }; |
typedef struct VkMicromapUsageEXT { uint32_t count; uint32_t subdivisionLevel; uint32_t format; } VkMicromapUsageEXT; |
|---|
4. 为什么建置使用OMM的BLAS遇到vkCmdBuildAccelerationStructuresKHR崩溃?
- 可能因为VkAccelerationStructureTrianglesOpacityMicromapEXT设置 (indexType, indexStride) 不合法导致存取错误。若使用 index buffer,请检查正确的组合为 (VK_INDEX_TYPE_UINT32, 4) 和 (VK_INDEX_TYPE_UINT16, 2)。
- 可能因为API参数pNext为null指标导致存取错误,在桌机上会遇到accelerationStructureSize为0或hang住。请检查VkAccelerationStructureGeometryTrianglesDataKHR的pNext,和BLAS使用的VkAccelerationStructureTrianglesOpacityMicromapEXT中pUsageCounts,使用的变量须保留至GPU建置完成,而非CPU执行至VK API,否则也可能遇到BLAS中缺少部分OMM,如Figure 3-1.。
5. 为什么OMM baker的输出结果与模型纹理不一致?
- 可能因为baker和raster使用的资料不同。请检查 baker 使用的模型索引和纹理坐标,须与raster使用的数据相同。
- 可能因为fbx和gltf格式转换时更动了坐标系统。请检查baker使用的gltf与引擎使用的fbx中,模型索引和纹理坐标必须相同。
6. 为什么vkGetDeviceProcAddr回传vkCmdPipelineBarrier2为NULL?
4. 最佳实务
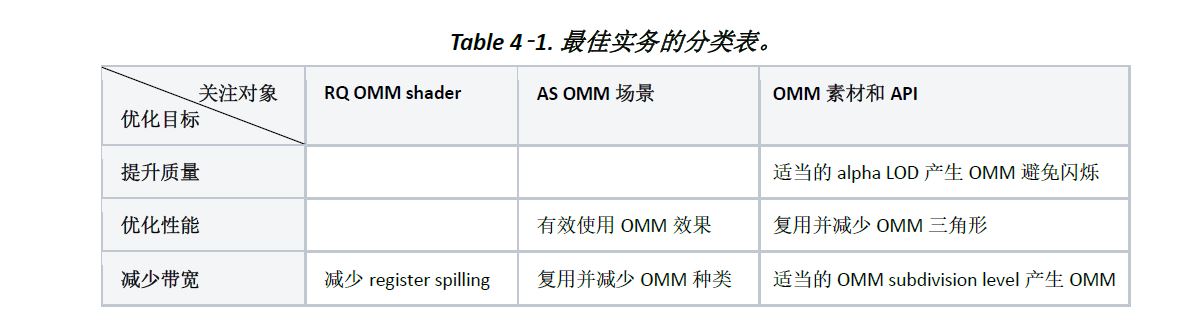
最佳实务对API和内容依优化目标和关注对象分类如Table 4-1.,请根据符合优化目标的问题,改善关注对象。
4.1 提升质量
4.1.1 避免产生OMM的Alpha纹理LOD过低 (分辨率过高)
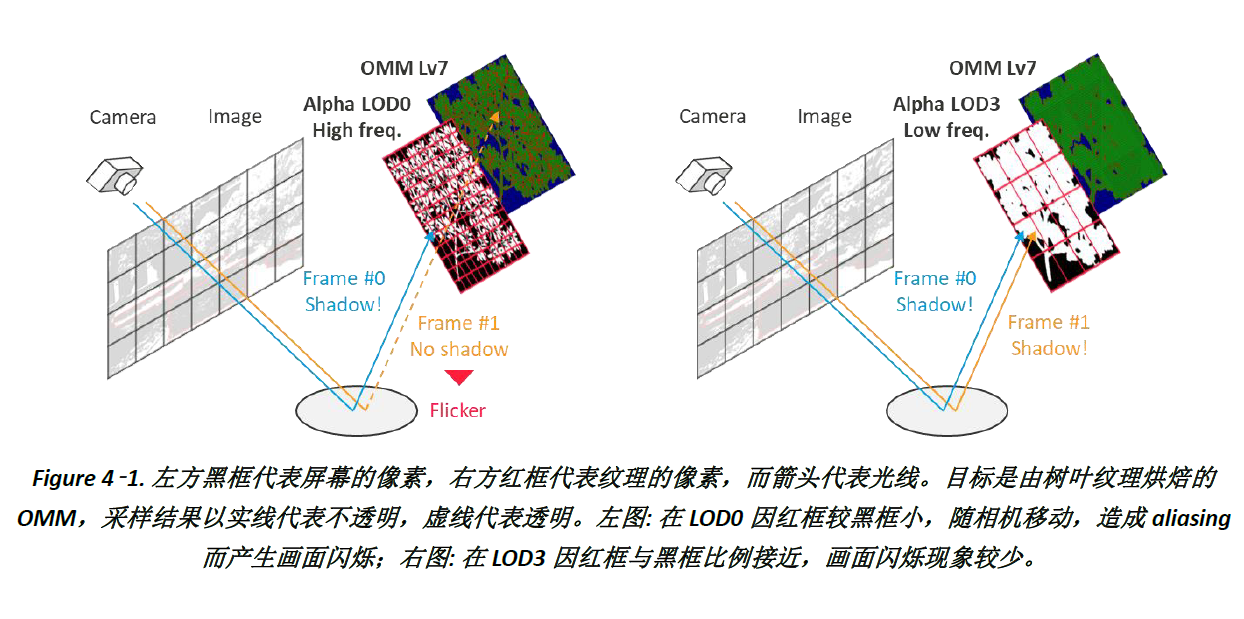
当移动时硬阴影出现闪烁,可能是由于采样OMM不足导致的aliasing (Figure 4-1.),建议首先增加产生OMM的alpha纹理LOD,如同mipmap,通过预先采样 (pre-filtering) 不同距离下的高频纹理,选择合适LOD的纹理 (Figure 4-1. 红框) 和屏幕 (Figure 4-1. 黑框) 像素占比,而非调整OMM subdivision level来减缓闪烁 (Figure 4-2.)。

4.2 提升性能
4.2.1 节省植被的数量和层数
可以在植被的数量或层数增加时有效控制GPU actives的增长,以减少求交测试 (Figure 4-3.)。此外,透过AS culling调整效果对象的数量,以平衡性能和阴影效果。
植被使用的数量和层数受到不同的阴影画面和光追分辨率影响,可以透过Streamline的Non-opaque triangle hit和Rays started等指标评估OMM和光追的工作量。以暗区突围为例,TLAS中使用OMM的instance数量约为20仍可符合游戏使用。

例如,数量从5增加至10~15时,对GPU actives增加12~54%,在Streamline可以观察,Started rays相同,而需要的intersection test (box nodes, triangle batches) 亦增加11~53% (基于内部测试机型),如Table 4-2.。
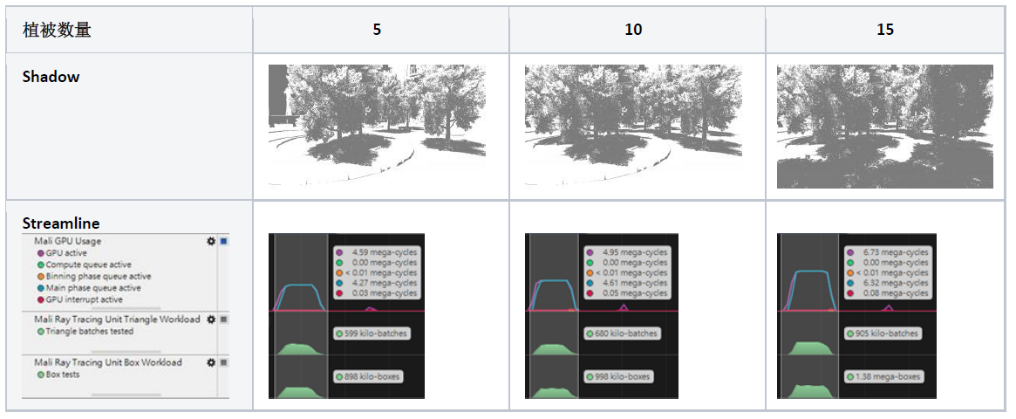
而层数从1增加至10时,以closest hit测试,对GPU actives增加135%。在Streamline可以观察,Started rays相同,而需要的Box nodes tested和Non-opaque triangle hit增加150%,如Table 4-3.。

4.2.2 节省OMM三角形的数量
缩短建置OMM时间,可以透过复用模型三角形的纹理坐标,减少OMM三角形数量来达成。例如,max subdivision level 7 (参考 §2.1 OMM baker的设定) 在1 ms建置时间预算下可用约60个OMM三角形,实际数值依游戏素材而变。另外,在1 MiB大小预算下,可用约600个OMM三角形 (基于内部测试机型)。
例如,Figure 4-4. 为不好的案例,因为每面使用不同的纹理坐标,使得OMM三角形数量与面数相同为306。
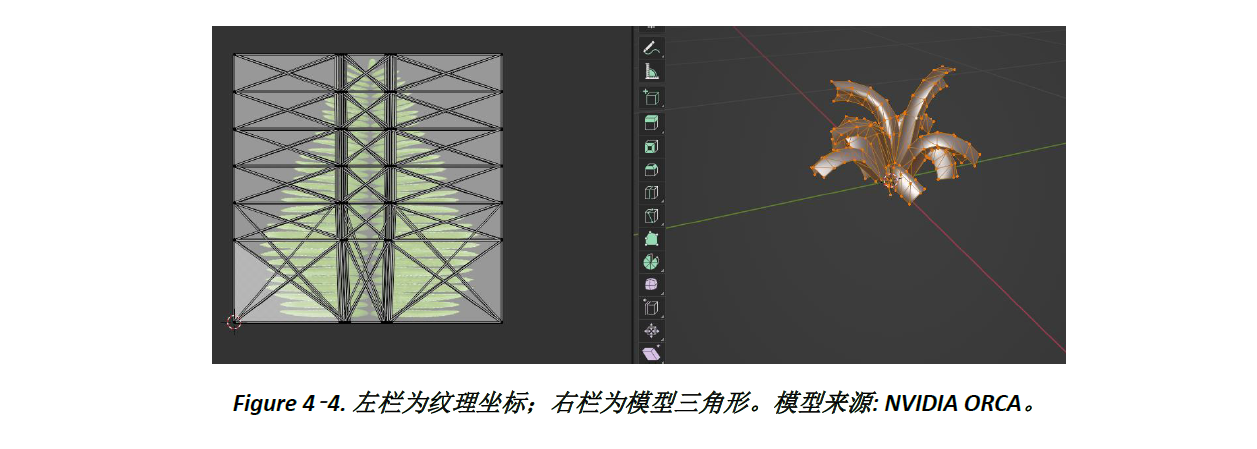
而好的案例为Figure 4-5., 988面模型三角形皆复用2组纹理坐标,使得平均每个OMM三角形对应的模型三角形数量 (Avg Tris per Micromap) 从1提升至494。这个指标值越大,表示OMM三角形复用度越好。

4.3 降低带宽
4.3.1 减少RQ Shader的Register Spilling
仅减少光线采样数量并不一定能节省整体pass带宽,建议比较不同shader实作,以找到最佳平衡,因为register spilling会导致存不下缓存器的数据写入L/S,需要时再读回,进而增加带宽,可以结合指标L/S带宽和GPU actives评估。
在范例场景,透过减少RQ shader的计算或采样光线的条件,可以使带宽减少53% (基于内部测试机型),但阴影光线采样数增加30%, 导致GPU active增加7% (Table 4-4.),需要依游戏的目标FPS和BW 预算实验,以找到频率和带宽的最佳平衡。
Table 4‑4. 比较不同shader实作, Started rays减少0.21M,带宽增加175.51 MiB,须结合两者指标评估。
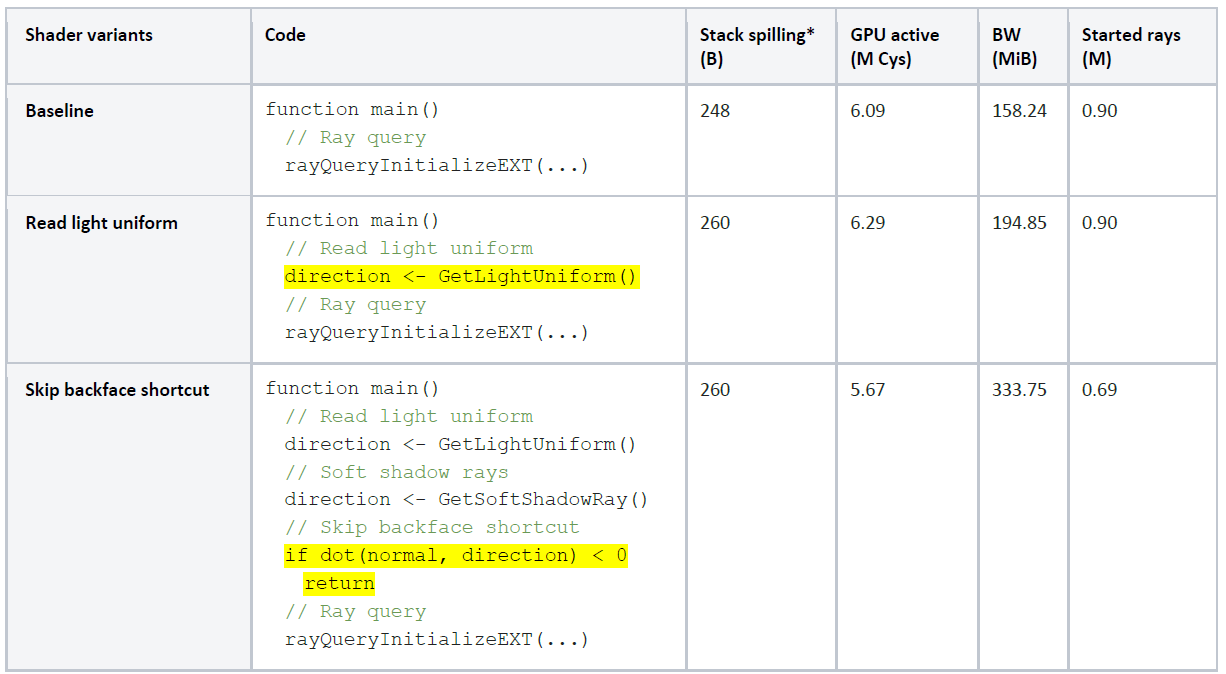
*由于malioc v8.1不包含OMM信息,影响stack spilling等静态分析结果。
在Streamline可以观察,光追带宽的主要组成来自L/S,读取L/S占 > 80%,而简化shader可以降低L2, External L/S read和L/S write的带宽 (Figure 4-6.)。
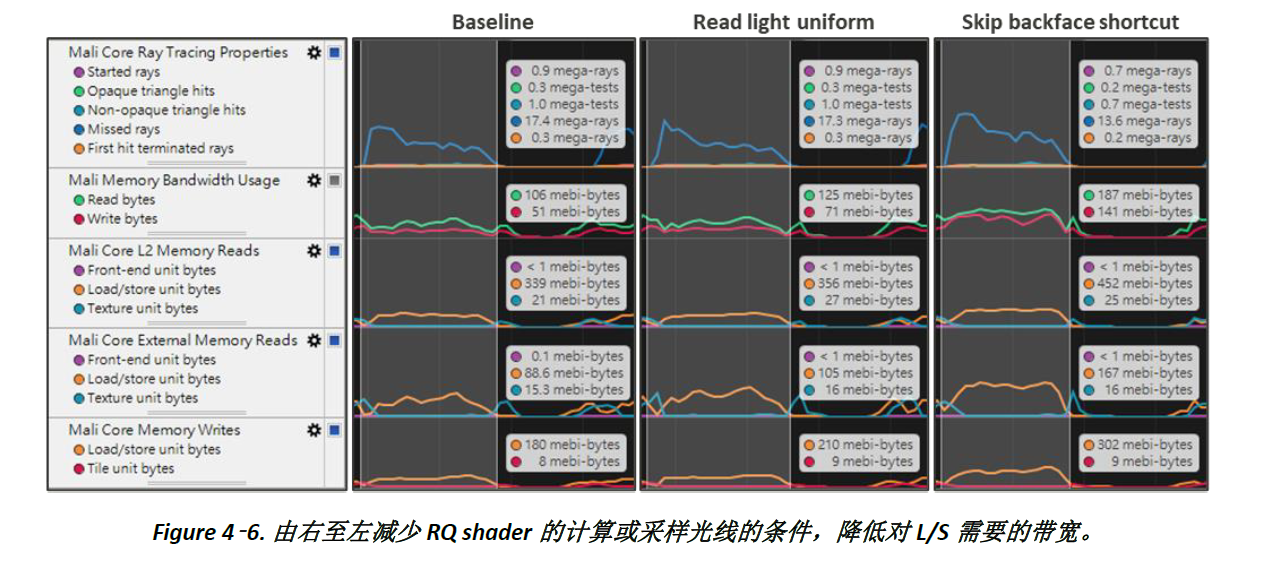
以暗区突围为例,当 RQ shader不考虑阴影背面,且AO只在阴影中使用时 (Figure 4-7.),光追带宽减少 ~50% (~30 MiB),但光线数量增加35% (0.13 M),导致fragment actives增加 ~11% (~0.5M),须评估两者的影响。

4.3.1 复用BLAS中的OMM
1. 避免BLAS使用多余的OMM,复用具有相同纹理坐标和alpha纹理的植被BLAS中的OMM,如Figure 4-8.
2. 透过调整albedo纹理的颜色变化,并共享相同的alpha纹理,可再减少RT场景中所需的不同OMM

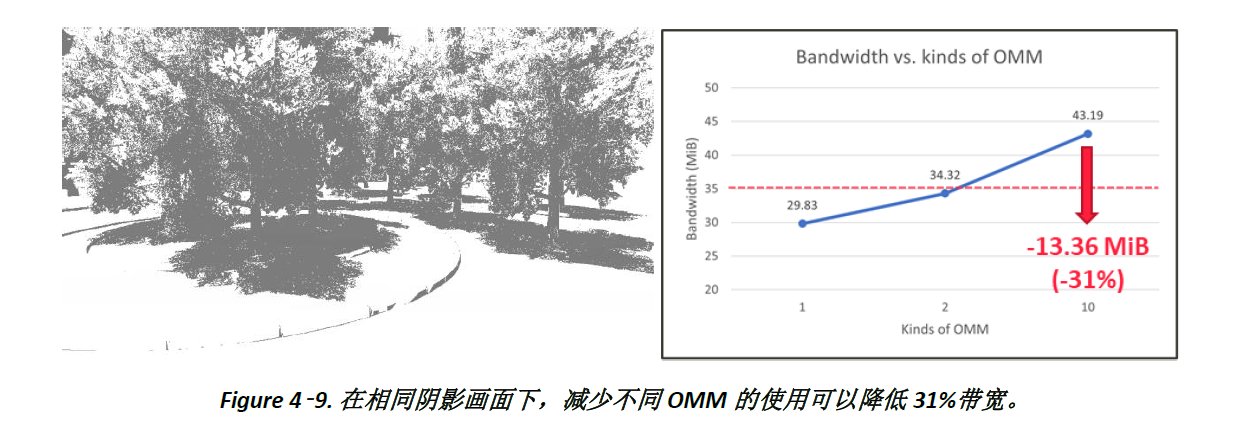
例如,对于视角内相同数量植被下的阴影画面 (Figure 4-9. 左),将不同的OMM从10减少至1种,可以降低L2 L/S miss rate,进而减少31% 带宽 (Figure 4-9. 右)。
在Streamline可以观察,当复用10种OMM时,Non-opaque triangle hit代表OMM的工作量和L2 L/S read接近,但External L/S read减少达8 MiB (基于内部测试机型),代表L2 L/S miss rate (= External / L2 * 100) 减少5% (Figure 4-10.)。

以暗区突围为案例,带宽降低的程度会受到不同的阴影画面和光追分辨率影响,并以Streamline的Non-opaque triangle hit评估OMM的工作量。调整 OMM 种类和与对应的数量 (Figure 4-11.),对External L/S read减少 ~3 MiB,和Non-opaque triangle hit 减少 0.16 M。此外,在相同BW 预算下,可使用的OMM种类也会依游戏设定而调整。

4.3.3 避免OMM Subdivision Level过高
OMM subdivision level过高会导致带宽增加,为了在维持相似阴影质量的同时减少带宽,建议降低OMM baker (§2.1) 的max subdivision level设定,以降低生成的subdivision level。
例如,将2-state OMM的subdivision level 从9降低至7,OMM大小减少16 (2^4) 倍,如从32 KiB 减少至2 KiB,可以使光追阴影效果的带宽减少 45% 和GPU actives减少16% (基于内部测试机型),而在Streamline可以观察,Started rays代表需要的光线采样数相同,但L2 L/S read下降,和External L/S read减少60% (Table 4-5.)。

以暗区突围为案例, 在最大subdivision level为7就能呈现出竹林阴影的细节 (Figure 4-12.)。




