3. Getting Started Guide
3.1 NeuroPilot Workflow
This section helps developers understand the NeuroPilot development process.
3.1.1 NeuroPilot Overview
NeuroPilot is a collection of software tools and APIs that allow users to create AI applications, based on neural network models, for MediaTek hardware platforms. With NeuroPilot, users can develop and deploy AI applications on edge devices with extremely high efficiency, while also keeping data private.
3.1.1.1 NeuroPilot Key Features
- NeuroPilot’s run-time software allows any TensorFlow Lite (.tflite) model to run on a NeuroPilot-compatible MediaTek platform. This capability is guaranteed by TensorFlow Lite and the Mediatek run-time layers that support it.
- NeuroPilot allows users to tune and optimize neural networks for latency and size, beyond what is offered by open framework tools. This can result in large gains in on-device performance, and reductions in power and memory consumption.
- NeuroPilot allows users to profile a neural network running on a target device. Users can use this capability to fine-tune their networks based on hardware device behavior.
- NeuroPilot offers support for bare-metal application programming on Linux devices. This allows for minimal overheads during run-time, which is important for embedded devices.
3.1.2 General Workflow
- Model Preparation: The user starts with a trained neural network model. This model includes the model definition (structure), and a set of model parameters as 32-bit floating-point (FP32) data. This is typically the final step of the training process.
- Model optimization: The user optimizes the model using one or more NeuroPilot tools. These tools take the trained model from the previous step and produce a more lightweight and optimized representation for MediaTek platforms. This process may involve several steps, and is dependent on the development worflow and target device. The resulting model is stored as a TensorFlow Lite (.tflite) or Deep Learning Archive (.dla) file.
- Model deployment: The optimized model is loaded at run-time on the target device. At run-time, the model may use one or more device SDK libraries and APIs. Certain neural-network operations (ops) have platform-specific limitations. For a list of supported operations for each hardware platform, see the platform’s documentation at section: NeuroPilot Introduction and Platform Specification -> 2. Hardware Support Specification.
NeuroPilot supports the following platform-specific development workflows.
- Android Development: The user wants to develop an AI app, AI platform features, or an AI framework, on a MediaTek device running Android.
- embedded_linux_development: The user wants to deploy a neural network model on an embedded MediaTek device running Linux.
3.1.3 Android Development Workflow
This section describes the process for developing AI applications on MediaTek platforms running Android.
- MediaTek supports Google Tensorflow Lite’s standard AI model development workflow on mobile platforms, including model conversion, optimization, interpretation, and inference on Android mobile platforms. For details, see https://www.tensorflow.org/lite.
- MediaTek also provides the NeuroPilot SDK, which includes tools, APIs, and an on-device software stack (MTK Neuron SW). NeuroPilot SDK includes all of the features of Google TensorFlow Lite, while also offering more flexibility and better performance.
3.1.3.1 NeuroPilot Architecture
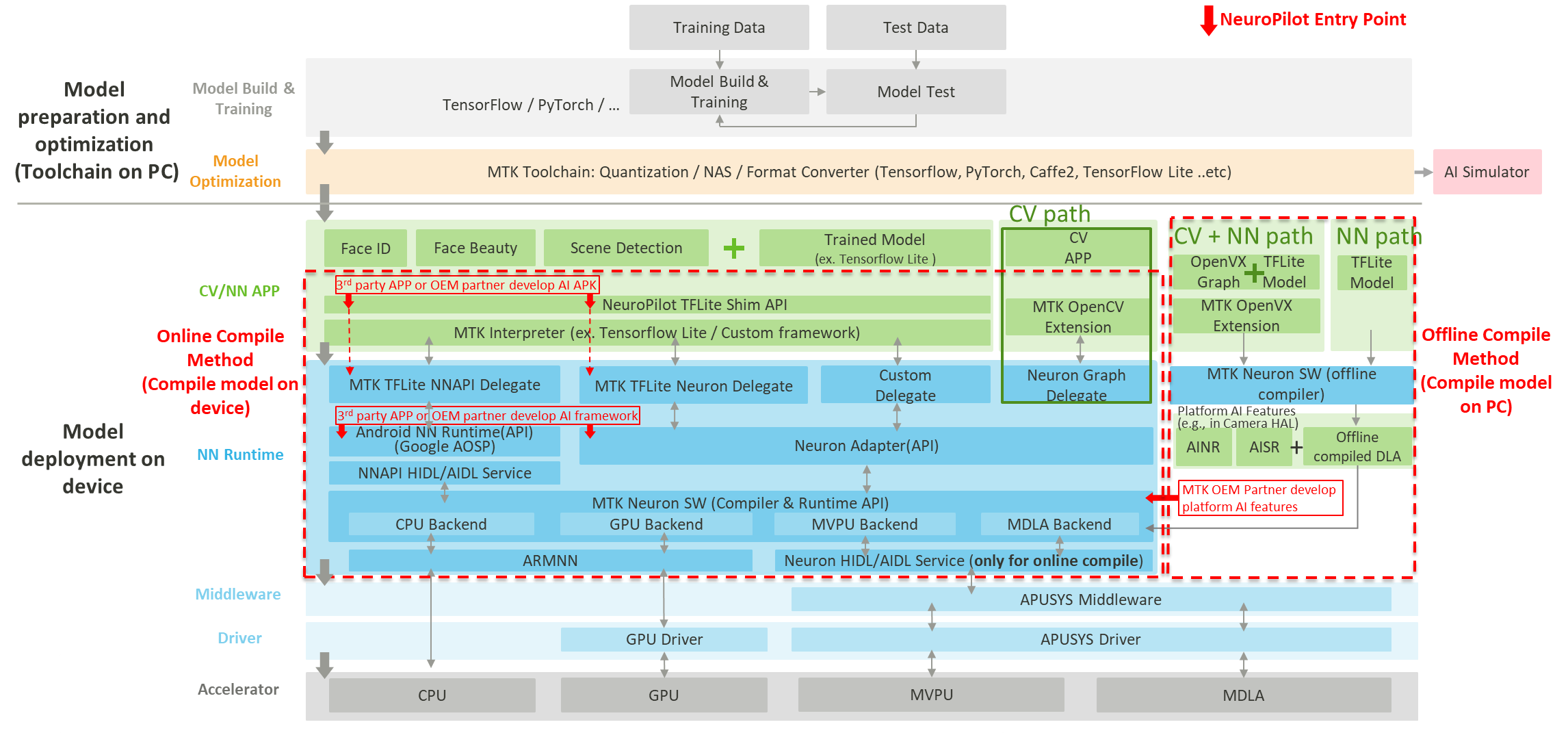
Figure: NeuroPilot Architecture
3.1.3.1.1 Development Phases
There are general two development phases, as shown in Figure: NeuroPilot Architecture.
Phase 1: Model preparation and optimization (PC)
- Prepare a trained model.
- Optimize the trained model.
- Convert the optimized model to TensorFlow Lite (TFLite) format.
Phase 2: Model deployment (Device)
- Select the appropriate model deployment method. For details, see section: Developer Roles and Model Deployment Methods.
- Select the appropriate software integration entry point. For details, see section: NeuroPilot Entry Points.
3.1.3.1.2 NeuroPilot Android Software Stack
The NeuroPilot Android Software Stack is composed of the following layers, as shown in Figure: NeuroPilot Architecture:
- CV/NN APP: This layer contains the code that the user writes to run the AI application. This layer also includes the MTK Interpreter, which is a MediaTek-APU-optimized version of the Android TensorFlow Lite interpreter, and TFLite Shim API, which is a wrapper layer on top of MTK Interpreter designed to make API calls simpler.
- NN Runtime: This layer contains run-time libraries that provide neural network acceleration, including Google Neural Network API (NNAPI), and MediaTek Neuron compiler/runtime.
- Middleware: This layer allows dynamic control over MediaTek AI compute cores. Quality-of-Service controls for running neural network workloads go here.
- Driver: This layer provides Android drivers for the special-purpose MediaTek AI compute cores.
3.1.3.1.3 NeuroPilot Entry Points
NeuroPilot Entry Points, shown in Figure 1 - NeuroPilot Architecture in red, represent the different AI model software integration entry points that developers can choose from. See section: NeuroPilot Entry Points.
3.1.3.2 Developer Roles and Model Deployment Methods
Before starting to integrate the converted TFlite AI model into an AI application, users need to select a model deployment method. The development method is based on the user’s developer role and development goal.

Figure: Developer Roles and Model Deployment Methods
3.1.3.2.1 Developer Roles
- 3rd-Party App Vendor: An Android application vendor, that is not Google or an OEM. Includes academic apps.
- 3rd-Party Algorithm Vendor: A company that partners with an OEM or 3rd-Party App Vendor to provide an AI algorithm solution.
- OEM: A manufacturer that develops mobile phones based on a MediaTek hardware platform (SOC, system-on-a-chip).
3.1.3.2.2 Model Deployment Method
- Description: The model is in Tensor Flow Lite format, or in a code-based format defined using the NNAPI or Neuron Adapter API. The application loads and then compiles the model to DLA(Deep Learning Archive) format on the device. This process should be platform independent; an AI application can load and then compile the same model on multiple MediaTek platforms. Users can also utilize the same model in multiple AI projects.
- Advantages
- MediaTek platform independent
- Neuron software version independent
- Customer project independent
- Disadvantages
- Initial latency (can be improved by caching)
- HIDL overhead
- Summary: Best for portability
- Description: The TFLite model is compiled to DLA format on the user’s computer. The AI application loads the DLA file directly on the device, and can immediately start inference. The DLA file is compiled for use on only one specific MediaTek platform.
- Advantages
- Low initial latency
- No HIDL overhead
- Disadvantages
- MDLA hardware version dependent
- Neuron software version dependent
- Summary: Best for performance
3.1.3.2.3 Developer and Model Deployment Methods Mapping
The following table maps developer types and purpose(or goals) to deployment methods and NeuroPilot entry points.
|
Role |
Development Goal |
NeuroPilot Entry Point |
AI Application Location |
Deployment Method |
Notes |
|
OEM |
APK with AI features |
|
System partition |
Online |
|
|
AI framework |
|
System partition |
Online |
|
|
|
Platform AI features (e.g. in camera HAL) |
|
Vendor partition |
Offline |
|
|
|
3rd-Party App Vendor |
APK with AI features |
|
System partition |
Online |
|
|
AI framework |
|
System partition |
Online |
|
|
|
3rd-Party Algorithm Vendor |
Choice of AI model deployment path depends on the requirements of the algorithm vendor’s partner (OEM or 3rd-party app vendor) |
|
Note: |
|
AI Application Location refers to the location of the final executable application. The concept of system and vendor partitions comes from Android VNDK. For more details, see https://source.android.com/docs/core/architecture/vndk. The partitions are controlled by Android Linker. The system and vendor partitions contain the following paths:
For more details about the Android Iinker, see https://source.android.com/docs/core/architecture/vndk/linker-namespace |
3.1.3.3 Android Development Workflow

Figure: Android Development Workflow
|
Note: |
|
3.1.3.3.1 Step 1: Model Preparation
- Prepare a trained PyTorch, TensorFlow, or Caffe AI model.
- Install NeuroPilot tools. See section: NeuroPilot Installation and Setup.
3.1.3.3.2 Step 2: Model Optimization
Optimize your AI model by following the steps below.
- (Optional) Neural Architecture Search (MLKits, Premium only): NAS automatically searches for the optimal network architecture and can achieve higher model quality. See MLKitNAS. MLKits can perform NAS with optional pruning and quantization.
- (Optional) Model quantization: Quantization is a model optimization technique that converts floating-point model data into lower-bit unsigned or signed integers. Quantization offers both model compression and performance improvements with a negligible loss in output quality, by taking advantage of the integer-only operator implementation on MediaTek platforms. NeuroPilot offers two methods of quantization:
- Quantization-aware training (Quantization Tool): Higher quantization accuracy for precision-sensitive scenarios. This method is more complex, as users are required to construct a pipeline for model training. See section: Developer Tools ->Model Development ->Quantization.
- Post-training quantization (Converter Tool): Lower quantization accuracy, for scenarios that are not sensitive to accuracy. Simpler to use than quantization-aware training. See section: Developer Tools ->Model Development -> Converter: Post-Training Quantization.
- Model Conversion (Converter Tool): Convert the target model to TFlite format for deployment. See section: Developer Tools ->Model Development -> Converter.
- (Optional) Device simulation (AI Simulator): Users without a physical device can use AI Simulator to evaluate the performance of the AI model on a specific MediaTek platform. See AISimulator.
5a. (Required for Online Compile) On-device model compatibility check and performance evaluation (Neuron Compiler, NNBenchmark):
- Check that the model is compatible with the target platform’s APU using Neuron Compiler(ncc-tflite) with command ncc-tflite {filename} --arch {target architecture} --check-target-only. See section: Developer Tools ->Model Development ->Neuron SDK: Neuron Compiler and Runtime.
- Evaluate the performance of the model on a real device using the NNBenchmark Demo provided by MediaTek. See section: Getting Started Guide-> Hello World Tutorial -> Java TFlite Tutorial and section: Getting Started Guide-> Hello World Tutorial -> C++ TFlite Tutorial.
5b. (Required for Offline Compile) Offline model compilation, performance evaluation, and optimization (Neuron SDK): Compile the model to DLA format using Neuron Compiler (ncc-tflite), and then evaluate performance on a real device using using Neuron Runtime Profiler. See NeuronProfiler. Users can also perform additional optimization workflows, such as TCM, GNO, and Compiler Custom API, using Neuron SDK. See section: Developer Tools ->Model Development ->Neuron SDK.
3.1.3.3.3 Step 3. Model Deployment
1. Model Deployment with Online Compile
Users can deploy AI models (Tflite) in their code using one of the following entry points.
- TFLite Shim API + Neuron Delegate
- TFLite Shim API + NNAPI Delegate
For details, see section: Developer Tools ->Application Development -> TFLite Shim API.
2. TFLite Neuron Delegate vs. TFLite NNAPI Delegate
MediaTek recommends using Neuron Delegate, for the following reasons.
- Better performance because of fewer software layers.
- Better flexibility:
- Neuron Delegate allows the user to create and use custom APIs.
- Neuron Delegate allows the user to create custom operations (ops) that are not in the TensorFlow Lite built-in ops.

Figure: TFLite Neuron Delegate vs. TFLite NNAPI Delegate
3. Model Deployment with Offline Compile
The user uses Neuron Runtime API to deploy a DLA AI model in the vendor partition, in order to provide platform AI features such as in the Camera HAL.
For details, see section: Developer Tools ->Model Development ->Neuron SDK: Neuron Runtime API .
3.1.3.4 Custom AI Framework Based on NeuroPilot
This section is for users who want to use NeuroPilot to develop a custom AI Framework, similar to Paddle Lite or MACE, for a MediaTek platform.
3.1.3.4.1 Development Overview
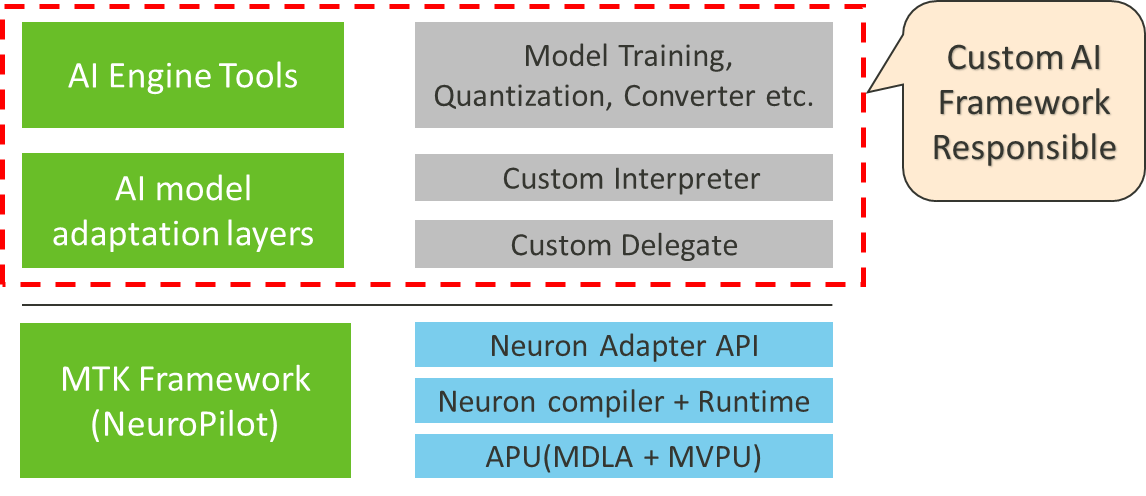
Figure: AI Custom Framework
- The user is responsible for the development and maintenance of AI engine tools and AI model adaptation layers, as shown in Figure 3 - AI Custom Framework.
- Developers should use Neuron Adapter API to develop the custom AI framework. For details, see section: Developer Tools ->Application Development -> Neuron Adapter API.
- To maximize the energy efficiency of the custom AI framework, hardware platform features must be adapted such as:
- APU operator restrictions
- Operator fusion rules
- Compiler optimization parameters
3.1.3.4.2 Development Workflow
The typical Neuron Adapter API development workflow is shown below:
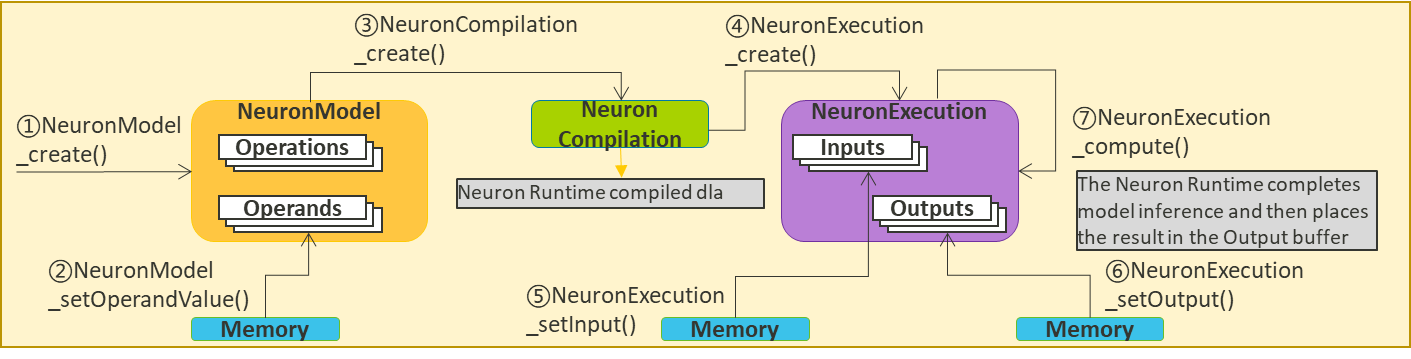
Figure: Neuron Adapter API Workflow
3.1.3.5 NeuroPilot Entry Points
3.1.3.5.1 API Entry Overview
|
Entry Point |
Description |
|
|
|
|
|
|
|
|
3.1.3.5.2 NeuroPilot TFLite Shim API + Neuron Delegate

Figure: NeuroPilot TFLite Shim API + Neuron Delegate Entry Point
- API entry (*)
- NeuroPilot TFLite Shim API
- Languages
- Java, C
- Deployment mode
- Online compile mode
- Target Developers
- 3rd-party app / OEM with the goal of developing APK with AI features
- Implementation location
- System partition
3.1.3.5.3 NeuroPilot TFLite Shim API + NNAPI Delegate
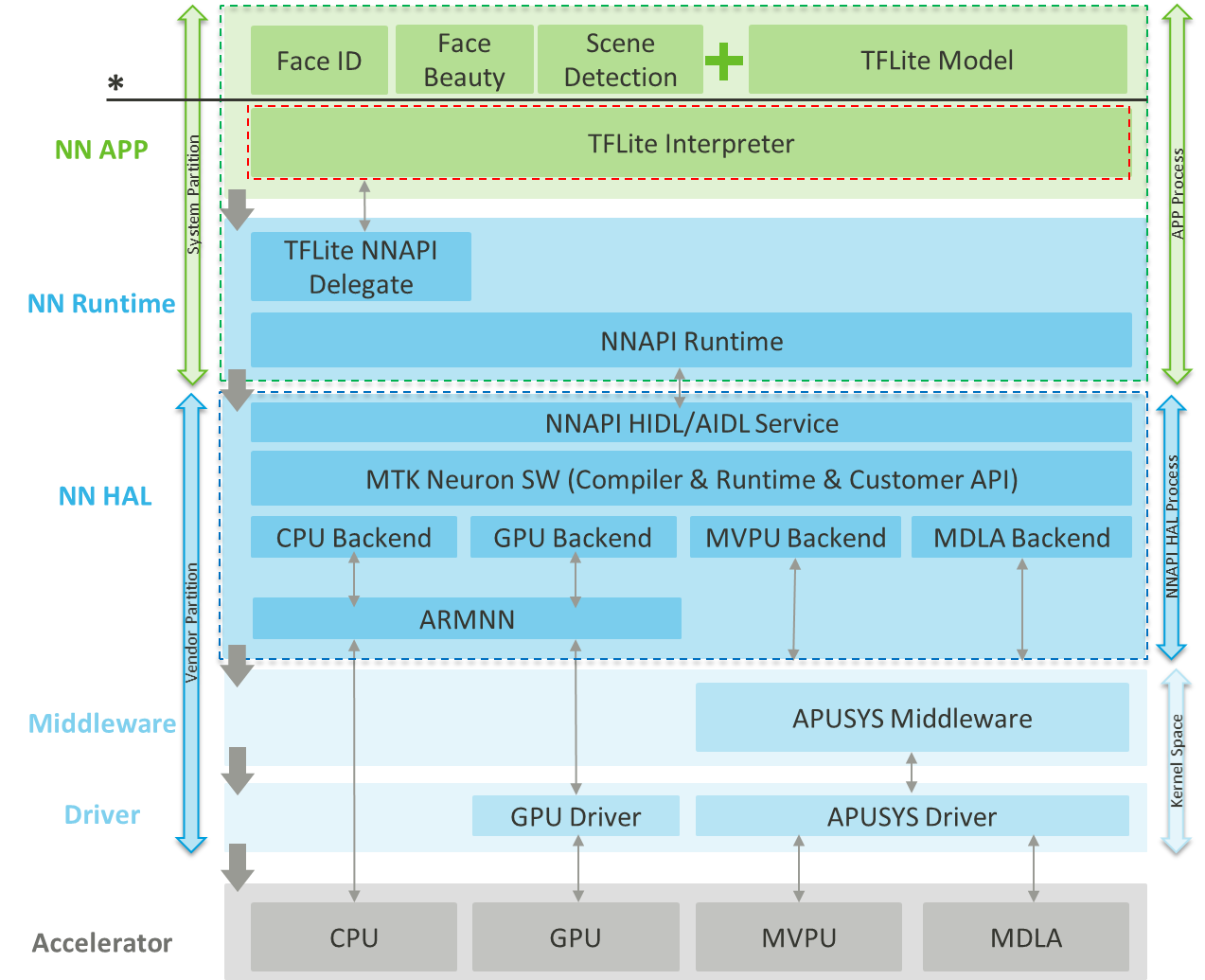
Figure: NeuroPilot TFLite Shim API + NNAPI Delegate Entry Point
- API entry (*)
- NeuroPilot TFLite Shim API
- Languages
- Java, C
- Deployment mode
- Online compile mode
- Target Developers
- 3rd-party app / OEM with the goal of developing APK with AI features
- Implementation location
- System partition
3.1.3.5.4 NeuroPilot Neuron Adapter API

Figure: NeuroPilot Neuron Adapter API Entry Point
- API entry (*)
- Neuron Adapter API
- Languages
- C
- Deployment mode
- Online compile mode
- Target Developers
- 3rd-party app / OEM developing an AI framework
- Implementation location
- System partition
3.1.3.5.5 Google NNAPI

Figure: Google NNAPI Entry Point
- API entry (*)
- NNAPI
- Languages
- C
- Deployment mode
- Online compile mode
- Target Developers
- 3rd-party app / OEMs developing an AI framework
- Implementation location
- System partition
- Limitations
- Belongs to Google AOSP
- If there are unsupported OPs, the OPs cannot be customized.
- Examples
- https://github.com/android/ndk-samples/tree/main/nn-samples
3.1.3.5.6 NeuroPilot Neuron SDK

Figure: NeuroPilot Neuron SDK Entry Point
- API entry (*)
- Neuron Runtime API
- Languages
- C
- Deployment mode
- Offline compile on developer’s computer
- Platform dependent
- Target Developers
- OEM algorithm teams, 3rd-party algorithm vendors with the goal of developing platform AI features (e.g., in Camera HAL)
- Implementation location
- Vendor partition
3.2 NeuroPilot Installation and Setup
This chapter is intended to guide users through the installation process for NeuroPilot and its component software tools.
3.2.1 Setting Up Android Studio
Android Studio is required to run several of the examples and tutorials in this document. Follow these steps to install and set up Android Studio.
- Download and then install the latest version of Android Studio.
- Run Android Studio, and then open SDK Manager.
- Under SDK Platforms, install all required Android versions.

- Under SDK Tools, install NDK.
3.2.2 Quantization Tool Installation Guide
3.2.2.1 System requirements
- Python 3.5 or 3.6
3.2.2.2 Python dependencies
Required:
- argparse >= 1.2
- jsonschema
- numpy >= 1.13.3
- packaging
Optional:
- tensorflow version: >= 1.13 and < 2.0 (required by TensorFlow V1 quantization tool)
- tensorflow version: >= 2.0 and < 2.5 (required by TensorFlow V2 quantization tool)
- torch version: >= 1.3 and < 1.9 (required by PyTorch quantization tool)
|
Note: |
|
3.2.2.3 Installation
3.2.2.3.1 Installing Quantization Tool within a Virtual Environment
- Download the Quantization Tool installation package from neuropilot_downloads.
Quantization Tool is provided as a wheel package containing all the required installation scripts and files.
- Install the package using pip by running the following command.
$ pip3 install mtk_quantization-<version>-py3-none-any.whl
- Verify the installation. The below script prints the installed package version.
$ python3 -c 'import mtk_quantization; print(mtk_quantization.__version__)'
3.2.2.3.2 Installing Quantization Tool without a Virtual Environment
- Download the Quantization Tool installation package from neuropilot_downloads.
Quantization Tool is provided as a wheel package containing all the required installation scripts and files.
- Install the package using pip by running the following command.
$ pip3 install --user mtk_quantization-<version>-py3-none-any.whl
- Verify the installation. The below script prints the installed package version.
$ python3 -c 'import mtk_quantization; print(mtk_quantization.__version__)'
- Because the package is installed under user mode, you might need to configure the PATH environment variable in order to use the executables. The executables are installed in the Python user install directory for your platform, which is typically at ~/.local/bin by default.
$ export PATH=~/.local/bin:$PATH
3.2.3 Converter Tool Installation Guide
3.2.3.1 System requirements
- 64-bit Linux.
- Python 3.5 or 3.6
- pip >= 8.1.0 (required by manylinux1)
|
Warning: |
|
For Python 3.5, we don’t support version 3.5.0 and 3.5.1 because of an ABI incompatible issue in pybind11 package. See the GitHub issue for more details. |
3.2.3.2 Python dependencies
Required:
- argparse >= 1.2
- flatbuffers >= 1.12
- matplotlib >= 3.0
- numpy >= 1.13.3
- packaging
- protobuf >= 3.5.1
- pybind11 >= 2.2
- tqdm >= 4.0
Optional:
- tensorflow version: >= 1.13 and < 2.5 (required by TensorFlow V1 Converter)
- tensorflow version: >= 2.0 and < 2.5 (required by TensorFlow Converter)
- torch version: >= 1.3 and < 1.9 (required by PyTorch Converter)
|
Note: |
|
3.2.3.3 Installation
3.2.3.3.1 Installing Converter Tool within a Virtual Environment
- Download the Converter Tool installation package from neuropilot_downloads.
Converter Tool is provided as a wheel package containing all the required installation scripts and files.
- Install the package using pip by running the following command.
# For Python 3.5
$ pip3 install mtk_converter-<version>-cp35-cp35m-manylinux1_x86_64.whl
# For Python 3.6
$ pip3 install mtk_converter-<version>-cp36-cp36m-manylinux1_x86_64.whl
- Verify the installation. The below script prints the installed package version.
$ python3 -c 'import mtk_converter; print(mtk_converter.__version__)'
3.2.3.3.2 Installing Converter Tool without a Virtual Environment
- Download the Converter Tool installation package from neuropilot_downloads.
Converter Tool is provided as a wheel package containing all the required installation scripts and files.
- Install the package using pip by running the following command.
# For Python 3.5
$ pip3 install --user mtk_converter-<version>-cp35-cp35m-manylinux1_x86_64.whl
# For Python 3.6
$ pip3 install --user mtk_converter-<version>-cp36-cp36m-manylinux1_x86_64.whl
- Verify the installation. The below script prints the installed package version.
$ python3 -c 'import mtk_converter; print(mtk_converter.__version__)'
- Because the package is installed under user mode, you might need to configure the PATH environment variable in order to use the executables. The executables are installed in the Python user install directory for your platform, which is typically at ~/.local/bin by default.
$ export PATH=~/.local/bin:$PATH
3.2.4 Neuron SDK
The Neuron SDK allows users to convert their custom models to MediaTek-proprietary binaries for deployment on MediaTek platforms. The resulting models are highly efficient, with reduced latency and a smaller memory footprint. Users can also create a runtime environment, parse compiled model files, and perform inference on the edge. Neuron SDK is aimed at users who are performing bare metal C/C++ programming for AI applications, and offers an alternative to the Android Neural Networks API (NNAPI) for deploying Neural Network models on MediaTek-enabled Android devices.
3.2.4.1 Requirements
We recommend using the Neuron SDK tool in the following environment:
- CPU: x86-64
- Operating system:
- Ubuntu 14.04
- Ubuntu 16.04
- Ubuntu 18.04
3.2.4.2 Installing Neuron SDK
- Download the Neuron SDK package from neuropilot_downloads.
Neuron SDK is provided as a compressed tar package titled <date>_MDLA_vx.x_SW_<version>_release.tar.gz. This package contains all the required installation scripts and files.
- Uncompress the Neuron SDK package in your working directory by running the following commands.
# Uncompress the tar package
$ tar -xf <date>_MDLA_vx.x_SW_<version>_release.tar.gz
# Change to tool's root location
$ cd <date>_MDLA_vx.x_SW_<version>_release
All executables under host directory can be executed directly. For more information, see readme.txt.
3.3 Hello World Tutorial
3.3.1 Neural Network Model Creation
3.3.1.1 TensorFlow Model to TFLite
MediaTek provides a converter tool which takes a protobuf (.pb) file and produces a TFLite file (.tflite) that is ready to run.
This example uses the MobileNetV1 neural network. This neural network model is an image classifier network that is widely used on mobile devices. This network takes images at 224x224 resolution, and classifies each of them into one of 1000 different classes.
The objective of this example is to take a trained MobileNetV1 model and produce a .tflite model that is ready to use on a MediaTek Android device. The below steps show how to convert the MobileNetV1 model from TensorFlow to TFLite.
3.3.1.1.1 Floating-point Model Conversion Example
The most common case is to start with a trained TensorFlow model in FP32 format.
# Download MobileNet_V1_224 TensorFlow float frozen model
$ wget http://download.tensorflow.org/models/mobilenet_v1_2018_02_22/mobilenet_v1_1.0_224.tgz
$ tar xvf mobilenet_v1_1.0_224.tgz
$ mtk_tensorflow_v1_converter \
--input_frozen_graph_def_file mobilenet_v1_1.0_224_frozen.pb \
--output_file mobilenet_v1_mtk.tflite \
--input_names=input \
--input_shapes=1,224,224,3 \
--output_names=MobilenetV1/Logits/SpatialSqueeze
In order to perform this conversion, the user must know which tensors in the network are the inputs and outputs. Because the MobileNetV1 network is a public reference model, we can specify the tensor names directly in this example.
|
Note: |
|
The values of arguments input_names, output_names, and input_shapes used in the example can be checked using TensorBoard or another model visualization tool, such as Netron. |
When this command finishes, you should see output similar to the following.
Importing the TensorFlow model ...
done
Converting the model ...
[General Transformations]
Before Transform
Subgraph # 0: 223 operators 361 tensors.
After Pass # 1, Elapsed time: 0:00:00.317777
Subgraph # 0: 251 operators 417 tensors.
After Pass # 2, Elapsed time: 0:00:00.499618
Subgraph # 0: 140 operators 253 tensors.
After Pass # 3, Elapsed time: 0:00:00.659985
Subgraph # 0: 30 operators 88 tensors.
[Post-General Transformations]
Before Transform
Subgraph # 0: 30 operators 88 tensors.
done
Exporting the TFLite model ...
done
3.3.1.1.2 Quantized Model Conversion Example
This example shows how to take a quantized network model and produce a model optimized for MediaTek devices. This is often convenient when a quantized model is already available. Some quantized models are tuned to a very high accuracy using many re-training iterations, which may require lots of time and compute resources. Starting with this kind of model may yield better final accuracy results. In this mode, the input file needs to be in the protobuf format (.pb).
# Download MobileNet_V1_224 TensorFlow fake-quantized frozen model
$ wget https://storage.googleapis.com/download.tensorflow.org/models/mobilenet_v1_2018_08_02/mobilenet_v1_1.0_224_quant.tgz
$ tar xvf mobilenet_v1_1.0_224_quant.tgz
# Convert to quantized TFLite with input min-max range as (-1, 1)
$ mtk_tensorflow_v1_converter \
--input_frozen_graph_def_file mobilenet_v1_1.0_224_quant_frozen.pb \
--output_file mobilenet_v1_quant_mtk.tflite \
--input_names=input \
--input_shapes=1,224,224,3 \
--output_names=MobilenetV1/Predictions/Reshape_1 \
--quantize=True \
--input_value_ranges=-1,1
|
Note: |
|
The value of arguments input_names, output_names, and input_shapes used in the example can be checked using TensorBoard or another model visualization tool, such as Netron. |
3.3.1.2 PyTorch Model to TFLite
This example shows how to convert a PyTorch model to TFLite format (.tflite).
import torch
import torchvision
# Download and prepare the PyTorch model
model = torchvision.models.mobilenet_v2(pretrained=True)
trace_data = torch.randn(1, 3, 224, 224)
trace_model = torch.jit.trace(model.cpu().eval(), (trace_data))
torch.jit.save(trace_model, 'mobilenet_v2_float.pt')
# Convert to TFLite
import mtk_converter
converter = mtk_converter.PyTorchConverter.from_script_module_file(
'mobilenet_v2_float.pt', [[1, 3, 224, 224]]
)
_ = converter.convert_to_tflite(output_file='mobilenet_v2_float.tflite')
3.3.2 Java TFlite Tutorial
3.3.2.1 Model Preparation
In order to run neural network models on an Android device, the network model must be prepared according to the tutorial shown in the 2.3.1. Neural Network Model Creation section. Please read and understand that tutorial before proceeding.
|
Note: |
|
3.3.2.2 Java Sample Code
The following sample Java application is a simple timed benchmark for running a MobileNet image classifier model. The sample application follows the Java Native Application development flow described in 2.2.3.1. Android Development. The Android project includes a sample image, which is used as an input to the network. The application invokes the neural network Interpreter, receives the output classification, and reports the latency of the image inference.

Sample Java benchmark app
Sample source code is provided in the file Android_S_NNBenchmark on the Downloads page.
|
Note: |
|
neuropilot.aar provides the NeuroPilot Java API. This library is included in the Java sample code package. |
3.3.2.3 Application Code
The following section describes the major steps of the sample app, to help explain the process of invoking neural network models in Android. The code below can be found in the file app/src/main/java/com/mediatek/nn/benchmark/NNTestBase.java .
- Import the NeuroPilot optimized interpreter, interpreter options, delegate, and delegate options.
import com.mediatek.neuropilot.Delegate;
import com.mediatek.neuropilot.nnapi.NnApiDelegate;
import com.mediatek.neuropilot.neuron.NeuronDelegate;
import com.mediatek.neuropilot.Interpreter;
import com.mediatek.neuropilot.Interpreter.Options;
- Memory-map the model file in the APK Assets.
private MappedByteBuffer loadModelFile() throws IOException {
AssetFileDescriptor fileDescriptor = mActivity.getAssets().openFd(mModelName + ".tflite");
FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel();
long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}
- Generate the input data and output buffer from the image file.
private ByteBuffer generateTestInout(String modelName) {
int batchsize = 1;
int imageSizeX = 224;
int imageSizeY = 224;
int dimPixelSize = 3;
int numBytesPerChannel = 1;
if (modelName.contentEquals(new String("mobilenet_float"))) {
numBytesPerChannel = 4;
}
mImgData = ByteBuffer.allocateDirect(batchsize
* imageSizeX
* imageSizeY
* dimPixelSize
* numBytesPerChannel);
mImgData.order(ByteOrder.nativeOrder());
mImgData.rewind();
Bitmap bmp = Util.getBitmapFromAsset(mActivity.getApplicationContext(), "grace_hopper.bmp");
Bitmap scaledBmp = Bitmap.createScaledBitmap(bmp, imageSizeX, imageSizeY, true);
if (modelName.contentEquals(new String("mobilenet_float"))) {
convertBitmapToFloatBuffer(scaledBmp, imageSizeX, imageSizeY, mImgData);
mLabelProbArrayFloat = new float[1][mLabelList.size()];
} else if (modelName.contentEquals(new String("mobilenet_quantized"))) {
convertBitmapToByteBuffer(scaledBmp, imageSizeX, imageSizeY, mImgData);
mLabelProbArray = new byte[1][mLabelList.size()];
}
return mImgData;
}
|
Note: |
|
Floating-point models require 4 bytes per (color) channel, so the size of the input buffer is larger if the model uses floating point values. Integer models require only 1 byte per channel, and consequently require less memory to store input images. |
- Initialize the interpreter with Neuron delegate or NNAPI.
private Interpreter mInterpreter;
private Options mOptions;
public final void createBaseTest(NNBenchmark ipact) {
mActivity = ipact;
mLabelList = loadLabelList(mModelName);
mImgData = generateTestInout(mModelName);
try {
// new interpreter options
mOptions = new Options();
// use neuron delegate
//NeuronDelegate.Options neuron_options = new NeuronDelegate.Options();
//neuron_options.setCacheDir(mActivity.getFilesDir().getAbsolutePath());
//neuron_options.setAllowFp16(true);
//neuron_options.setExecutionPreference(NeuronDelegate.Options.EXECUTION_PREFERENCE_SUSTAINED_SPEED);
//Delegate delegate = new NeuronDelegate(neuron_options);
// use nnapi
NnApiDelegate.Options nnapi_options = new NnApiDelegate.Options();
nnapi_options.setCacheDir(mActivity.getFilesDir().getAbsolutePath());
nnapi_options.setAllowFp16(true);
nnapi_options.setExecutionPreference(NnApiDelegate.Options.EXECUTION_PREFERENCE_SUSTAINED_SPEED);
Delegate delegate = new NnApiDelegate(nnapi_options);
// add delegate
mOptions.addDelegate(delegate);
mInterpreter = new Interpreter(loadModelFile(), mOptions);
mInterpreter.resizeInput(0, mInputShape);
} catch (IOException e) {
e.printStackTrace();
}
}
Options in NNAPI:
/**
* Use the default setting. The default setting of NNAPI is
* EXECUTION_PREFERENCE_FAST_SINGLE_ANSWER
*/
public static final int EXECUTION_PREFERENCE_UNDEFINED = -1;
/**
* Prefer executing in a way that minimizes battery drain. This is desirable for compilations
* that will be executed often.
*/
public static final int EXECUTION_PREFERENCE_LOW_POWER = 0;
/**
* Prefer returning a single answer as fast as possible, even if this causes more power
* consumption.
*/
public static final int EXECUTION_PREFERENCE_FAST_SINGLE_ANSWER = 1;
/**
* Prefer maximizing the throughput of successive frames, for example when processing successive
* frames coming from the camera.
*/
public static final int EXECUTION_PREFERENCE_SUSTAINED_SPEED = 2;
public static final int EXECUTION_PRIORITY_LOW = 90;
public static final int EXECUTION_PRIORITY_MEDIUM = 100;
public static final int EXECUTION_PRIORITY_HIGH = 110;
/**
* Sets the inference preference for precision/compilation/runtime tradeoffs.
*
* @param preference One of EXECUTION_PREFERENCE_LOW_POWER,
* EXECUTION_PREFERENCE_FAST_SINGLE_ANSWER, and EXECUTION_PREFERENCE_SUSTAINED_SPEED.
*/
public Options setExecutionPreference(int preference) {
this.executionPreference = preference;
return this;
}
public Options setExecutionPrioriy(int executionPriority) {
this.executionPriority = executionPriority;
return this;
}
public Options setMaxCompilationTimeoutDurationNs(long maxCompilationTimeoutDurationNs) {
this.maxCompilationTimeoutDurationNs = maxCompilationTimeoutDurationNs;
return this;
}
public Options setMaxExecutionTimeoutDurationNs(long maxExecutionTimeoutDurationNs) {
this.maxExecutionTimeoutDurationNs = maxExecutionTimeoutDurationNs;
return this;
}
public Options setMaxExecutionLoopTimeoutDurationNs(long maxExecutionLoopTimeoutDurationNs) {
this.maxExecutionLoopTimeoutDurationNs = maxExecutionLoopTimeoutDurationNs;
return this;
}
/**
* Specifies the name of the target accelerator to be used by NNAPI. If this parameter is
* specified, the {@link #setUseNnapiCpu(boolean)} method won't have any effect.
*
* <p>Only effective on Android 10 (API level 29) and above.
*/
public Options setAcceleratorName(String name) {
this.acceleratorName = name;
return this;
}
/**
* Configure the location to be used to store model compilation cache entries. If either {@code
* cacheDir} or {@code modelToken} parameters are unset, NNAPI caching will be disabled.
*
* <p>Only effective on Android 10 (API level 29) and above.
*/
public Options setCacheDir(String cacheDir) {
this.cacheDir = cacheDir;
return this;
}
/**
* Sets the token to be used to identify this model in the model compilation cache. If either
* {@code cacheDir} or {@code modelToken} parameters are unset, NNAPI caching will be disabled.
*
* <p>Only effective on Android 10 (API level 29) and above.
*/
public Options setModelToken(String modelToken) {
this.modelToken = modelToken;
return this;
}
/**
* Sets the maximum number of graph partitions that the delegate will try to delegate. If more
* partitions could be delegated than the limit, the partitions with the larger number of nodes are
* chosen. If unset, it will use the NNAPI default limit.
*/
public Options setMaxNumberOfDelegatedPartitions(int limit) {
this.maxDelegatedPartitions = limit;
return this;
}
/**
* Enable or disable the NNAPI CPU Device "nnapi-reference". If unset, it will use the NNAPI
* default settings.
*
* <p>Only effective on Android 10 (API level 29) and above.
*/
public Options setUseNnapiCpu(boolean enable) {
this.useNnapiCpu = !enable;
return this;
}
/**
* Enable or disable to allow fp32 computation to be run in fp16 in NNAPI. See
* https://source.android.com/devices/neural-networks#android-9
*
* <p>Only effective on Android 9 (API level 28) and above.
*/
public Options setAllowFp16(boolean enable) {
this.allowFp16 = enable;
return this;
}
Options in Neuron Delegate:
/**
* Use the default setting. The default setting of NEURON is
* EXECUTION_PREFERENCE_FAST_SINGLE_ANSWER
*/
public static final int EXECUTION_PREFERENCE_UNDEFINED = -1;
/**
* Prefer executing in a way that minimizes battery drain. This is desirable for compilations
* that will be executed often.
*/
public static final int EXECUTION_PREFERENCE_LOW_POWER = 0;
/**
* Prefer returning a single answer as fast as possible, even if this causes more power
* consumption.
*/
public static final int EXECUTION_PREFERENCE_FAST_SINGLE_ANSWER = 1;
/**
* Prefer maximizing the throughput of successive frames, for example when processing successive
* frames coming from the camera.
*/
public static final int EXECUTION_PREFERENCE_SUSTAINED_SPEED = 2;
public static final int EXECUTION_PRIORITY_LOW = 90;
public static final int EXECUTION_PRIORITY_MEDIUM = 100;
public static final int EXECUTION_PRIORITY_HIGH = 110;
/**
* Sets the inference preference for precision/compilation/runtime tradeoffs.
*
* @param preference One of EXECUTION_PREFERENCE_LOW_POWER,
* EXECUTION_PREFERENCE_FAST_SINGLE_ANSWER, and EXECUTION_PREFERENCE_SUSTAINED_SPEED.
*/
public Options setExecutionPreference(int preference) {
this.executionPreference = preference;
return this;
}
public Options setExecutionPrioriy(int executionPriority) {
this.executionPriority = executionPriority;
return this;
}
public Options setEnableLowLatency(boolean enableLowLatency) {
this.enableLowLatency = enableLowLatency;
return this;
}
public Options setEnableDeepFusion(boolean enableDeepFusion) {
this.enableDeepFusion = enableDeepFusion;
return this;
}
public Options setEnableBatchProcessing(boolean enableBatchProcessing) {
this.enableBatchProcessing = enableBatchProcessing;
return this;
}
public Options setBoostValue(int boostValue) {
this.boostValue = boostValue;
return this;
}
public Options setBoostDuration(int boostDuration) {
this.boostDuration = boostDuration;
return this;
}
/**
* Specifies the name of the target accelerator to be used by NNAPI. If this parameter is
* specified, the {@link #setUseNnapiCpu(boolean)} method won't have any effect.
*
* <p>Only effective on Android 10 (API level 29) and above.
*/
public Options setAcceleratorName(String name) {
this.acceleratorName = name;
return this;
}
/**
* Configure the location to be used to store model compilation cache entries. If either {@code
* cacheDir} or {@code modelToken} parameters are unset, NNAPI caching will be disabled.
*
* <p>Only effective on Android 10 (API level 29) and above.
*/
public Options setCacheDir(String cacheDir) {
this.cacheDir = cacheDir;
return this;
}
/**
* Sets the token to be used to identify this model in the model compilation cache. If either
* {@code cacheDir} or {@code modelToken} parameters are unset, NNAPI caching will be disabled.
*
* <p>Only effective on Android 10 (API level 29) and above.
*/
public Options setModelToken(String modelToken) {
this.modelToken = modelToken;
return this;
}
/**
* Sets the maximum number of graph partitions that the delegate will try to delegate. If more
* partitions could be delegated than the limit, the partitions with the larger number of nodes will
* be chosen. If unset, it will use the NNAPI default limit.
*/
public Options setMaxNumberOfDelegatedPartitions(int limit) {
this.maxDelegatedPartitions = limit;
return this;
}
/**
* Enable or disable to allow fp32 computation to be run in fp16 in NNAPI. See
* https://source.android.com/devices/neural-networks#android-9
*
* <p>Only effective on Android 9 (API level 28) and above.
*/
public Options setAllowFp16(boolean enable) {
this.allowFp16 = enable;
return this;
}
- Run the Interpreter.
public void runTest() {
if (mInterpreter != null) {
if (mLabelProbArray != null) {
mInterpreter.run(mImgData, mLabelProbArray);
} else if (mLabelProbArrayFloat != null) {
mInterpreter.run(mImgData, mLabelProbArrayFloat);
}
}
}
When the interpreter runs, it produces an Array as output. This output array is a set of class probabilities that indicated how likely each possible classification is, based on the network evaluation. The class with the highest probability is the class that is reported for the image.
3.3.3 C++ TFlite Tutorial
3.3.3.1 Model Preparation
In order to run neural network models on an Android device, the network model must be prepared according to the tutorial shown in the 2.3.1. Neural Network Model Creation section. Please read and understand that tutorial before proceeding to this tutorial.
|
Note: |
|
In general, nearly all .tflite models will run on Android devices. However, some types of operations in the neural network model may cause large differences in run time speed, due to special-cases of operation support, both from the Android version itself, and operation support for a given device. Consult the NeuroPilot Introduction and Platform Specification -> 2. Hardware Support Specification section for more details on device capabilities and operation support. |
3.3.3.2 Native App Development
The most effective way of getting top performance on Android devices is to develop applications using the Android NDK. In this native method of development, users write the app in C++, and call APIs provided by the NDK. NNAPI is one of these APIs, and there is also a TFLite C++ API as well. This method still provides all the run-time control of the TFLite interpreter, but yields smaller and more compact applications that can be highly tuned for performance.
3.3.3.3 Native Sample App
We provide a sample native application for reference. This application is based on the MobileNetSSD neural network. This network is an Object Detection network, which takes images as inputs and computes the presence of known objects in the image. These object detection networks can identify an arbitrary number of objects in any single image, including objects that may overlap one another visually. the output of this network is a series of bounding-boxes which identify which region of the input image an object lies, and what is the classification of each object found.
This app is provided as a ready-to-compile example object_detection_mobilessd.tar.gz. Inside are provided several scripts to build and deploy the application.
3.3.3.3.1 Application Build and Load
To build and run this application, we need to perform the following steps.
- Build the application code.
cd build
rm -rf *
cmake -DTARGET=aarch64 -DNDK_STANDALONE_TOOLCHAIN=../android-ndk-r17b-toolchain-arm64 ../
make
cp MobilenetSSDDemo ../
cd ..
- Prepare the file inputs for the program.
cd input
python Convert2ModelInput.py voc_motor.jpg 300 300
python Convert2ModelInput.py voc_motor.jpg 224 224
cd ..
|
Note: |
|
Above commands is wrote in run 0_python_convert_input_2_bin.bat. |
- Push the application data onto the Android device.
adb push model/mobilenet_coco.tflite /data/local/tmp/mobilenet_coco.tflite
adb push model/mobilenet_coco_quant.tflite /data/local/tmp/mobilenet_coco_quant.tflite
adb push model/mobilenet_ssd_pascal.tflite /data/local/tmp/mobilenet_ssd_pascal.tflite
adb push model/mobilenet_ssd_pascal_quant.tflite /data/local/tmp/mobilenet_ssd_pascal_quant.tflite
|
Note: |
|
Above commands is wrote in 2_push_model.bat. |
- Push the input data to the device.
adb push input/input_224224_q.bin /data/local/tmp/mobilenet_input_q.bin
adb push input/input_224224_f.bin /data/local/tmp/mobilenet_input_f.bin
adb push input/input_300300_q.bin /data/local/tmp/mobilenet_ssd_input_q.bin
adb push input/input_300300_f.bin /data/local/tmp/mobilenet_ssd_input_f.bin
|
Note: |
|
Above commands is wrote in 3_push_input.bat. |
- Run the application on the device.
adb wait-for-device
adb root
adb remount
adb push MobilenetSSDDemo /data/local/tmp/MobilenetSSDDemo
# Run Test
adb shell "cd /data/local/tmp;chmod +x MobilenetSSDDemo;./MobilenetSSDDemo"
# Confirm APU service crash not happened
|
Note: |
|
Above commands is wrote in 4_run.bat. |
3.3.3.4 Application Code
3.3.3.4.1 Mediatek Shim Layer
To aid the development of native app code, Mediatek provides a shim API which makes code development easier and faster. This shim layer will invoke any required NeuroPilot libraries as well as the TFLite interpreter. The example shown here uses this shim layer.
3.3.3.4.2 Code Walk-Through
This application can be understood in several parts.
- Initialize the neural network Model.
ANeuralNetworksTFLite* tf;
auto time1 = std::chrono::high_resolution_clock::now();
if (ANeuralNetworksTFLite_create(&tf, model_path) != ANEURALNETWORKS_NO_ERROR){
return 0;
}
auto time2 = std::chrono::high_resolution_clock::now();
printf("Create and init time: %f ms\n",float((time2-time1).count())/1000000);
Get a handle to the input Tensor, and fill it with data. In this case, this data will be a binary file loaded from disk.
TFLiteTensor inputTensor;
if (ANeuralNetworksTFLite_getTensor(tf,
TFLITE_BUFFER_TYPE_INPUT,
&inputTensor) != ANEURALNETWORKS_NO_ERROR){
ANeuralNetworksTFLite_free(tf);
return 0;
}
// Fill input data from file
std::ifstream input(input_path);
if (!input.good()) {
printf("Fail to read %s\n", input_path);
return 0;
}
if (inputTensor.type == 2) { // Is uint8
input.read((char*)inputTensor.buffer, sizeof(uint8_t) * inputTensor.bufferSize);
}else{ // Is float
input.read((char*)inputTensor.buffer, sizeof(float) * inputTensor.bufferSize);
}
input.close();
|
Note: |
|
In this sample application, input images are pre-processed into binary files via the script 0_python_convert_input_2_bin.bat. This script generates binary files which can be directly copied into the neural network input tensor. |
- Run the neural network model and produce one output result from one input sample. Because this is an object segmentation network, there are 2 output tensors which produce results.
model_output(tf1,0,false);
model_output(tf1,1,false);
int model_output(ANeuralNetworksTFLite* tf,int index,bool show_tensor){
auto time6 = std::chrono::high_resolution_clock::now();
TFLiteTensor outputTensor;
if (ANeuralNetworksTFLite_getTensorByIndex(tf,
TFLITE_BUFFER_TYPE_OUTPUT,
&outputTensor,
index) != ANEURALNETWORKS_NO_ERROR){
ANeuralNetworksTFLite_free(tf);
return 0;
}
}
- Process the network results. For this object detection network, there is quite a bit of processing that needs to be done on the network outputs. Specifically, the non-maximal suppression (NMS) calculation must be done on the outputs. This calculation takes two inputs representing region proposals and confidence scores for each region, and compute the highest likelihood results via applying NMS.
ssd_post_process(tf1,true,ResultMSG);
|
Note: |
|
The entire output processing code in the app is too large to reprint here. Please refer to the ssd_post_process() function inside ssd.cpp for details. This example app follows the common NMS implementation, which as many references online. |
3.3.3.5 Expected Output
This application is non-GUI, so it will emit only text outputs. When it’s run, it will display a result similar to below.
-------- Load model --------
Create and init time: 363.635 ms
Get input tensor , time: 0.542462 ms , type: 1 , dimsSize: 4 , bufferSize: 270000 , dims=[ 1 300 300 3 ]
-------- Inference --------
Inference time: 10.294231 ms
Get output tensor , time: 0.003000 ms , type: 1 , dimsSize: 3 , bufferSize: 40257 , dims=[ 1 1917 21 ]
Get output tensor , time: 0.001307 ms , type: 1 , dimsSize: 3 , bufferSize: 7668 , dims=[ 1 1917 4 ]
Total 1 detections found:
Top 1 Results:
[Top 1 0.6517] person X:47.19 Y:1.79 W:123.33 H:224.55 BoxID:1794
Post-process time: 6.761308 ms
Total time: 17.086 ms
----- UnitTest verify -----
Performance correct
Accuracy correc



