4. Developer Tools
4.1 Model Development
4.1.1 Converter
4.1.1.1 Converter Tool Overview
Converter Tool can convert models from different deep learning training frameworks into a format that can be deployed on MediaTek platforms. Converter Tool handles the variations of both the operator definitions and model representations among different training frameworks, and provides device-independent optimizations to the given model.
In this section, we provide a detailed introduction and some examples of using Converter Tool. Currently, Converter Tool supports TensorFlow v1, TensorFlow v2, PyTorch, and Caffe as the conversion source, and TensorFlow Lite as the conversion target. Converter Tool is also capable of quantizing the model with different configurations, such as 8-bit asymmetric quantization, 16-bit symmetric quantization, or mixed-bit quantization. Post-training quantization can be applied during the conversion process if necessary.
4.1.1.2 Converter Tool Introduction
Converter Tool can convert models from different deep learning training frameworks into a format that can be deployed on MediaTek platforms. Converter Tool handles the operator definition variations among different deep learning training frameworks, and can also quantize a floating-point model into an integer-only representation. Users can pass a quantization-aware training result to Converter Tool, configure Converter Tool to do post-training quantization, or apply both of these techniques together.
Converter Tool supports the following model formats:
- Caffe
- Prototxt file and caffemodel file.
- TensorFlow V1
- Frozen GraphDef object or file.
- TensorFlow SavedModel.
- TensorFlow Keras model object or file.
- Session object.
- TensorFlow V2
- Concrete functions.
- TensorFlow SavedModel.
- TensorFlow Keras model object or file.
- PyTorch
- ScriptModule object or file generated from tracing.
|
See also: |
|
For details about PyTorch ScriptModule representation, see the PyTorch documentation. |
4.1.1.2.1 Converting Composite Operators
Certain operators are not included as primitive operators in some training frameworks. In this case, a typical workaround is to use multiple primitive operators to composite the missing operator. Typically, there are a large numbers of ways (or patterns) to composite the same missing operator. Each pattern gives a different runtime performance after deploying the model on a MediaTek platform.
In this section, we provide reference patterns for commonly-used composite operators. We recommend that users use these patterns to obtain better performance on MediaTek platforms.
4.1.1.2.2 Converting to a Quantized Model
Converter Tool supports both the official TensorFlow quantization-aware training tool and NeuroPilot Quantization Tool. For users who are using a custom quantization-aware training tool for advanced quantization techniques or specific quantization use cases, the converter has introduced a common interface for both TensorFlow and PyTorch. By following the interface when exporting the quantization results, users can easily deploy their quantization results on MediaTek platforms. For more details, see 4.1.1.6. Appendix – Integrate with Custom Quantization-aware Training Tools.
|
Important: |
|
The official PyTorch quantization-aware training tool is not currently supported. |
4.1.1.2.2.1 Quantization Approaches
The NeuroPilot SDK provides three different ways to quantize a model.
- Quantization-aware training: FakeQuantize and other related operators are inserted into the model by the quantization-aware training tools provided by NeuroPilot SDK, or by another training framework such as TensorFlow. These operators help to deduce the proper quantization ranges, and to simulate the quantization impact during the model training phase. Converter Tool reads the quantization information from the FakeQuantize operators, and then uses this information to quantize the model directly.
- Post-training quantization: Instead of re-training the model with quantization awareness, users can do quantization during the conversion phase. The quantization is based on a user-specified floating-point model. Users must provide a calibration dataset, typically 100 to 1000 representative batches, for Converter Tool to deduce the proper quantization ranges for each of the tensors.
- Post-training dynamic quantization: Post-training quantization can also be done without a calibration dataset. In this case, the constant weight tensors of the convolutional operators are quantized, while the other activation tensors stay as floating-point data types. During inference on MediaTek platforms, these convolutional operators are executed within the integer domain by quantizing the input tensor dynamically based on the value range of the current batch. Note that other operators, such as pooling or arithmetic operators, are executed within the floating-point domain.
The following is a brief comparison between the above three quantization methods and the floating-point baseline, assuming the same precision setting:
|
Method |
Need re-training |
Need calibration dataset |
Quantized weight |
Quantized activation |
Quality/Accuracy |
Performance |
|
Floating-point |
No |
No |
No |
No |
Best |
Normal |
|
Quantization-aware training |
Yes |
No |
Yes |
Yes |
Better |
Better |
|
Post-training quantization |
No |
Yes |
Yes |
Yes |
Good |
Better |
|
Post-training dynamic quantization |
No |
No |
Yes |
No |
Good |
Good |
|
Note: |
|
When using the NeuroPilot Converter Tool, users can apply quantization-aware training and post-training quantization together. For example, use quantization-aware training first. Then use post-training quantization to deduce the quantization range of the tensors that were missed by the quantization-aware training tool, or for tensors created during the conversion phase. |
4.1.1.2.2.2 Using Post-Training Quantization
Converter Tool provides an easy way to do post-training quantization during the conversion process. To do post-training quantization, users only need to prepare a representative dataset for Converter Tool, in order to calibrate the quantization value range for the activation tensors in the model. Converter Tool computes the exponential moving average minimum and maximum range over all the batches in the given dataset, and then uses that as the quantization value ranges of the tensors. Converter Tool also provides many configuration options when doing post-training quantization, including the quantization bitwidth, and asymmetric/symmetric settings.
The post-training quantization function can also be used jointly with the quantization-aware training tools. In this case, Converter Tool only calibrates a tensor if the tensor’s quantization value range was not deduced during quantization-aware training.
4.1.1.2.2.3 Quantization Bitwidth
The quantization bitwidth affects how tensors are quantized and their resulting data types. Bitwidth can be deduced from multiple sources based on the following precedence, from highest to lowest.
- Set by the input_quantization_bitwidths converter option. This converter option allows users to assign specific quantization bitwidths to the model input tensors. This option has the highest precedence, so it overwrites the settings of existing FakeQuantize operators on the model input tensors.
- Deduced from the FakeQuantize operators. If a FakeQuantize operator exists in the model, Converter Tool retrieves the bitwidth setting and then assigns the bitwidth to both the input and output tensors of the FakeQuantize operator. These FakeQuantize operators are typically used by quantization-aware training tools to simulate the quantization impact during model training.
- Set by the default_weights_quantization_bitwidth converter option. This converter option allows users to set the default quantization bitwidth of all the weight tensors of the affine operators. If this converter option is not set, the weight tensor bitwidth is the same as the input tensor bitwidth of the corresponding affine operator.
- Propagated from other tensors. If the input tensors of an operator already have bitwidth settings, the converter tool propagates the bitwidths to the output tensors of the operator, if the output tensor does not have a bitwidths yet. For constant input tensors, their bitwidths are deduced based on the bitwidth of other non-constant input tensors.
4.1.1.2.2.4 Quantization Value Range
The quantization value range, meaning the minimum and maximum value, affects how floating-point values are approximated to integer values in a quantized tensor. The quantization value range can be deduced from multiple sources based on the following precedence, from highest to lowest.
- Set by the input_value_ranges converter option. This converter option allows users to assign a specific quantization value range to each of the model’s input tensors. This option has the highest precedence, so it overwrites the settings of existing FakeQuantize operators on the model input tensors.
- Deduced from the FakeQuantize operators. If a FakeQuantize operator exists in the model, Converter Tool retrieves the minimum and maximum values and then assigns them to the input and output tensors of the FakeQuantize operator. These FakeQuantize operators are typically used by quantization-aware training tools to simulate the quantization impact during model training.
- Hard coded to a fixed range. Some operators produce output tensors with a fixed value range. In these cases, Converter Tool hard-codes these output tensors to a fixed quantization value range. For example, the Relu6 operator hard-codes the quantization value range of output tensors to [0.0, 6.0]. For constant tensors, Converter Tool hard-codes the quantization value range to their minimum and maximum content values.
- Propagated from other tensors. For some operators, such as Reshape, the quantization value ranges of their output tensors can be deduced from the quantization value ranges of their input tensors. In these cases, Converter Tool propagates the quantization value ranges to the output tensors of these operators, if the output tensor does not have a quantization value range yet.
- Deduced from post-training quantization. Post-training quantization deduces the quantization value ranges for all tensors that do not have quantization value ranges yet, based on the provided calibration dataset.
|
Note: |
|
During the conversion process, Converter Tool converts the quantization value range information (i.e. minimum and maximum values) to the zero_point and scale representation. For this reason, these quantization value ranges are typically nudged by a small amount, to ensure that zero_point exists and is an integer value. |
4.1.1.2.2.5 Quantized Data Type
Tensors that have both the quantization value range and the quantization bitwidth will be quantized. The quantized data type is determined based on the quantization bitwidth:
- Quantization bitwidths in the range [2, 8] are quantized to UINT8 or INT8, determined by the use_unsigned_quantization_type converter setting.
- Quantization bitwidths in the range [9, 16] are quantized to INT16.
|
Note: |
|
If the quantization bitwidth does not exactly match the bitwidth of the resulting data type, Converter Tool will expand the quantization value range in order to keep the scale the same in the resulting model. |
4.1.1.2.2.6 Symmetric and Asymmetric Quantization
Converter Tool provides two options, use_weights_symmetric_quantization and use_symmetric_quantization. These two options determine whether to use symmetric quantization ranges for weight and activation tensors that have their quantization ranges deduced from post-training quantization. These two converter options do not affect the quantization ranges deduced from the FakeQuantize operators.
- When symmetric quantization is used for a tensor with a signed quantized data type, the zero_point value is always 0.
- When symmetric quantization is used for a tensor with an n-bit unsigned quantized data type, the zero_point value is always 2 ^ (n-1).
4.1.1.2.2.7 Error Analysis After Conversion
After converting to a quantized model, we recommend that users verify the quantized model before deploying it to MediaTek platforms. To perform the verification, users can execute the model using Converter Tool’s reference operator implementations, such as the the TFLiteExecutor class, and then check the quality or accuracy of the output results.
Users might sometimes observe a significant degradation in quality between the fake-quantized model produced after the quantization-aware training process, and the final quantized model produced after the conversion process. Converter Tool provides a visualization tool, the plot_model_quant_error API, to help identify the causes of root quality degradation based on the provided input data. This visualization tool plots the following errors between the fake-quantized model and the final quantized model:
- The layer-wise error between the output tensors of each operator. This helps identify whether some specific operators produce unreasonably high quantization errors.
- The error between the weight tensors of each convolutional operator. This helps identify the cause of the output quantization errors of these convolution operators.
- The cumulative error between the output tensors of each operator. This helps users understand how layer-wise quantization errors are being propagated through the network structure.
|
Note: |
|
To precisely identify potential quantization errors when running the visualization tool, users must pass the same converter options as they used to produce the original quantized model. |
The following lists typical error patterns and possible solutions.
For convolutional operators such as Conv2D, DepthwiseConv2D, and TransposeConv2D
Errors in the weight tensor and output tensor between the fake-quantized model and the quantized model are typically less than a maximum of 1.0 scales, or an average of 1e-2 scales. Exceeding these criteria typically means one of the following:
- No FakeQuantize operator exists after the weight tensor and/or the output tensor, to simulate the quantization impact during training process.
- The provided converter options do not match the FakeQuantize operators in the model. For example, asymmetric quantization is used for quantization-aware training, but symmetric quantization is used for the converted model.
For operators such as AveragePool2D, Concat, and ResizeBilinear
The quantization ranges of these operators’ output tensors can be deduced during the conversion process, based on the quantization ranges of the input tensors. Therefore, by default NeuroPilot Quantization Tool does not insert FakeQuantize operators after the operator’s output tensors. This results in relatively large errors, for example greater than 1e-2 scales on average, between the output tensors of the fake-quantized model and the final quantized model. To reduce these errors, users can insert additional quantizer target entries with the quantizer type UnionQuantizer into the quantization configuration file. These additional quantizers simulate the quantization impact for these tensors, while keeping the quantization ranges the same as the ranges of the input tensors.
4.1.1.3 Creating a Model Containing Custom Operators
Converter Tool provides APIs for users to annotate a sub-graph containing one or more TensorFlow operations as a custom operator. The sub-graph can contain either official TensorFlow operators, or user-defined operators that are registered to the TensorFlow library.
During model training, these annotations are just Identity operators, and do not affect the behavior of both the forward pass and backward pass. When exporting the model for conversion, Converter Tool provides APIs to resolve these annotations and replace the annotated sub-graphs with custom TensorFlow operators. After conversion, those custom TensorFlow operators will be converted to the custom TensorFlow Lite operators directly.
|
Warning: |
|
|
Important: |
|
4.1.1.3.1 General Workflow
The following is a summary of the typical workflow for adding a custom operator that is supported by Converter Tool when building the TensorFlow model.
- Create a CustomOpAnnotator object for the custom operator and configure object settings. These settings include the custom operator type, the attributes of the custom operator, whether the custom operator can be quantized, etc.
- Annotate the input tensors of the custom operator by invoking the function annotate_inputs of class CustomOpAnnotator. This function returns the annotated input tensors. Users should use these annotated tensors instead of the original input tensors to build the computation logic of the custom operator.
- Use the annotated input tensors to build the computation logic of the custom operator. The computation logic must form a sub-graph containing one or more TensorFlow operators, and must fit the expected forward pass and backward pass behavior of the custom operator. Users can use either official TensorFlow operators or user-defined operators that are registered to the TensorFlow library.
- Annotate the output tensors of the custom operator by invoking the function annotate_outputs of class CustomOpAnnotator. This function returns the annotated output tensors. Users should use these annotated tensors instead of the original output tensors to build the rest of the model.
- Build the rest of the model and start training. After training is finished, export and freeze the evaluation model as a GraphDef object.
- Resolve the custom operator annotations in the GraphDef model object using the resolve_custom_op_annotations API. This API returns a new GraphDef model and replaces the annotated sub-graph with the custom TensorFlow operator.
- Convert the resolved GraphDef model object to a TensorFlow Lite model. During conversion, Converter Tool follows the user-specified settings of the CustomOpAnnotator object.
4.1.1.3.2 Identifying Custom Operators
When initializing the CustomOpAnnotator object, users must provide the following values:
- Operator name: Used together with vendor name to identify a specific custom operator implementation registered on the device.
- Vendor name: Used together with operator name to identify a specific custom operator implementation registered on the device.
- Device name: Used to indicate which compute device is responsible for running the custom operator.
|
Important: |
|
Users must use the same operator name and vendor name when initializing the CustomOpAnnotator object, and when registering the corresponding custom operator implementation. |
4.1.1.3.3 Custom Operator Attributes
The custom operator can contain attributes that are used during inferences. Users can provide the corresponding custom operator attributes when initializing the CustomOpAnnotator object using the attribute custom_attributes. These custom attributes are then stored in the TFLite custom_options field using the FlexBuffers format.
Currently, Converter Tool only support the following attribute types. The attribute type is automatically deduced from the attribute value.
- Boolean
- Floating-point
- Integer
- Floating-point list
- Integer list
4.1.1.3.4 Determining Output Tensor Shapes
During the conversion process, Converter Tool fills the shapes of all the tensors in the model based on the user-provided model input shapes. Users must specify how Converter Tool determines the output tensor shapes of the custom operator.
Converter Tool provides two methods for determining output tensor shapes, configured by setting the output_shapes attribute when initializing the customOpAnnotator object.
- Set a shape propagation policy name in the output_shapes argument. Converter Tool pre-defines several high-level policies for deducing the output tensor shapes, based on the input tensor shapes of the custom operator. Valid policies are:
- 'Same': Converter Tool copies the shape of the first input tensor to all output tensors.
- 'Broadcast': Converter Tool sets the output tensor shape to the numpy-broadcasted shape from the input tensor shapes. For example, if the shapes of the input tensors are [1, 4, 5, 6] and [3, 1, 5, 6], then the output tensor shape will be [3, 4, 5, 6]. This policy only supports custom operators with two input tensors and one output tensor.
- Set fixed output tensor shapes in the output_shapes argument, as a list of list of int values. In this case, the output tensor shapes do not change with different input tensor shapes.
4.1.1.3.5 Making a Custom Operator Quantizable
To configure whether a custom operator is quantizable or not, set the quantizable attribute when initializing the CustomOpAnnotator object. If quantizable is true, then the input and output tensors may be quantized, depending on whether these tensors have quantization information. If quantizable is false, the input and output tensors will never be quantized, and Converter Tool will add Dequantize and Quantize operators around the custom operator if necessary.
|
Note: |
|
Converter Tool does not currently support hybrid quantization for custom operators. This means that either all floating-point input and output tensors must be quantized, or no floating-point input and output tensors can be quantized. |
4.1.1.3.6 Determining Output Quantization Ranges
When converting to a quantized model, Converter Tool determines the quantization ranges of the floating-point tensors in the model. Users must specify how Converter Tool determines the output quantization ranges of the custom operator.
Converter Tool provides the following methods for determining output quantization ranges:
- Insert FakeQuantize operators at the output side of the custom operator. Typically, this is done when doing quantization-aware training. In this case, do not set the output_quant_ranges argument when initializing the CustomOpAnnotator object. Note: The FakeQuantize operator must be inserted after the output tensors are annotated.
- Set a quantization range propagation policy name in the output_quant_ranges argument when initializing the CustomOpAnnotator object. Converter Tool pre-defines several high-level policies for determining the output quantization ranges, based on the input quantization ranges of the custom operator. Valid policies are:
- 'Overall': Converter Tool finds the lowest min value and the highest max value within all input quantization ranges, and then uses these two values as the min/max range for all output tensors. For example, if the input quantization ranges are (-1.0, 4.0) and (-3.0, 0.0), then the output quantization range will be (-3.0, 4.0).
- 'Same': Converter Tool sets the quantization range of all output tensors to the quantization range of the first input tensor.
- Set fixed output quantization ranges in the output_quant_ranges argument when initializing the CustomOpAnnotator object. The ranges are provided as a float list, where every two adjacent numbers in the list are a min/max pair ([min_1, max_1, min_2, max_2,..]). In this case, the output quantization ranges do not change with different input quantization ranges.
- Perform post-training quantization. To perform post-training quantization on a model with custom operators, users must provide the implementation of the custom operators. The custom op implementation libraries can be set using the custom_op_lib_map converter option. For more details about writing the custom op implementation, see 4.1.1.3.8. Write the Implementations of Custom Operators.
|
Note: |
|
The CustomOpAnnotator API will not insert FakeQuantize operator after annotated output tensors automatically even when the output_quant_ranges argument is set. In this case, the quantization impact (e.g., rounding error and clamping error) will not be simulated during the training process. To simulate the output quantization impact, configure the quantization-aware training tool to insert FakeQuantize operators after the annotated output tensors of the custom operator. |
4.1.1.3.7 Execute the TFLite Model with Custom Operators
After converting the model to TFLite, the custom operators are now represented using TFLite custom operators. The TFLite custom opcodes are the same as the operator types provided to the CustomOpAnnotator class. The custom attributes are stored in the custom_options field in the FlexBuffers format.
|
Warning: |
|
Before mtk_converter version v1.9, each custom operator was represented using a special TFLite custom operator called MTKEXT_CUSTOM. Converter Tool also used a custom option called op_type to store the actual custom operator type. This interface is now deprecated and is no longer supported. |
To execute the TFLite model with custom operators on a computer using Converter Tool, users must provide the implementation of the custom operators. The custom op implementation libraries can be set using the custom_op_lib_map attribute of the TFLiteExecutor class. For more details about writing the custom op implementation, see 4.1.1.3.8. Write the Implementations of Custom Operators.
4.1.1.3.8 Write the Implementations of Custom Operators
For each custom operator, users must provide a C++ source file containing two functions get_output_shapes and execute. Next, users must compile the C++ source file into a shared library, which will be passed to Converter Tool later.
The necessary header files and library files are embedded into the Python package of Converter Tool. Users can find the corresponding path from the mtk_converter.sysconfig.get_include_dir() and mtk_converter.sysconfig.get_lib_dir() APIs. These header files provides utility files for users to write the custom operator implementations more easily.
Please check below 4.1.1.3.9. Custom Operator Example section for an example of a custom operator implementation.
4.1.1.3.9 Custom Operator Example
Suppose we are building a custom operator for a special activation function. This activation function takes two attributes, and can be expressed as sigmoid(relu(x) * PARAM_A + PARAM_B).
The following is an example for building a model with the custom operator.
import tensorflow as tf
import mtk_converter
PARAM_A = 1.3
PARAM_B = 0.5
annotator = mtk_converter.tfv1.CustomOpAnnotator(
'CustomActivation',
'example_device',
'example_vendor',
output_shapes='Same',
quantizable=True,
output_quant_ranges=[(0.0, 1.0)],
custom_attributes=[('param_a', PARAM_A), ('param_b', PARAM_B)]
)
graph = tf.Graph()
with graph.as_default():
input_tensor = tf.placeholder(tf.float32, shape=[1, 28, 28, 3], name='Placeholder')
output_tensor = tf.contrib.layers.conv2d(input_tensor, num_outputs=3, kernel_size=3)
output_tensor = tf.quantization.fake_quant_with_min_max_args(output_tensor, 0.0, 3.5, num_bits=8)
# Build the custom operator
output_tensor, = annotator.annotate_inputs([output_tensor])
output_tensor = tf.nn.sigmoid(tf.nn.relu(output_tensor) * PARAM_A + PARAM_B)
output_tensor, = annotator.annotate_outputs([output_tensor], name='custom_activation')
output_tensor = tf.contrib.layers.conv2d(output_tensor, num_outputs=1, kernel_size=3)
output_tensor = tf.quantization.fake_quant_with_min_max_args(output_tensor, 0.0, 5.0, num_bits=8)
sess = tf.InteractiveSession(graph=graph)
sess.run(tf.global_variables_initializer())
freeze_graph_def = tf.graph_util.convert_variables_to_constants(sess, sess.graph.as_graph_def(), [output_tensor.op.name])
# Save the original model (with custom operator annotations)
with open('./annotated_model.pb', 'wb') as f:
f.write(freeze_graph_def.SerializeToString())
# Save the model after resolving all the custom operator annotations
resolved_graph_def = mtk_converter.tfv1.resolve_custom_op_annotations(freeze_graph_def)
with open('./resolved_model.pb', 'wb') as f:
f.write(resolved_graph_def.SerializeToString())
converter = mtk_converter.TensorFlowV1Converter.from_frozen_graph_def_file(
'./resolved_model.pb', ['Placeholder'], [[1, 28, 28, 3]], [output_tensor.op.name]
)
converter.input_value_ranges=[(0.0, 1.0)]
converter.quantize = True
converter.convert_to_tflite(output_file='resolved_model.tflite')
|
Note: |
|
In this example, we manually insert FakeQuantize operators with fixed quantization ranges in the model for simplicity. In a real scenario, these FakeQuantize operators and the corresponding quantization ranges would be handled during the quantization-aware training process. |
The structure of the produced TensorFlow model (with custom operator annotations) looks like this:
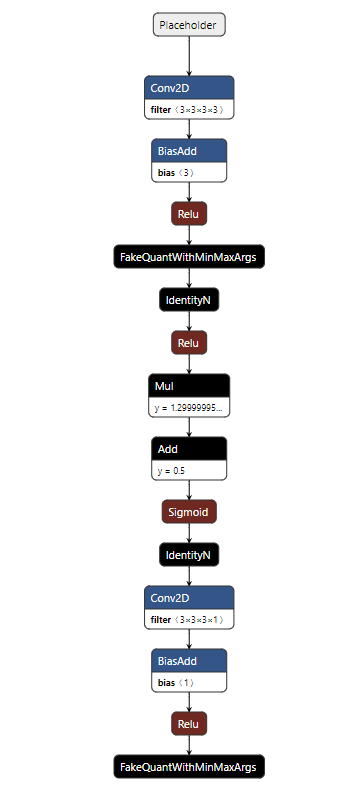
After resolving the custom operator annotations, the structure of the TensorFlow model looks like this:
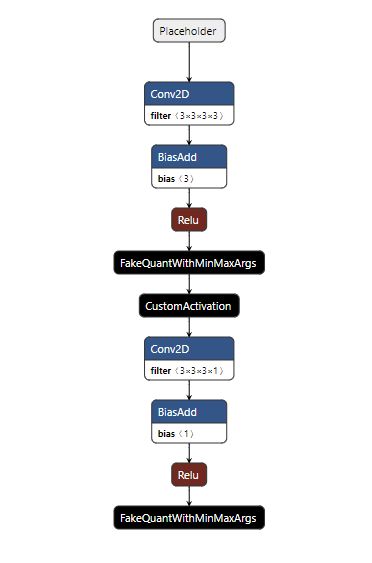
After conversion, the resulting TensorFlow Lite model looks like the following.
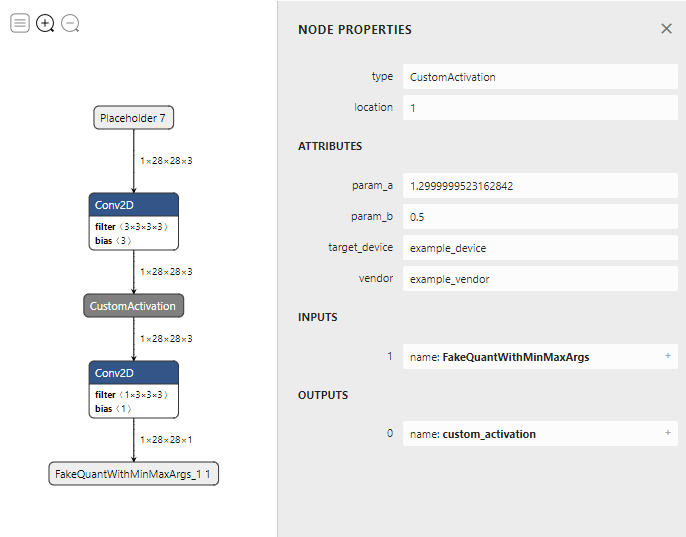
The custom operator can be implemented like the following example, based on the utility APIs provided by Converter Tool.
#include <cmath>
#include "custom_op_context.h"
namespace {
void FloatImpl(const float* input_data_ptr, float* output_data_ptr, int64_t elements_count,float param_a, float param_b) {
for (int64_t i = 0; i < elements_count; i ++) {
float output_data = std::max(input_data_ptr[i], 0.f); // relu
output_data = output_data * param_a + param_b; // handle param_a and param_b
output_data = 1.f / (1.f + std::exp(-output_data)); // sigmoid
output_data_ptr[i] = output_data;
}
}
} // namespace
void get_output_shapes(mtk_converter::CustomOpContext* context,
std::vector<std::vector<int64_t>>* output_shapes) {
CHECK_EQ(context->NumInputs(), 1, "Invalid number of input tensors");
output_shapes->clear();
output_shapes->push_back(context->Input(0).GetShape().GetDims());
}
void execute(mtk_converter::CustomOpContext* context) {
const auto& input_tensor = context->Input(0);
auto& output_tensor = context->Output(0);
// Get the attributes
float param_a, param_b;
context->GetAttr("param_a", ¶m_a);
context->GetAttr("param_b", ¶m_b);
const auto& input_type = input_tensor.GetDataType();
const auto& output_type = output_tensor.GetDataType();
int64_t elements_count = input_tensor.GetShape().GetElementsCount();
if (input_type == mtk_converter::DataType::kFloat32) {
const float* input_data_ptr = input_tensor.GetTypedDataAddress<float>();
float* output_data_ptr = output_tensor.GetMutableTypedDataAddress<float>();
FloatImpl(input_data_ptr, output_data_ptr, elements_count, param_a, param_b);
} else {
// Here, we simply dequantize the input, compute in floating-point type, and quantize the output
const auto& input_data = input_tensor.GetDequantizedData();
std::vector<float> tmp_output_data(elements_count, 0.f);
FloatImpl(input_data.data(), tmp_output_data.data(), elements_count, param_a, param_b);
output_tensor.SetDequantizedData(tmp_output_data);
}
}
The above implementation can be compiled into a shared library based on the header files and shared library files provided by Converter Tool.
COMPILE_FLAG=$(python -c 'import mtk_converter; print(" ".join(mtk_converter.sysconfig.get_compile_flags()))')
LINK_FLAG=$(python -c 'import mtk_converter; print(" ".join(mtk_converter.sysconfig.get_link_flags()))')
# Assume that the source file is named `custom_op_impl.cpp`
g++ --shared custom_op_impl.cpp -o libcustom_op_impl.so -fPIC $COMPILE_FLAG $LINK_FLAG
With the custom operator implementation library, we can execute the converted TFLite model.
|
Note: |
|
Users must set the LD_LIBRARY_PATH to the library location. Otherwise, Converter Tool will fail to find the shared library. |
import mtk_converter
import numpy as np
# Create random int8 data
input_data = np.random.randint(-128, 128, [1, 28, 28, 3], dtype=np.int8)
executor = mtk_converter.TFLiteExecutor('resolved_model.tflite', custom_op_lib_map={'CustomActivation': 'libcustom_op_impl.so'})
output_data = executor.run([input_data])[0]
4.1.1.4 Converter Tool Examples
This section provides some examples for using Converter Tool.
4.1.1.4.1 Converting from Caffe
4.1.1.4.1.1 Floating-Point
Download the Mobilenet V1 pre-trained floating-point model.
$ mkdir caffe_float_workspace && cd caffe_float_workspace
$ wget https://github.com/shicai/MobileNet-Caffe/archive/refs/heads/master.zip
$ unzip -j master.zip
$ upgrade_net_proto_text mobilenet_deploy.prototxt mobilenet_deploy.prototxt
$ upgrade_net_proto_binary mobilenet.caffemodel mobilenet.caffemodel
Convert the model using the command-line executable.
$ mtk_caffe_converter \
--input_prototxt_file=mobilenet_deploy.prototxt \
--input_caffemodel_file=mobilenet.caffemodel \
--output_file=mobilenet_v1_float.tflite
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.CaffeConverter.from_model_files(
'mobilenet_deploy.prototxt', 'mobilenet.caffemodel'
)
_ = converter.convert_to_tflite(output_file='mobilenet_v1_float.tflite')
The output TFLite model file is stored as mobilenet_v1_float.tflite.
4.1.1.4.1.2 Floating-Point (with NHWC Input/Output Tensors)
The TFLite model generated from the above example has two Transpose operators: one at the model input side, and the other at the model output side. These two operators are used to convert the input data from NCHW to NHWC, and convert the output data from NHWC back to NCHW because MediaTek platforms prefer NHWC data during computation.
If users want to pass NHWC input data directly to avoid the overhead caused by these Transpose operators, we recommend that users modify the Caffe model by adding two additional Permute layers to make the model accept NHWC input and produce NHWC output.
import caffe
from caffe.proto import caffe_pb2
from google.protobuf import text_format
caffe_net = caffe_pb2.NetParameter()
with open('mobilenet_deploy.prototxt', 'r') as f:
text_format.Merge(f.read(), caffe_net)
# Change input layer to NHWC format
input_layer = caffe_net.layer[0]
input_layer.top[0] = 'data_nhwc'
input_layer.input_param.shape[0].dim[:] = [1, 224, 224, 3]
# Insert the input-side Permute layer to convert input data from NHWC to NCHW
input_permute_layer = caffe_net.layer.add()
input_permute_layer.CopyFrom(caffe.layers.Permute(order=[0, 3, 1, 2]).to_proto().layer[0])
input_permute_layer.name = 'input_permute'
input_permute_layer.bottom[:] = ['data_nhwc']
input_permute_layer.top[:] = ['data']
# Insert the output-side Permute layer to convert input data from NCHW to NHWC
output_permute_layer = caffe_net.layer.add()
output_permute_layer.CopyFrom(caffe.layers.Permute(order=[0, 2, 3, 1]).to_proto().layer[0])
output_permute_layer.name = 'output_permute'
output_permute_layer.bottom[:] = ['prob']
output_permute_layer.top[:] = ['prob_nhwc']
# Reorder the layers to guarantee topological order
new_layers = [
caffe_net.layer[0], caffe_net.layer[-2], *caffe_net.layer[1:-2], caffe_net.layer[-1]
]
del caffe_net.layer[:]
caffe_net.layer.extend(new_layers)
with open('mobilenet_deploy_nhwc.prototxt', 'w') as f:
f.write(text_format.MessageToString(caffe_net))
Convert the model using the command-line executable. With these additional Permute layers, we can remove the input-side and output-side Transpose operators after conversion.
$ mtk_caffe_converter \
--input_prototxt_file=mobilenet_deploy_nhwc.prototxt \
--input_caffemodel_file=mobilenet.caffemodel \
--output_file=mobilenet_v1_float_nhwc.tflite
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.CaffeConverter.from_model_files(
'mobilenet_deploy_nhwc.prototxt', 'mobilenet.caffemodel'
)
_ = converter.convert_to_tflite(output_file='mobilenet_v1_float_nhwc.tflite')
4.1.1.4.1.3 Post-Training Quantization
Download the Mobilenet V1 pre-trained floating-point model.
$ mkdir caffe_ptq_workspace && cd caffe_ptq_workspace
$ wget https://github.com/shicai/MobileNet-Caffe/archive/refs/heads/master.zip
$ unzip -j master.zip
$ upgrade_net_proto_text mobilenet_deploy.prototxt mobilenet_deploy.prototxt
$ upgrade_net_proto_binary mobilenet.caffemodel mobilenet.caffemodel
Convert the model to TFLite using the command-line executable. For simplicity, we use random data to do post-training quantization. In real cases, these data files should be extracted from the training dataset, such as ImageNet.
import os
import numpy as np
os.mkdir('data')
for i in range(100):
data = np.random.randn(1, 3, 224, 224).astype(np.float32)
np.save('data/batch_{}.npy'.format(i), data)
$ mtk_caffe_converter \
--input_prototxt_file=mobilenet_deploy.prototxt \
--input_caffemodel_file=mobilenet.caffemodel \
--output_file=mobilenet_v1_ptq_quant.tflite \
--quantize=True \
--input_value_ranges=-1,1 \
--calibration_data_dir=data/ \
--calibration_data_regexp=batch_.*\.npy
Or convert the model using the Python API.
import mtk_converter
import numpy as np
def data_gen():
for i in range(100):
yield [np.random.randn(1, 3, 224, 224).astype(np.float32)]
converter = mtk_converter.CaffeConverter.from_model_files(
'mobilenet_deploy.prototxt', 'mobilenet.caffemodel'
)
converter.quantize = True
converter.input_value_ranges = [(-1.0, 1.0)]
converter.calibration_data_gen = data_gen
_ = converter.convert_to_tflite(output_file='mobilenet_v1_ptq_quant.tflite')
The output TFLite model file is stored as mobilenet_v1_ptq_quant.tflite.
|
Note: |
|
The value of input_value_ranges depends on the actual dataset distribution. If this value is not set, the input value ranges will be deduced from the provided calibration dataset. |
4.1.1.4.1.4 Post-Training Dynamic Quantization
Download the Mobilenet V1 pre-trained floating-point model.
$ mkdir caffe_dynamic_quant_workspace && cd caffe_dynamic_quant_workspace
$ wget https://github.com/shicai/MobileNet-Caffe/archive/refs/heads/master.zip
$ unzip -j master.zip
$ upgrade_net_proto_text mobilenet_deploy.prototxt mobilenet_deploy.prototxt
$ upgrade_net_proto_binary mobilenet.caffemodel mobilenet.caffemodel
Convert the floating-point model to TFLite with dynamic quantization using the command-line executable. With this method, the convolution weights are quantized while other tensors are kept as floating-point data types. The input tensors of the convolution operator are quantized dynamically during inference.
$ mtk_caffe_converter \
--input_prototxt_file=mobilenet_deploy.prototxt \
--input_caffemodel_file=mobilenet.caffemodel \
--output_file=mobilenet_v1_dynamic_quant.tflite \
--input_quantization_bitwidths="" \
--default_weights_quantization_bitwidth=8 \
--allow_dynamic_quantization=True \
--allow_missing_quantization_ranges=True \
--quantize=True
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.CaffeConverter.from_model_files(
'mobilenet_deploy.prototxt', 'mobilenet.caffemodel'
)
converter.input_quantization_bitwidths = None
converter.default_weights_quantization_bitwidth = 8
converter.allow_dynamic_quantization = True
converter.allow_missing_quantization_ranges = True
converter.quantize = True
_ = converter.convert_to_tflite(output_file='mobilenet_v1_dynamic_quant.tflite')
The output TFLite model file is stored as mobilenet_v1_dynamic_quant.tflite.
|
Note: |
|
We keep all the activation tensors as floating-point data types, so we should set the allow_missing_quantization_ranges converter option. |
4.1.1.4.2 Converting from TensorFlow V1
4.1.1.4.2.1 Floating-Point
Download the Mobilenet V1 pre-trained floating-point model.
$ mkdir tf_float_workspace && cd tf_float_workspace
$ wget http://download.tensorflow.org/models/mobilenet_v1_2018_02_22/mobilenet_v1_1.0_224.tgz
$ tar xvf mobilenet_v1_1.0_224.tgz
Convert the model using the command-line executable.
$ mtk_tensorflow_v1_converter \
--input_frozen_graph_def_file=mobilenet_v1_1.0_224_frozen.pb \
--output_file=mobilenet_v1_float.tflite \
--input_names=input \
--input_shapes=1,224,224,3 \
--output_names=MobilenetV1/Predictions/Reshape_1
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.TensorFlowV1Converter.from_frozen_graph_def_file(
'mobilenet_v1_1.0_224_frozen.pb',
['input'],
[[1, 224, 224, 3]],
['MobilenetV1/Predictions/Reshape_1']
)
_ = converter.convert_to_tflite(output_file='mobilenet_v1_float.tflite')
The output TFLite model file is stored as mobilenet_v1_float.tflite.
4.1.1.4.2.2 Quantization-Aware Training
Download the Mobilenet V1 pre-trained model with the official TensorFlow quantization-aware training tool.
$ mkdir tf_qat_workspace && cd tf_qat_workspace
$ wget https://storage.googleapis.com/download.tensorflow.org/models/mobilenet_v1_2018_08_02/mobilenet_v1_1.0_224_quant.tgz
$ tar xvf mobilenet_v1_1.0_224_quant.tgz
Convert the model using the command-line executable.
$ mtk_tensorflow_v1_converter \
--input_frozen_graph_def_file=mobilenet_v1_1.0_224_quant_frozen.pb \
--output_file=mobilenet_v1_qat_quant.tflite \
--input_names=input \
--input_shapes=1,224,224,3 \
--output_names=MobilenetV1/Predictions/Reshape_1 \
--quantize=True \
--input_value_ranges=-1,1
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.TensorFlowV1Converter.from_frozen_graph_def_file(
'mobilenet_v1_1.0_224_quant_frozen.pb',
['input'],
[[1, 224, 224, 3]],
['MobilenetV1/Predictions/Reshape_1']
)
converter.quantize = True
converter.input_value_ranges = [(-1.0, 1.0)]
_ = converter.convert_to_tflite(output_file='mobilenet_v1_qat_quant.tflite')
The output TFLite model file is stored as mobilenet_v1_qat_quant.tflite.
|
Note: |
|
The value of input_value_ranges depends on the actual dataset distribution. |
4.1.1.4.2.3 Post-Training Quantization
Download the Mobilenet V1 pre-trained floating-point model.
$ mkdir tf_ptq_workspace && cd tf_ptq_workspace
$ wget http://download.tensorflow.org/models/mobilenet_v1_2018_02_22/mobilenet_v1_1.0_224.tgz
$ tar xvf mobilenet_v1_1.0_224.tgz
Convert the model to TFLite using the command-line executable. For simplicity, we use random data to do post-training quantization. In real cases, these data files should be extracted from the training dataset, such as ImageNet.
import os
import numpy as np
os.mkdir('data')
for i in range(100):
data = np.random.randn(1, 224, 224, 3).astype(np.float32)
np.save('data/batch_{}.npy'.format(i), data)
$ mtk_tensorflow_v1_converter \
--input_frozen_graph_def_file=mobilenet_v1_1.0_224_frozen.pb \
--output_file=mobilenet_v1_ptq_quant.tflite \
--input_names=input \
--input_shapes=1,224,224,3 \
--output_names=MobilenetV1/Predictions/Reshape_1 \
--quantize=True \
--input_value_ranges=-1,1 \
--calibration_data_dir=data/ \
--calibration_data_regexp=batch_.*\.npy
Or convert the model using the Python API.
import mtk_converter
import numpy as np
def data_gen():
for i in range(100):
yield [np.random.randn(1, 224, 224, 3).astype(np.float32)]
converter = mtk_converter.TensorFlowV1Converter.from_frozen_graph_def_file(
'mobilenet_v1_1.0_224_frozen.pb',
['input'],
[[1, 224, 224, 3]],
['MobilenetV1/Predictions/Reshape_1']
)
converter.quantize = True
converter.input_value_ranges = [(-1.0, 1.0)]
converter.calibration_data_gen = data_gen
_ = converter.convert_to_tflite(output_file='mobilenet_v1_ptq_quant.tflite')
The output TFLite model file is stored as mobilenet_v1_ptq_quant.tflite.
|
Note: |
|
The value of input_value_ranges depends on the actual dataset distribution. If this value is not set, the input value ranges will be deduced from the provided calibration dataset. |
4.1.1.4.2.4 Post-Training Dynamic Quantization
Download the Mobilenet V1 pre-trained floating-point model.
$ mkdir tf_dynamic_quant_workspace && cd tf_dynamic_quant_workspace
$ wget http://download.tensorflow.org/models/mobilenet_v1_2018_02_22/mobilenet_v1_1.0_224.tgz
$ tar xvf mobilenet_v1_1.0_224.tgz
Convert the floating-point model to TFLite with dynamic quantization using the command-line executable. With this method, the convolution weights are quantized while other tensors are kept as floating-point data types. The input tensors of the convolution operator are quantized dynamically during inference.
$ mtk_tensorflow_v1_converter \
--input_frozen_graph_def_file=mobilenet_v1_1.0_224_frozen.pb \
--output_file=mobilenet_v1_dynamic_quant.tflite \
--input_names=input \
--input_shapes=1,224,224,3 \
--output_names=MobilenetV1/Predictions/Reshape_1 \
--input_quantization_bitwidths="" \
--default_weights_quantization_bitwidth=8 \
--allow_dynamic_quantization=True \
--allow_missing_quantization_ranges=True \
--quantize=True
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.TensorFlowV1Converter.from_frozen_graph_def_file(
'mobilenet_v1_1.0_224_frozen.pb',
['input'],
[[1, 224, 224, 3]],
['MobilenetV1/Predictions/Reshape_1']
)
converter.input_quantization_bitwidths = None
converter.default_weights_quantization_bitwidth = 8
converter.allow_dynamic_quantization = True
converter.allow_missing_quantization_ranges = True
converter.quantize = True
_ = converter.convert_to_tflite(output_file='mobilenet_v1_dynamic_quant.tflite')
The output TFLite model file is stored as mobilenet_v1_dynamic_quant.tflite.
|
Note: |
|
We keep all the activation tensors as floating-point data types, so we should set the allow_missing_quantization_ranges converter option. |
4.1.1.4.3 Converting from TensorFlow V2
The following example is extended from the TensorFlow classification example.
4.1.1.4.3.1 Model Preparation
The following directories are created for this example.
$ mkdir workspace/float workspace/qat workspace/ptq workspace/ptq_dynamic
We first train the float-point model based on the MNIST dataset.
import tensorflow as tf
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images / 255.0
model = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28)),
tf.keras.layers.Reshape(target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
]
)
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
model.fit(train_images, train_labels, epochs=10)
model.save('./workspace/float/model', save_format='tf')
Next, we do quantization-aware training based on the above floating-point model.
import tensorflow as tf
import tensorflow_model_optimization as tfmot
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images / 255.0
train_images_subset = train_images[0:1000]
train_labels_subset = train_labels[0:1000]
model = tf.keras.models.load_model('./workspace/float/model')
q_aware_model = tfmot.quantization.keras.quantize_model(model)
q_aware_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
q_aware_model.fit(
train_images_subset,
train_labels_subset,
batch_size=500,
epochs=1,
validation_split=0.1
)
q_aware_model.save('./workspace/qat/model', save_format='tf')
4.1.1.4.3.2 Floating-Point
Convert the model using the command-line executable.
$ mtk_tensorflow_converter \
--input_saved_model_dir=workspace/float/model \
--output_file=workspace/float/model.tflite \
--default_batch_size=1
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.TensorFlowConverter.from_saved_model_dir(
'./workspace/float/model', default_batch_size=1
)
_ = converter.convert_to_tflite(output_file='./workspace/float/model.tflite')
The output TFLite model file is stored as ./workspace/float/model.tflite.
|
Note: |
|
We set the default_batch_size argument, because a dynamic batch size is used by default in tf.keras.layers.InputLayer. |
4.1.1.4.3.3 Quantization-Aware Training
Convert the above fake-quantized model using the command-line executable.
$ mtk_tensorflow_converter \
--input_saved_model_dir=workspace/qat/model \
--output_file=workspace/qat/model.tflite \
--default_batch_size=1 \
--quantize=True
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.TensorFlowConverter.from_saved_model_dir(
'./workspace/qat/model', default_batch_size=1
)
converter.quantize = True
_ = converter.convert_to_tflite(output_file='./workspace/qat/model.tflite')
The output TFLite model file is stored as ./workspace/qat/model.tflite.
|
Note: |
|
We set the default_batch_size argument, because a dynamic batch size is used by default in tf.keras.layers.InputLayer. |
|
Note: |
|
The input quantization range was already deduced by the quantization-aware training process, so we do not set the input_value_ranges option. |
4.1.1.4.3.4 Post-Training Quantization
Convert the above floating-point model to TFLite with post-training quantization.
We first store the data used for post-training quantization.
import os
import tensorflow as tf
import numpy as np
(train_images, _), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images / 255.0
os.mkdir('./workspace/ptq/data')
for i in range(100):
batch_data = train_images[i:i+1].astype(np.float32)
np.save('./workspace/ptq/data/batch_{}.npy'.format(i), batch_data)
Convert the model using the command-line executable.
$ mtk_tensorflow_converter \
--input_saved_model_dir=workspace/float/model \
--output_file=workspace/ptq/model.tflite \
--default_batch_size=1 \
--calibration_data_dir=workspace/ptq/data \
--calibration_data_regexp=batch_.*\.npy \
--input_value_ranges=0,1 \
--quantize=True
Or convert the model using the Python API.
import mtk_converter
import tensorflow as tf
import numpy as np
(train_images, _), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images / 255.0
def data_gen():
for i in range(100):
batch_data = train_images[i:i+1].astype(np.float32)
yield [batch_data]
converter = mtk_converter.TensorFlowConverter.from_saved_model_dir(
'./workspace/float/model', default_batch_size=1
)
converter.quantize = True
converter.input_value_ranges=[(0.0, 1.0)]
converter.calibration_data_gen = data_gen
_ = converter.convert_to_tflite(output_file='./workspace/ptq/model.tflite')
The output TFLite model file is stored as ./workspace/ptq/model.tflite.
|
Note: |
|
We set the default_batch_size argument, because a dynamic batch size is used by default in tf.keras.layers.InputLayer. |
|
Note: |
|
The input_value_ranges argument value depends on the actual dataset distribution. If not provided, the input value ranges will be deduced from the given calibration dataset. |
4.1.1.4.3.5 Post-Training Dynamic Quantization
Convert the floating-point model to TFLite with dynamic quantization using the command-line executable. With this method, the convolution weights are quantized while other tensors are kept as floating-point data types. The input tensors of the convolution operator are quantized dynamically during inference.
$ mtk_tensorflow_converter \
--input_saved_model_dir=workspace/float/model \
--output_file=workspace/ptq_dynamic/model.tflite \
--default_batch_size=1 \
--input_quantization_bitwidths="" \
--default_weights_quantization_bitwidth=8 \
--allow_dynamic_quantization=True \
--allow_missing_quantization_ranges=True \
--quantize=True
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.TensorFlowConverter.from_saved_model_dir(
'./workspace/float/model', default_batch_size=1
)
converter.quantize = True
converter.input_quantization_bitwidths = None
converter.default_weights_quantization_bitwidth = 8
converter.allow_dynamic_quantization = True
converter.allow_missing_quantization_ranges = True
_ = converter.convert_to_tflite(output_file='./workspace/ptq_dynamic/model.tflite')
The output TFLite model file is stored as ./workspace/ptq_dynamic/model.tflite.
|
Note: |
|
We keep all the activation tensors as floating-point data types, so we should set the allow_missing_quantization_ranges converter option. |
4.1.1.4.4 Converting from PyTorch
4.1.1.4.4.1 Floating-Point
Download the Mobilenet V2 pre-trained floating-point model. Then prepare for conversion by generating a ScriptModule object using the torch.jit.trace API.
import torch
import torchvision
model = torchvision.models.mobilenet_v2(pretrained=True)
trace_data = torch.randn(1, 3, 224, 224)
trace_model = torch.jit.trace(model.cpu().eval(), (trace_data))
torch.jit.save(trace_model, 'mobilenet_v2_float.pt')
Convert the model using the command-line executable.
$ mtk_pytorch_converter \
--input_script_module_file=mobilenet_v2_float.pt \
--output_file=mobilenet_v2_float.tflite \
--input_shapes=1,3,224,224
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.PyTorchConverter.from_script_module_file(
'mobilenet_v2_float.pt', [[1, 3, 224, 224]]
)
_ = converter.convert_to_tflite(output_file='mobilenet_v2_float.tflite')
The output TFLite model file is stored as mobilenet_v2_float.tflite.
4.1.1.4.4.2 Floating-Point (with NHWC Input/Output Tensors)
The TFLite model generated from the above example has a Transpose operator at the model input side. This is to convert the input data from NCHW format into NHWC format, which MediaTek platforms prefer. If users want to pass NHWC input data directly and avoid the overhead caused by this Transpose operator, we recommend that users wrap the PyTorch model and accept NHWC input directly.
In the following example, we wrap the MobileNet V2 model and use NHWC as the model input format.
import torch
import torchvision
model = torchvision.models.mobilenet_v2(pretrained=True)
class NhwcWrapper(torch.nn.Module):
def __init__(self, model):
super(NhwcWrapper, self).__init__()
self._model = model
def forward(self, input_tensor):
nchw_input_tensor = input_tensor.permute(0, 3, 1, 2)
return self._model(nchw_input_tensor)
nhwc_model = NhwcWrapper(model)
trace_data = torch.randn(1, 224, 224, 3)
trace_model = torch.jit.trace(nhwc_model.cpu().eval(), (trace_data))
torch.jit.save(trace_model, 'mobilenet_v2_float_nhwc_input.pt')
|
Note: |
|
In this example, the NhwcWrapper class handles only the input tensor data format because the model outputs a 2-dimensional tensor. To handle the output tensor data format, the user needs to do extra permutations on the model output tensor. For example:
|
Convert the model using the command-line executable. With this wrapper class, we can remove the input-side Transpose operator after conversion.
$ mtk_pytorch_converter \
--input_script_module_file=mobilenet_v2_float_nhwc_input.pt \
--output_file=mobilenet_v2_float_nhwc_input.tflite \
--input_shapes=1,224,224,3
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.PyTorchConverter.from_script_module_file(
'mobilenet_v2_float_nhwc_input.pt', [[1, 224, 224, 3]]
)
_ = converter.convert_to_tflite(output_file='mobilenet_v2_float_nhwc_input.tflite')
4.1.1.4.4.3 Post-Training Quantization
Download the Mobilenet V1 pre-trained floating-point model. Then prepare for conversion by generating a ScriptModule object using the torch.jit.trace API.
import torch
import torchvision
model = torchvision.models.mobilenet_v2(pretrained=True)
trace_data = torch.randn(1, 3, 224, 224)
trace_model = torch.jit.trace(model.cpu().eval(), (trace_data))
torch.jit.save(trace_model, 'mobilenet_v2_float.pt')
Convert the model to TFLite using the command-line executable. For simplicity, we use random data to do post-training quantization. In real cases, these data files should be extracted from the training dataset, such as ImageNet.
import os
import numpy as np
os.mkdir('data')
for i in range(100):
data = np.random.randn(1, 3, 224, 224).astype(np.float32)
np.save('data/batch_{}.npy'.format(i), data)
$ mtk_pytorch_converter \
--input_script_module_file=mobilenet_v2_float.pt \
--output_file=mobilenet_v2_ptq_quant.tflite \
--input_shapes=1,3,224,224 \
--quantize=True \
--input_value_ranges=-1,1 \
--calibration_data_dir=data/ \
--calibration_data_regexp=batch_.*\.npy
Or convert the model using the Python API.
import mtk_converter
import numpy as np
def data_gen():
for i in range(100):
yield [np.random.randn(1, 3, 224, 224).astype(np.float32)]
converter = mtk_converter.PyTorchConverter.from_script_module_file(
'mobilenet_v2_float.pt', [[1, 3, 224, 224]],
)
converter.quantize = True
converter.input_value_ranges = [(-1.0, 1.0)]
converter.calibration_data_gen = data_gen
_ = converter.convert_to_tflite(output_file='mobilenet_v2_ptq_quant.tflite')
The output TFLite model file is stored as mobilenet_v2_ptq_quant.tflite.
|
Note: |
|
The value of input_value_ranges depends on the actual dataset distribution. If this value is not set, the input value ranges will be deduced from the provided calibration dataset. |
4.1.1.4.4.4 Post-Training Dynamic Quantization
Download the Mobilenet V1 pre-trained floating-point model. Then prepare for conversion by generating a ScriptModule object using the torch.jit.trace API.
import torch
import torchvision
model = torchvision.models.mobilenet_v2(pretrained=True)
trace_data = torch.randn(1, 3, 224, 224)
trace_model = torch.jit.trace(model.cpu().eval(), (trace_data))
torch.jit.save(trace_model, 'mobilenet_v2_float.pt')
Convert the floating-point model to TFLite with dynamic quantization using the command-line executable. With this method, the convolution weights are quantized while other tensors are kept as floating-point data types. The input tensors of the convolution operator are quantized dynamically during inference.
$ mtk_pytorch_converter \
--input_script_module_file=mobilenet_v2_float.pt \
--output_file=mobilenet_v2_dynamic_quant.tflite \
--input_shapes=1,3,224,224 \
--input_quantization_bitwidths="" \
--default_weights_quantization_bitwidth=8 \
--allow_dynamic_quantization=True \
--allow_missing_quantization_ranges=True \
--quantize=True
Or convert the model using the Python API.
import mtk_converter
converter = mtk_converter.PyTorchConverter.from_script_module_file(
'mobilenet_v2_float.pt', [[1, 3, 224, 224]],
)
converter.input_quantization_bitwidths = None
converter.default_weights_quantization_bitwidth = 8
converter.allow_dynamic_quantization = True
converter.allow_missing_quantization_ranges = True
converter.quantize = True
_ = converter.convert_to_tflite(output_file='mobilenet_v2_dynamic_quant.tflite')
The output TFLite model file is stored as mobilenet_v2_dynamic_quant.tflite.
|
Note: |
|
We keep all the activation tensors as floating-point data types, so we should set the allow_missing_quantization_ranges converter option. |
4.1.1.4.5 Executing the TFLite Model After Conversion
Users can verify the converted TFLite model by executing the model using the reference operator implementations provided by Converter Tool. For example, the TFLiteExecutor class.
|
Note: |
|
The execution result from the reference operator implementation is not guaranteed to be identical to the execution result from a real device. This is because the execution process of a quantized operator contains many approximation steps, and different operator implementations might use different approximation methods. |
4.1.1.4.5.1 Executing a Float TFLite Model
In this section, we execute the TFLite model produced in the 4.1.1.4.4.1. Floating-Point example.
import mtk_converter
import numpy as np
# Create a TFLiteExecutor
executor = mtk_converter.TFLiteExecutor('mobilenet_v1_float.tflite')
# A list of numpy random array as inputs
inputs = [np.random.normal(size=(1, 224, 224, 3)).astype(np.float32)]
# Return a list of outputs
outputs = executor.run(inputs)
# Output has shape (1, 1001)
assert outputs[0].shape == (1, 1001)
4.1.1.4.5.2 Execute a Quantized TFLite Model
In this section, we execute the TFLite model produced in the 4.1.1.4.3.3. Quantization-Aware Training example.
When calling executor.run, we set quantize_input to True to quantize the float inputs and set dequantize_output to True to get float outputs.
import mtk_converter
import numpy as np
# Create a TFLiteExecutor
executor = mtk_converter.TFLiteExecutor('mobilenet_v1_qat_quant.tflite')
# A list of numpy random array as inputs
inputs = [np.random.normal(size=(1, 224, 224, 3)).astype(np.float32)]
# Return a list of outputs
outputs = executor.run(inputs, quantize_input=True, dequantize_output=True)
# Output has shape (1, 1001) and float type
assert outputs[0].shape == (1, 1001)
assert outputs[0].dtype == np.float32
4.1.1.5 Appendix – Reference Patterns for Composite Operators
In this section, we provide patterns used for commonly-used composite operators.
4.1.1.5.1 TensorFlow
4.1.1.5.1.1 Grouped Conv2D
def grouped_conv2d(x: Tensor, f: Tensor, groups: int, **kwargs) -> Tensor:
inputs = tf.split(x, groups, axis=3)
filters = tf.split(f, groups, axis=3)
outputs = [tf.nn.conv2d(i, f, **kwargs) for i, f in zip(inputs, filters)]
out = tf.concat(outputs, axis=3)
return out
|
Note: |
|
kwargs is used to capture the conv2d arguments that should be passed to the tf.nn.conv2d API. |
|
Important: |
|
NeuroPilot only supports the NHWC data format for this pattern. |
4.1.1.5.1.2 HardSwish
def hard_swish(x: Tensor) -> Tensor:
return x * tf.nn.relu6(x + 3.0) * (1.0 / 6.0)
def hard_swish(x: Tensor) -> Tensor:
return x * tf.nn.relu6(x + 3.0) / 6.0
4.1.1.5.1.3 Instance Normalization
def instance_norm(x: Tensor, beta: Tensor, gamma: Tensor, epsilon: float) -> Tensor:
spatial_axes = ...
mean, variance = tf.nn.moments(x, spatial_axes, keep_dims=True)
mul_factor = gamma * tf.math.rsqrt(variance + epsilon)
add_factor = beta - mean * mul_factor
return x * mul_factor + add_factor
|
Note: |
|
After TensorFlow v2.0.0, the argument keep_dims of the tf.nn.moments API is replaced by keepdims . |
|
Note: |
|
The value of spatial_axes depends on the input tensor rank and the input data format. For example, if the input tensor is 4D and in NHWC format, the spatial_axes will have value [1, 2], which corresponds to the height and width dimensions. |
|
See also: |
|
In addition to the above pattern, the converter also supports the tf.contrib.layers.instance_norm and tfa.layers.InstanceNormalization API. |
4.1.1.5.1.4 MinPool2D
def min_pool2d(x: Tensor) -> Tensor:
ksize = ...
strides = ...
padding = ...
data_format = ...
return -(tf.nn.max_pool2d(-x, ksize, strides, padding, data_format=data_format))
4.1.1.5.1.5 PReLU
def prelu(x: Tensor, alpha: Tensor) -> Tensor:
pos = tf.nn.relu(x)
neg = -alpha * tf.nn.relu(-x)
return pos + neg
|
See also: |
|
In addition to the above pattern, the converter also supports the tf.keras.layers.PReLU layer. |
4.1.1.5.1.6 ReluN1To1
def relu_n1_to_1(x: Tensor) -> Tensor:
return tf.minimum(tf.maximum(x, -1.0), 1.0)
def relu_n1_to_1(x: Tensor) -> Tensor:
return tf.maximum(tf.minimum(x, 1.0), -1.0)
4.1.1.5.1.7 RoiAlign
def roi_align(
image_tensor,
boxes_tensor,
batch_indices_tensor,
output_size,
spatial_scales,
sampling_ratios
):
"""The TensorFlow implementation of RoiAlign.
Args:
image_tensor: A float32 tf.Tensor object. The 4D image tensor.
boxes_tensor: A float32 tf.Tensor object with shape `[num_boxes, 4]`. The coordinates of the
boxes. The coordinates are expressed as `[W1, H1, W2, H2]`.
batch_indices_tensor: An int32 tf.Tensor object with shape `[num_boxes]`. The batch indices
used by each of the boxes.
output_size: A list of two int values (height and width). The output size that the cropped
boxes will be resized to.
spatial_scales: A list of two float values (height and width). The scaling factors of each
spatial dimension that apply to the box coordinates.
sampling_ratios: A list of two int values (height and width). The number of sampling points
in each spatial dimension used to compute the output value.
Returns:
A float32 tf.Tensor object. The output tensor.
"""
scale_values = [spatial_scales[1], spatial_scales[0], spatial_scales[1], spatial_scales[0]]
scaled_boxes_tensor = boxes_tensor * tf.constant(scale_values, tf.float32)
w1h1, w2h2 = tf.split(scaled_boxes_tensor, 2, axis=-1)
# Force malformed ROIs to be 1x1
box_size_wh = tf.maximum(w2h2 - w1h1, tf.constant(1.0, dtype=tf.float32))
new_w2h2 = w1h1 + box_size_wh
samples_per_box = [output_size[1] * sampling_ratios[1], output_size[0] * sampling_ratios[0]]
grid_size_wh = box_size_wh / tf.constant(samples_per_box, dtype=tf.float32)
grid_wh_offset = 0.5 * grid_size_wh
grid_w1h1 = w1h1 + grid_wh_offset
grid_w1, grid_h1 = tf.split(grid_w1h1, 2, axis=1)
grid_w2h2 = new_w2h2 - grid_wh_offset
grid_w2, grid_h2 = tf.split(grid_w2h2, 2, axis=1)
image_shape = tf.shape(image_tensor)
_, image_h, image_w, _ = tf.split(image_shape, 4, axis=0)
norm_max_w = tf.cast(image_w - 1, tf.float32)
norm_max_h = tf.cast(image_h - 1, tf.float32)
norm_grid_h1 = grid_h1 / norm_max_h
norm_grid_w1 = grid_w1 / norm_max_w
norm_grid_h2 = grid_h2 / norm_max_h
norm_grid_w2 = grid_w2 / norm_max_w
new_boxes = tf.concat([norm_grid_h1, norm_grid_w1, norm_grid_h2, norm_grid_w2], axis=1)
new_output_size = [output_size[0] * sampling_ratios[0], output_size[1] * sampling_ratios[1]]
sample_out = tf.image.crop_and_resize(
image_tensor, new_boxes, batch_indices_tensor, new_output_size, 'bilinear'
)
# Extend the pooling parameter to a 4 elements
pool_param = [1, sampling_ratios[0], sampling_ratios[1], 1]
return tf.nn.avg_pool(sample_out, pool_param, pool_param, 'VALID')
|
Note: |
|
The value of sampling_ratio must be larger than 0. That is, the above pattern does not support adaptive sampling ratio. |
|
Note: |
|
The coordinates of the boxes must not go out-of-bound. For each box, the coordinates should satisfy W1 <= W2 and H1 <= H2. |
|
Note: |
|
If the boxes_tensor is a constant tensor, the above pattern will not be resolved as a single RoiAlign operator. Instead, they will be resolved to a CropAndResize operator and a AveragePool2D operator. |
4.1.1.5.1.8 GELU
This is an approximated version of the GELU (Gaussian Error Linear Units) activation function that is supported by MediaTek platforms. This approximation is suggested by the original GELU paper
def gelu(x: Tensor) -> Tensor:
return x * tf.nn.sigmoid(1.702 * x)
|
Note: |
|
Converter Tool does not recognize composite operators generated by the official TensorFlow GELU API (i.e., the tf.nn.gelu function). We recommend using the above pattern for better performance on MediaTek platforms. |
4.1.1.5.2 PyTorch
4.1.1.5.2.1 DepthToSpace
This is the same as the tf.nn.depth_to_space API defined in TensorFlow.
def depth_to_space(x: Tensor, block_size: int) -> Tensor:
n, c, h, w = x.size()
x = x.view(n, block_size, block_size, c // (block_size**2), h, w)
x = x.permute([0, 3, 4, 1, 5, 2]).contiguous()
x = x.view(n, c // (block_size**2), h * block_size, w * block_size)
return x
|
Important: |
|
NeuroPilot only supports the NCHW data format for this pattern. |
|
Note: |
|
The PyTorch module torch.nn.PixelShuffle has very similar behavior. However, the order of how the channel pixels are grouped together is different. |
4.1.1.5.2.2 HardSwish
For PyTorch versions that do not have a built-in torch.nn.Hardswish module, users can use the following pattern to build the model.
from torch.nn import functional as F
def hard_swish(x: Tensor) -> Tensor:
return x * F.relu6(x + 3.0) / 6.0
from torch.nn import functional as F
def hard_swish(x: Tensor) -> Tensor:
return x * F.relu6(x + 3.0) * (1.0 / 6.0)
4.1.1.5.2.3 MinPool2D
from torch.nn import functional as F
def min_pool2d(x: Tensor) -> Tensor:
kernel_size = ...
stride = ...
padding = ...
dilation = 1
return -(F.max_pool2d(-x, kernel_size, stride, padding, dilation))
|
Note: |
|
The value of dilation must be equal to 1 or [1, 1] due to the importer limitation. |
4.1.1.5.2.4 ReluN1To1
def relu_n1_to_1(x: Tensor) -> Tensor:
return x.clamp(-1.0, 1.0)
from torch.nn import functional as F
def relu_n1_to_1(x: Tensor) -> Tensor:
return F.hardtanh(x, min_val=-1.0, max_val=1.0)
4.1.1.5.2.5 SpaceToDepth
This is the same as the tf.nn.space_to_depth API defined in TensorFlow.
def space_to_depth(x: Tensor, block_size: int) -> Tensor:
n, c, h, w = x.size()
x = x.view(n, c, h // block_size, block_size, w // block_size, block_size)
x = x.permute([0, 3, 5, 1, 2, 4]).contiguous()
x = x.view(n, c * (block_size**2), h // block_size, w // block_size)
return x
|
Important: |
|
NeuroPilot only supports NCHW data format for this pattern. |
4.1.1.5.2.6 GELU
This is an approximated version of GELU (Gaussian Error Linear Units) activation function that the MediaTek platforms support. This approximation is suggested by the original GELU paper
from torch.nn import functional as F
def gelu(x: Tensor) -> Tensor:
return x * F.sigmoid(1.702 * x)
|
Warning: |
|
Converter Tool will forcibly convert the operator produced by official PyTorch GELU module (i.e., the torch.nn.GELU class) to the above approximated version for better performance on MediaTek platforms. |
4.1.1.6 Appendix – Integrate with Custom Quantization-aware Training Tools
Converter Tool supports both the official TensorFlow quantization-aware training tool and NeuroPilot Quantization Tool. For users who are using a custom quantization-aware training tool for advanced quantization techniques or specific quantization use cases, the converter has introduced a common interface for both TensorFlow and PyTorch. By following the interface when exporting the quantization results, users can easily deploy their quantization results on MediaTek platforms.
In the current NeuroPilot SDK, the quantization parameters are coupled with the tensors in the graph, which are the input/output operand of each of the nodes.
4.1.1.6.1 TensorFlow
The documentation in this section is based on the TensorFlow v1.x library. However, the same interface could be applied to TensorFlow 2.x and eager mode.
Converter Tool expects that the quantization result contains TensorFlow fakequant nodes, such as the FakeQuantWithMinMaxVars nodes. Both the min and max input scalar tensor of each fakequant node should come from a Const node (you can use tf.Variable and freeze the graph afterward).
The fakequant nodes should be inserted after tensors where the minimum and maximum values are provided by the custom quantization-aware training tools. The num_bits attribute in the fakequant nodes controls the quantization type of the resulting model. Currently, only one fakequant node can be inserted after a single tensor, and the fakequant node must be the only consumer of the tensor.
4.1.1.6.1.1 Per-Channel Quantization
MediaTek platforms only support per-channel quantization on the output channel dimension of the constant weight tensor for the Conv2D, DepthwiseConv2D, FullyConnected, and TransposeConv2D nodes. However, the per-channel fakequant node FakeQuantWithMinMaxVarsPerChannel only supports quantization on the last dimension of the input tensor. There, we might need to add extra Transpose or Reshape nodes to ensure that the fakequant node takes effect on the correct dimension.
- For the Conv2D node, the output channel of the weight tensor is in the last dimension. Therefore, no extra nodes are required.
- For the DepthwiseConv2dNative node, the output channel of the weight tensor is combined from the last two dimensions. Therefore, we need to insert a Reshape node to flatten the last two dimensions, add the fakequant node, and insert another Reshape node to un-flatten these two dimensions.
- For the Conv2DBackpropInput node, the output channel of the weight tensor is in the third dimensions. Therefore, we need to insert a Transpose node to switch the last two dimensions, add the fakequant node, and insert another Transpose node to switch these two dimensions back.
4.1.1.6.1.2 Batchnorm Folding
The TensorFlow FusedBatchNorm node is folded into preceding convolutional node during the model conversion process. This changes the weight values and affects the minimum and maximum values deduced from the custom quantization-aware training tool. As a result, we strongly recommend that users implement batchnorm folding before applying the quantization-aware training tool. This is also recommended by the TensorFlow official quantization-aware training tool. A reference implementation of batchnorm folding can be found in the TensorFlow repository.
4.1.1.6.1.3 Missing Fakequant Nodes
Converter Tool requires that each fakequant node provide the quantization information (i.e. quantization minimum and maximum range, bitwidth) of the tensor that the fakequant node applies to. If a tensor does not have a following fakequant node, Converter Tool will try to deduce the quantization information. Possible approaches include:
- For nodes that do not involve computation or the computation would hardly change the value range, the minimum and maximum range of the output tensor can be propagated from the input tensor.
- For constant tensors, the minimum and maximum range can be calculated directly from the tensor content.
- For other cases, the minimum and maximum range can be deduced from the provided dataset during the conversion process.
|
Warning: |
|
If Converter Tool is unable to obtain quantization information for a tensor, the tensor will not be quantized. It will be left as a floating-point type in the resulting model. |
4.1.1.6.1.4 Data Type and Asymmetric/Symmetric Quantization
The num_bits attribute in the fakequant nodes determines the data type of the resulting model.
- If the num_bits attribute is in the range [9, 16], it will be expressed with INT16 type. In this case, Converter Tool requires symmetric quantization parameters.
- If the num_bits attribute is in the range [2, 8], it will be expressed with either INT8 or UINT8 depending on the converter settings. In this case, Converter Tool accepts both symmetric and asymmetric quantization parameters.
|
Note: |
|
Weight tensors that will be quantized per-channel must have symmetric quantization parameters. To use symmetric quantization, users must set the narrow_range attribute to True, and ensure that the absolute values of min and max are the same. |
4.1.1.6.1.5 Example: Per-Tensor Quantization with Batch Normalization
This section provides a simple example for the custom quantization-aware training tool interface.
Consider the following model.
image = tf.placeholder(tf.float32, [None, 784], name='image')
with tf.variable_scope('model'):
layer1 = tf.contrib.layers.fully_connected(
image, num_outputs=128, activation_fn=tf.nn.relu,
normalizer_fn=tf.contrib.layers.batch_norm,
normalizer_params={'is_training': False, 'fused': True}
)
layer2 = tf.contrib.layers.fully_connected(
layer1, num_outputs=10, activation_fn=tf.nn.relu
)
output = tf.identity(layer2, name='output')
The model’s graph structure looks like this.
After the batchnorm folding process, the FusedBatchNorm node is folded into the preceding MatMul node. The graph structure now looks like this.
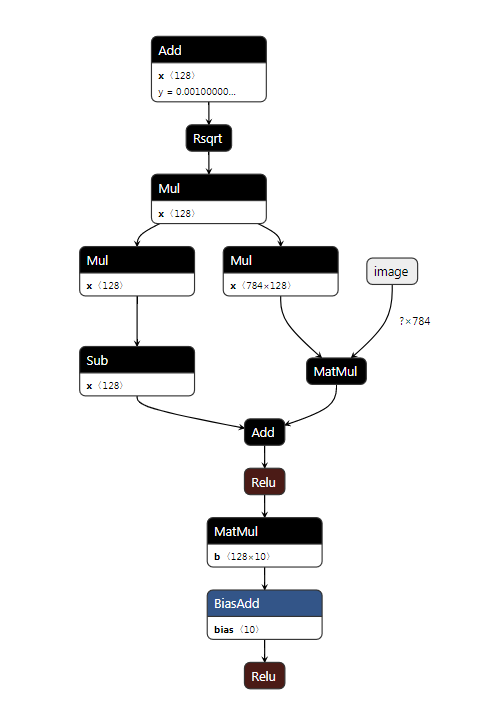
In this case, the custom quantization-aware training tool should provide the minimum and maximum value of the weight tensor and the output tensor of these two MatMul nodes. The following example code shows how to insert the fakequant node into the TensorFlow graph based on pre-defined minimum and maximum values.
from neuropilot.tfquantor import manual as quantor_module
import tensorflow as tf
# Minmax value produced by the custom quantization-aware training tool
#
# Seems the bias and relu will be folded into the preceding convolutional
# node after conversion, we just need the minmax value of the tensor after
# the activation node.
fakequant_minmax_values = {
'model/fully_connected/Relu': (-0.5, 1.3),
'model/fully_connected/mul_fold': (-1.8, 2.3),
'model/fully_connected_1/weights': (-0.03, 0.02),
'model/fully_connected_1/Relu': (-5.2, 6.6),
}
# Add fakequant nodes and fill in the minmax values
# Assuming the model is now the TensorFlow default graph
for target_node, (min_val, max_val) in fakequant_minmax_values.items():
target_tensor = tf.get_default_graph().get_tensor_by_name(target_node + ':0')
consumers = target_tensor.consumers()
fakequant_tensor = tf.fake_quant_with_min_max_vars(target_tensor, min_val, max_val)
if consumers:
tf.contrib.graph_editor.reroute_ts(fakequant_tensor, target_tensor, can_modify=consumers)
# Freeze the graph and export as GraphDef pb file
...
After the insertion is finished, the graph structure looks like the following image. From the graph, we can see that the minimum and maximum values of each fakequant node are the same as we provided.
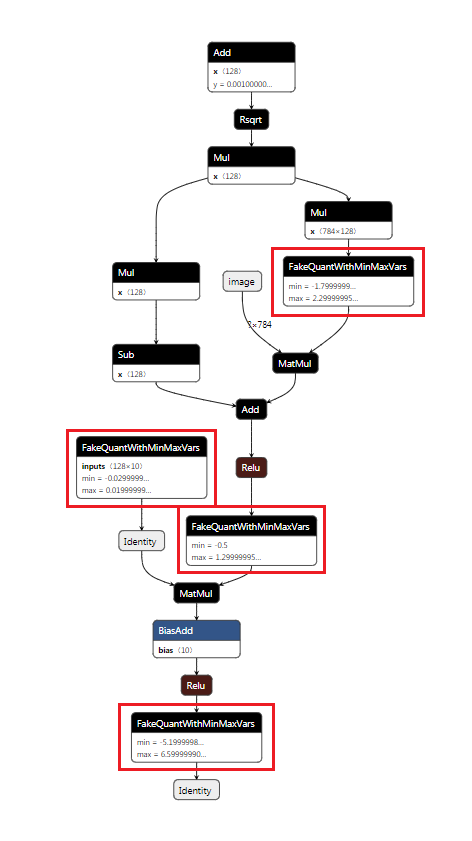
After following the above steps, the TensorFlow model can be converted to a quantized TFLite model. The resulting TFLite model looks like this.
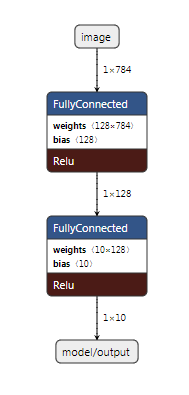
4.1.1.6.1.6 Example: Per-channel Quantization that Requires Extra Nodes Around FakeQuant Nodes
This section provides a simple example for the custom quantization-aware training tool interface.
Consider the following model.
image = tf.placeholder(tf.float32, [1, 28, 28, 3], name='image')
with tf.variable_scope('model'):
layer1 = tf.contrib.layers.separable_conv2d(
image, num_outputs=None, kernel_size=3, depth_multiplier=2, activation_fn=tf.nn.relu,
)
layer2 = tf.contrib.layers.conv2d_transpose(
layer1, num_outputs=10, kernel_size=3, activation_fn=tf.nn.relu
)
output = tf.identity(layer2, name='output')
The model’s graph structure looks like this.
The batchnorm folding process does not change the model.
After the fakequant insertion is finished, the graph structure looks like the following image. Note that there are some additional Reshape andTranspose nodes used to fit the constraint for the TensorFlow’s FakeQuantWithMinMaxVarsPerChannel node, as expressed in the above section.
Below is the DepthwiseConv2dNative node part. Two Reshape nodes are used around the weight tensor to merge the last two dimensions together.
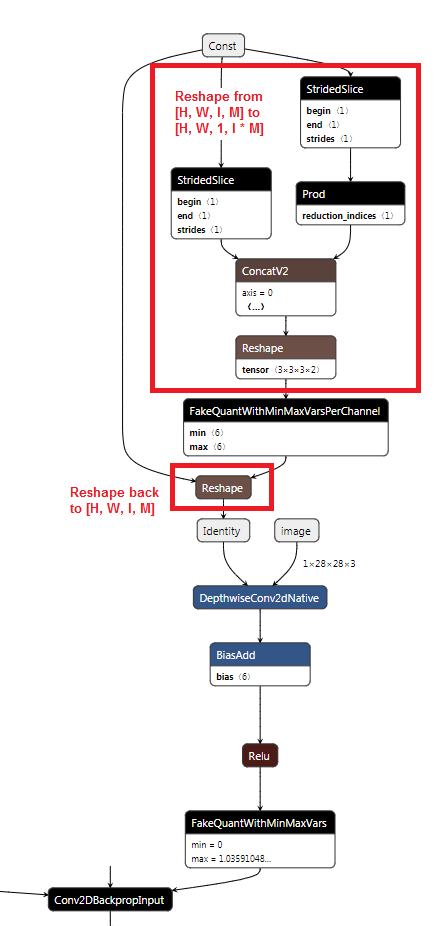
Below is the Conv2DBackpropInput node part. Two Transpose nodes are used around the weight tensor to swap the last two dimensions.
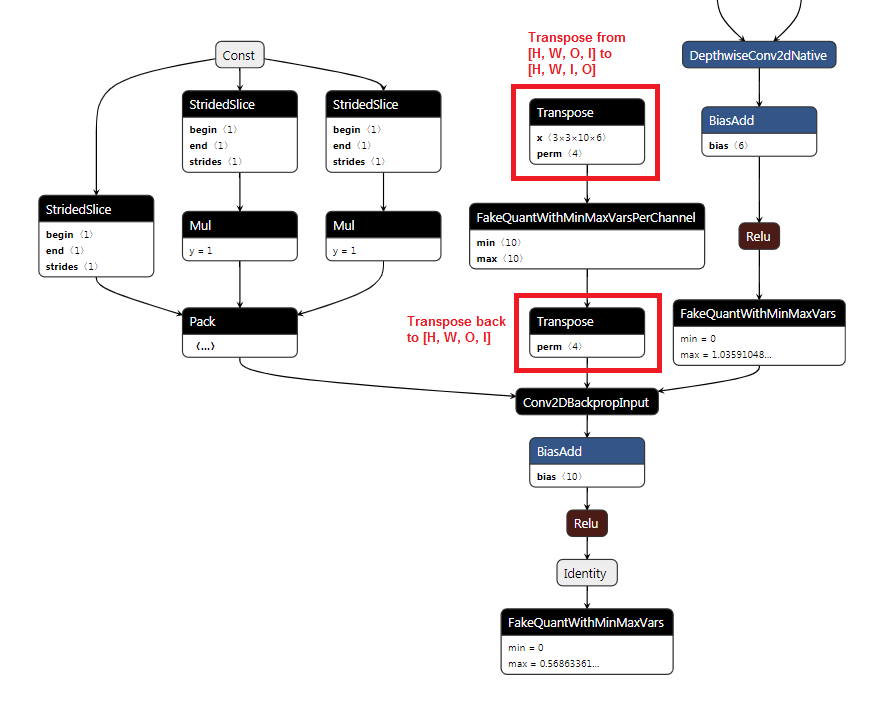
After the above steps, the TensorFlow model can be converted to a quantized TFLite model. The resulting TFLite model looks like this.
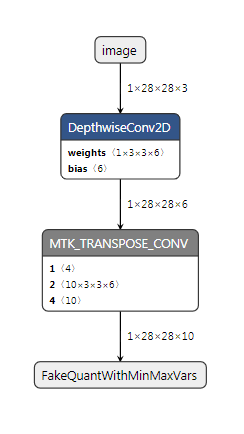
4.1.1.6.2 PyTorch
Converter Tool expects the quantization result to contain PyTorch fakequant nodes. The fakequant nodes can be inserted using torch.fake_quantize_per_tensor_affine or torch.fake_quantize_per_channel_affine API. Both the scale and zero_point arguments should be constant values or constant tensors.
Converter Tool uses the value of scale, zero_point, quant_min, and quant_max to deduce the bitwidth and the minimum and maximum range of the input tensor.
The fakequant nodes should be inserted after tensors where the minimum and maximum values are provided by the user-provided quantization methods. The quant_min and quant_max arguments control the bitwidth of the fakequant node. Currently, only one minimum and maximum value can be provided by a single tensor. Tensors that are inserted a following fakequant node should not have other consumers.
|
Note: |
|
The scale and zero_point argument must be a constant, a PyTorch module parameter, or a PyTorch module buffer. |
4.1.1.6.2.1 Value of quant_min and quant_max Arguments
Converter Tool accepts only a subset of the quant_min and quant_max values of the fakequant node. Valid quant_min and quant_max value pairs are listed below.
Valid quant_min and quant_max value pairs
|
quant_min value |
quant_max value |
Example (8-bit FakeQuantize operator) |
|
-1 * 2 ^ (num_bits - 1) |
2 ^ (num_bits - 1) - 1 |
(quant_min, quant_max) = (-128, 127) |
|
-1 * (2 ^ (num_bits - 1) - 1) |
2 ^ (num_bits - 1) - 1 |
(quant_min, quant_max) = (-127, 127) |
|
0 |
2 ^ num_bits - 1 |
(quant_min, quant_max) = (0, 255) |
|
Note: |
|
The value of quant_min and quant_max will not affect the signed/unsigned type of the quantization result. For example, passing (-128, 127) can sometimes produce uint8 quantization result. The behavior is controlled by the converter setting. |
4.1.1.6.2.2 Per-Channel Quantization
MediaTek platforms only support per-channel quantization on the output channel axis of the constant weight tensor for the Conv2D, DepthwiseConv2D, FullyConnected, and TransposeConv2D nodes.
- For convolution, the output channel of the weight tensor is in the first dimension (axis = 0).
- For depth-wise convolution, the output channel of the weight tensor is in the first dimension (axis = 0).
- For transposed convolution, the output channel of the weight tensor is in the second dimension (axis = 1). The groups attribute is not supported in this case.
4.1.1.6.2.3 Batchnorm Folding
The PyTorch batch normalization node is folded into preceding convolutional nodes during the model conversion process. This changes the weight values and affects the minimum and maximum values deduced from the custom quantization-aware training tool. As a result, we strongly recommend that users implement batchnorm folding before applying the quantization-aware training tool. This is also recommended by PyTorch when using their official quantization-aware training tool. A reference implementation of batchnorm folding can be found in the PyTorch repository.
4.1.1.6.2.4 Missing Fakequant Nodes
Converter Tool requires that fakequant nodes provide quantization information (i.e. quantization minimum and maximum range, bitwidth) of specific tensors. If a tensor does not have a following fakequant node, Converter Tool will try to deduce the quantization information. Possible approaches include:
- For nodes that do not involve computation or the computation would hardly change the value range, the minimum and maximum range of the output tensor can be propagated from the input tensor.
- For constant tensors, the minimum and maximum range can be directly calculated from the tensor content.
- For other cases, the minimum and maximum range can be deduced from the provided dataset during the conversion process.
|
Warning: |
|
If Converter Tool is unable to obtain quantization information for a tensor, the tensor will not be quantized. It will be left as a floating-point type in the resulting model. |
4.1.1.6.2.5 Data Type and Asymmetric/Symmetric Quantization
The num_bits information deduced from the fakequant nodes control the data type of the result model.
- If the num_bits attribute is in the range [9, 16], it will be expressed with INT16 type. In this case, Converter Tool requires symmetric quantization parameters.
- If the num_bits attribute is in the range [2, 8], it will be expressed with either INT8 or UINT8 depending on the converter settings. In this case, Converter Tool accepts both symmetric and asymmetric quantization parameters.
|
Note: |
|
Weight tensors that will be quantized per-channel must have symmetric quantization parameters. To use symmetric quantization, users should set the zero_point value to 0. |
4.1.1.6.2.6 Example
This section provides a simple example for the custom quantization-aware training tool interface.
The following is an example module that wraps the fake quantize API, and accepts the floating-point quantization range as input.
class FakeQuantFromMinMax(torch.nn.Module):
"""Example fake quantize module."""
def __init__(self, bitwidth, min_val, max_val, axis=None):
"""Initialize the class."""
super(FakeQuantFromMinMax, self).__init__()
self.quant_min = -1 * 2 ** (bitwidth - 1)
self.quant_max = 2 ** (bitwidth - 1) - 1
self.axis = axis
self.scale, self.zero_point = self.calculate_qparam(min_val, max_val)
def calculate_qparam(self, min_val, max_val):
"""Calculate scale/zero_point from minmax value."""
min_val = np.array(min_val, np.float32)
max_val = np.array(max_val, np.float32)
scale = (max_val - min_val) / (self.quant_max - self.quant_min)
zero_point = np.round(self.quant_min - min_val / scale).astype(np.int64)
return scale, zero_point
def forward(self, x):
"""Execute the module."""
if self.axis is None:
y = torch.fake_quantize_per_tensor_affine(
x, self.scale, self.zero_point, self.quant_min, self.quant_max
)
else:
scale = torch.tensor(self.scale)
zero_point = torch.tensor(self.zero_point)
y = torch.fake_quantize_per_channel_affine(
x, scale, zero_point, self.axis, self.quant_min, self.quant_max
)
return y
The following a simple example for using the above fake quantize module to build the PyTorch module with customized bitwidth and minimum and maximum values. We wrap the original torch.nn.Conv2d module in order to add fakequant operator to the weight parameter.
class FakeQuantizedConv2d(torch.nn.Conv2d):
"""Wrapper of Conv2d module for inserting weight fakequant."""
def __init__(self, quant_settings, *args, **kwargs):
super(FakeQuantizedConv2d, self).__init__(*args, **kwargs)
self.weight_fq = FakeQuantFromMinMax(*quant_settings)
def forward(self, x):
weight = self.weight_fq(self.weight)
return self._conv_forward(x, weight)
class Net(torch.nn.Module):
"""Example model with fakequant operator inserted."""
def __init__(self):
super(Net, self).__init__()
self.conv1 = FakeQuantizedConv2d([8, -1.2, 2.0], 1, 32, 3, 1)
self.conv1_fq = FakeQuantFromMinMax(8, -3.2, 5.3)
self.conv2 = FakeQuantizedConv2d([8, -2.7, 1.2], 32, 64, 3, 1)
self.conv2_fq = FakeQuantFromMinMax(8, -1.7, 8.2)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv1_fq(x)
x = self.conv2(x)
x = F.relu(x)
x = self.conv2_fq(x)
return x
model = Net()
... # Load the state_dict
# Trace the model and save as a script module file
trace_data = torch.randn(1, 1, 28, 28)
trace = torch.jit.trace(model.cpu().eval(), (trace_data))
torch.jit.save(trace, 'fakequant_model.pt')
After tracing, the model graph looks like this. The fake quantize operators are inserted at the expected places.
graph(%self.1 : __torch__.Net,
%input.2 : Tensor):
%3 : __torch__.___torch_mangle_3.FakeQuantFromMinMax = prim::GetAttr[name="conv2_fq"](%self.1)
%5 : __torch__.___torch_mangle_2.FakeQuantizedConv2d = prim::GetAttr[name="conv2"](%self.1)
%7 : __torch__.___torch_mangle_0.FakeQuantFromMinMax = prim::GetAttr[name="conv1_fq"](%self.1)
%9 : __torch__.FakeQuantizedConv2d = prim::GetAttr[name="conv1"](%self.1)
%31 : bool = prim::Constant[value=1]()
%32 : bool = prim::Constant[value=0]()
%33 : int = prim::Constant[value=1]()
%34 : int = prim::Constant[value=0]()
%35 : Tensor = prim::GetAttr[name="bias"](%9)
%36 : Tensor = prim::GetAttr[name="weight"](%9)
%37 : __torch__.FakeQuantFromMinMax = prim::GetAttr[name="weight_fq"](%9)
%38 : float = prim::Constant[value=0.012549019794838101]()
%39 : int = prim::Constant[value=-32]()
%40 : int = prim::Constant[value=-128]()
%41 : int = prim::Constant[value=127]()
%weight.2 : Tensor = aten::fake_quantize_per_tensor_affine(%36, %38, %39, %40, %41)
%43 : int[] = prim::ListConstruct(%33, %33)
%44 : int[] = prim::ListConstruct(%34, %34)
%45 : int[] = prim::ListConstruct(%33, %33)
%46 : int[] = prim::ListConstruct(%34, %34)
%input0.1 : Tensor = aten::_convolution(%input.2, %weight.2, %35, %43, %44, %45, %32, %46, %33, %32, %32, %31)
%x.1 : Tensor = aten::relu(%input0.1)
%48 : float = prim::Constant[value=0.033333333333333333]()
%49 : int = prim::Constant[value=-32]()
%50 : int = prim::Constant[value=-128]()
%51 : int = prim::Constant[value=127]()
%input.3 : Tensor = aten::fake_quantize_per_tensor_affine(%x.1, %48, %49, %50, %51)
...
%74 : Tensor = aten::fake_quantize_per_tensor_affine(%x0.1, %70, %71, %72, %73)
return (%74)
After conversion with Converter Tool, the PyTorch model is a quantized TFLite model. The result TFLite model looks like this.
4.1.2 Neuron SDK
The Neuron SDK allows users to convert their custom models to MediaTek-proprietary binaries for deployment on MediaTek platforms. The resulting models are highly efficient, with reduced latency and a smaller memory footprint. Users can also create a runtime environment, parse compiled model files, and perform inference on the edge. Neuron SDK is aimed at users who are performing bare metal C/C++ programming for AI applications, and offers an alternative to the Android Neural Networks API (NNAPI) for deploying Neural Network models on MediaTek-enabled Android devices.
The Neuron SDK consists of the following components:
- Neuron Compiler: An offline neural network model compiler which produces statically compiled deep learning archive (.dla) files.
- Neuron Runtime: A command line tool which executes a specified .dla file and reports the results.
- Neuron Run-time API: A user-invoked API which supports loading and running compiled .dla files within a user’s C++ application
- Neuron Profiler: A built-in performance profiler tool in Neuron Runtime.
4.1.2.1 Neuron Compiler and Runtime
Neuron SDK allows users to efficiently compile a custom Neural Network model and then execute the model on MediaTek platforms, while utilizing MediaTek’s AI Processing Unit (APU).
- Neuron compiler (ncc-tflite) transforms a TFLite model file into a DLA (Deep Learning Archive) file on the host computer. A DLA file is a low-level binary for MDLA and VPU compute devices.
- Neuron Runtime (neuronrt) provides APIs to load a DLA file and then either simulates network inference using a cycle-approximate software model of the MDLA (C-Model), or performs on-device inference.
The figure below provides an overview of the user flow for Neuron SDK.
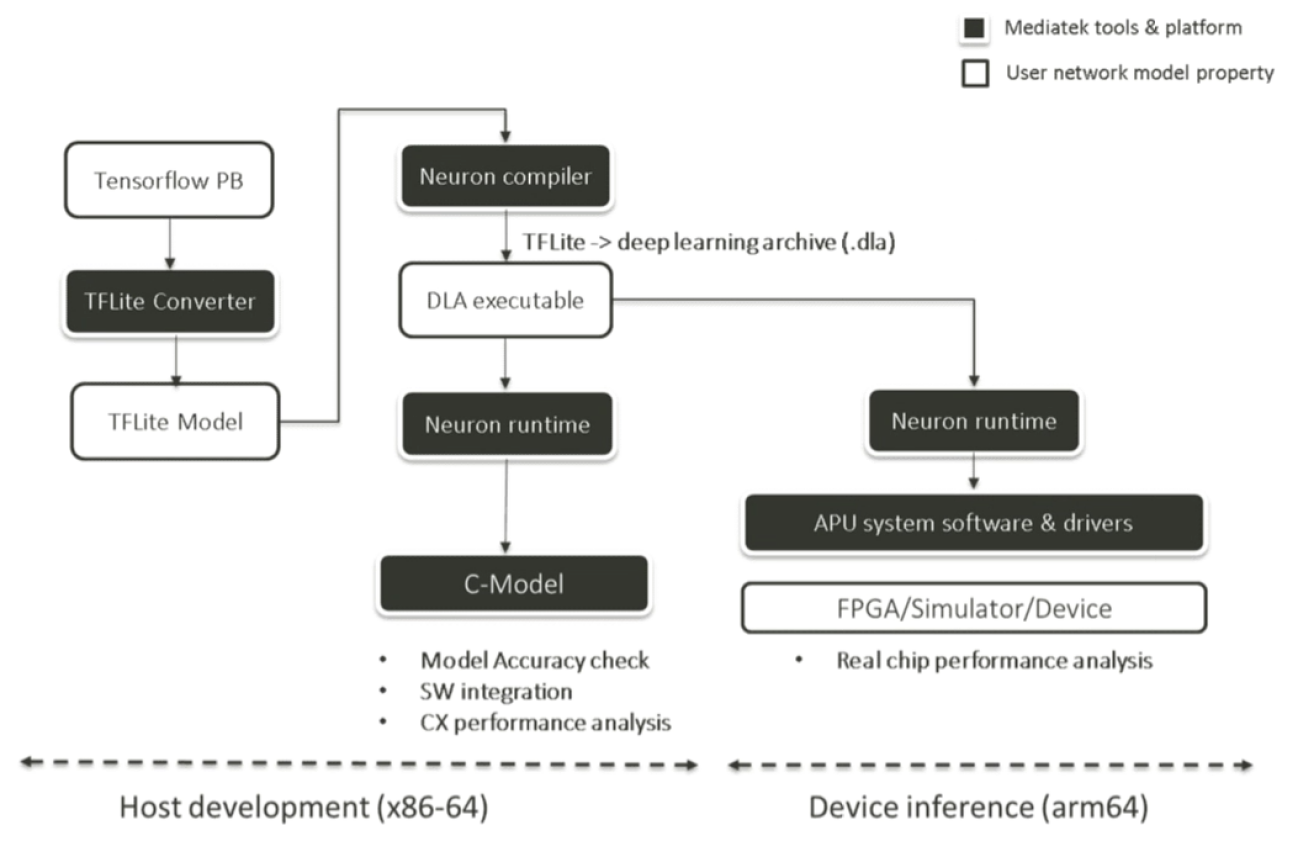
In this section, each Neuron tool is described with its command-line options. Neuron tools can be invoked directly from the command line, or from inside a C/C++ program using the Neuron API. For details on the Neuron API, see 5.4. Neuron API Reference.
4.1.2.1.1 Neuron Compiler (ncc-tflite)
ncc-tflite is a compiler tool used to generate a statically compiled network (.dla file) from a TFLite model. ncc-tflite supports the following two modes:
- Compilation mode: ncc-tflite generates a compiled binary (.dla) file from a TFLite model. Users can use the runtime tool (neuronrt) to execute the .dla file on a device.
- Execution mode: ncc-tflite compiles the TFLite model into a binary and then executes it directly on the device. Use -e to enable execution mode and -i <file> -o <file> to specify the input and output files.
Usage:
ncc-tflite [OPTION...] filename
--arch <name,...> Specify a list of target architecture names
--platform <name> Platform preference as hint for compilation
-O, --opt <level> Specify which optimization level to use:
[0]: no optimization
[1]: enable basic optimization for fast codegen
[2]: enable most optimizations
[3]: enable -O2 with other optimizations that
take longer compilation time (default: 2)
--opt-accuracy Optimize for accuracy
--opt-aggressive Enable optimizations that may lose accuracy
--opt-bw Optimize for bandwidth
--opt-size Optimize for size, including code and static data
--relax-fp32 Run fp32 models using fp16
--int8-to-uint8 Convert data types from INT8 to UINT8
--l1-size-kb <size> Hint the size of L1 memory (default: 0)
--l2-size-kb <size> Hint the size of L2 memory (default: 0)
--suppress-input Suppress input data conversion
--suppress-output Suppress output data conversion
--gen-debug-info Produce debugging information in the DLA file.
Runtime can work with this info for profiling
--show-exec-plan Show execution plan
--show-memory-summary Show memory allocation summary
--dla-metadata <key1:file1,key2:file2,...>
Specify a list of key:file pairs for DLA
metadata
--decompose-qlstmv2 Decompose QLSTM V2 to sub-OPs
--no-verify Bypass tflite model verification
-d, --dla-file <file> Specify a filename for the output DLA file
--check-target-only Check target support and exit
--resize <dims,...> Specify a list of input dimensions for resizing
(e.g., 1x3x5,2x4x6)
-s, --show-tflite Show tensors and nodes in the tflite model
--show-io-info Show input and output tensors of the tflite model
--show-builtin-ops Show available built-in operations and exit
--verbose Enable verbose mode
--version Output version information and exit
--help Display this help and exit
-e, --exec Enable execution (inference) mode
-i, --input <file,...> Specify a list of input files for inference
-o, --output <file,...> Specify a list of output files for inference
gno options:
--gno <opt1,opt2,...> Specify a list of graphite neuron optimizations.
Available options: NDF, SMP, BMP
mdla options:
--num-mdla <num> Use numbers of MDLA cores (default: 1)
--mdla-bw <num> Hint MDLA bandwidth (MB/s) (default: 10240)
--mdla-freq <num> Hint MDLA frequency (MHz) (default: 960)
--mdla-wt-pruned The weight of given model has been pruned
--prefer-large-acc <num> Use large accumulator to improve accuracy
--fc-to-conv Convert Fully Connected (FC) to Conv2D
--use-sw-dilated-conv Use software dilated convolution
--use-sw-deconv Convert DeConvolution to Conv2Ds
--req-per-ch-conv Requant invalid per-channel convs
--trim-io-alignment Trim the model IO alignment
vpu options:
--dual-vpu Use dual VPU
--exec / --input <file> / --output <file>
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Enable execution mode and specify input and output files.
--arch <target>
Specify a list of targets which the model is compiled for.
--platform <name>
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Hint platform preference for compilation.
--opt <level>
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Specify which optimization level to use.
-O0: No optimization
-O1: Enable basic optimization for fast codegen
-O2: Enable most optimizations (default)
-O3: Enable -O2 with other optimizations that increase compilation time
--opt-accuracy
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Optimize for accuracy. This option tries to make the inference results similar to the results from the CPU. It may also cause performance drops.
--opt-aggressive
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Enable optimizations that may lose accuracy.
--opt-bw
Optimize for bandwidth. Enable NDF agent (--gno=NDF) if --gno is not specified.
--opt-size
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Optimize for size, including code and static data. This option also disables some optimizations that may increase code or data size.
--intval-color-fast
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Disable exhaustive search in interval coloring to speed up compilation. This option is automatically turned on in -O2 or lower optimization level. This option can be used with -O3.
--dla-file <file>
Specify a filename for the output DLA file.
--relax-fp32
Hint the compiler to compute fp32 models using fp16 precision.
--decompose-qlstmv2
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Hint the compiler to decompose QLSTM V2 to multiple operations.
--check-target-only
Check target support without compiling. Each OP is checked against the target list. If any target does not support the OP, a message is displayed. For example, we use --arch=mdla1.5,vpu and --check-target-only for SOFTMAX:
OP[0]: SOFTMAX
├ MDLA: SoftMax is supported for MDLA 2.0 or newer.
├ VPU: unsupported data type: Float32
--resize
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Resize the inputs using the given new dimensions and run shape derivations throughout the model. This is useful for changing the dimensions of IO and the internal tensors of the model. Note that during shape derivations, the original attributes of each layer are not modified. Instead, the attributes might be read and then used to derive the new dimensions of the layer’s output tensors.
--int8-to-uint8
Convert data types from INT8 to UINT8. This option is required to run asymmetric signed 8-bit model on hardware that does not support INT8 (e.g., MDLA 1.0 and MDLA 1.5).
--l1-size-kb
Provide the compiler with L1 memory size. This value should not be larger than that of real platform.
--l2-size-kb
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Provide the compiler with L2 memory size. This value should not be larger than that of real platform.
--suppress-input
Disable automatic conversion of data types from FP32 to FP16 for each input, and disable data re-layout. When used, users must manually handle data conversion and data re-layout or inference might produce the wrong results. For more information on handling data re-layout, see 4.1.2.2.2.4. Suppress I/O Mode (Optional).
--suppress-output
Disable automatic conversion of data types from FP16 to FP32 for each output, and disable data re-layout. When used, users must manually handle data conversion and data re-layout or inference might produce the wrong results. For more information on handling data re-layout, see 4.1.2.2.2.4. Suppress I/O Mode (Optional).
--gen-debug-info
|
Note: |
|
This option is not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
Generate operation and location info in the DLA file, for per-op profiling.
--show-tflite
Show tensors and nodes in the TFLite model. For example:
Tensors:
[0]: MobilenetV2/Conv/Conv2D_Fold_bias
├ Type: kTfLiteInt32
├ AllocType: kTfLiteMmapRo
├ Shape: {32}
├ Scale: 0.000265382
├ ZeroPoint: 0
└ Bytes: 128
[1]: MobilenetV2/Conv/Relu6
├ Type: kTfLiteUInt8
├ AllocType: kTfLiteArenaRw
├ Shape: {1,112,112,32}
├ Scale: 0.0235285
├ ZeroPoint: 0
└ Bytes: 401408
[2]: MobilenetV2/Conv/weights_quant/FakeQuantWithMinMaxVars
├ Type: kTfLiteUInt8
├ AllocType: kTfLiteMmapRo
├ Shape: {32,3,3,3}
├ Scale: 0.0339689
├ ZeroPoint: 122
└ Bytes: 864
...
--show-io-info
Show input and output tensors of the TFLite model. For example:
# of input tensors: 1
[0]: input
├ Type: kTfLiteUInt8
├ AllocType: kTfLiteArenaRw
├ Shape: {1,299,299,3}
├ Scale: 0.00784314
├ ZeroPoint: 128
└ Bytes: 268203
# of output tensors: 1
[0]: InceptionV3/Logits/Conv2d_1c_1x1/BiasAdd
├ Type: kTfLiteUInt8
├ AllocType: kTfLiteArenaRw
├ Shape: {1,1,1,1001}
├ Scale: 0.0392157
├ ZeroPoint: 128
└ Bytes: 1001
--show-exec-plan
ncc-tflite supports heterogeneous compilation, it partitions the network automatically based on the --arch options provided and dispatches sub-graph to their corresponding supported targets. Use this option to check the execution plan table. For example:
ExecutionStep[0]
├ StepId: 0
├ Target: MDLA_1_5
└ Subgraph:
├ Conv2DLayer<0>
├ DepthwiseConv2DLayer<1>
├ Conv2DLayer<2>
├ Conv2DLayer<3>
├ DepthwiseConv2DLayer<4>
...
├ Conv2DLayer<61>
├ PoolingLayer<62>
├ Conv2DLayer<63>
├ ReshapeLayer<64>
└ Output: OpResult (external)
--show-memory-summary
Estimate the memory footprint of the given network.
The following is an example of DRAM/L1 (APU L1 memory)/L2 (APU L2 memory) breakdown. Each cell consists of two integers: X(Y). X is the physical buffer size of this entry. Y is the total size of tensors of this entry. Note that X <= Y since the same buffer may be reused for multiple tensors. Input/Output corresponds to the buffer size used for the network’s I/O activation. Temporary corresponds to the working buffer size of the network’s intermediate tensors (ncc-tflite analysis the graph dependencies and tries to minimize buffer usage). Static corresponds to the buffer size for the network’s weight.Planning memory according to the following settings:
L1 Size(bytes) = 0
L2 Size(bytes) = 0
Buffer allocation summary:
\ Unknown L1 L2 DRAM
Input 0(0) 0(0) 0(0) 200704(200704)
Output 0(0) 0(0) 0(0) 1008(1008)
Temporary 0(0) 0(0) 0(0) 1505280(81341200)
Static 0(0) 0(0) 0(0) 3585076(3585076)
--dla-metadata <key1:file1,key2:file2,...>
Specify a list of key:file pairs as DLA metadata. Use this option to add additional information to a DLA file, such as the model name or quantization parameters. Applications can read the metadata using the 5.4.3. RuntimeAPI.h functions NeuronRuntime_getMetadataInfo and NeuronRuntime_getMetadata. Note that adding metadata does not affect inference time.
Example: Adding metadata to a DLA file
$ ./ncc-tflite model.tflite -o model.dla --arch=mdla3.0 --dla-metadata quant:./quant1.bin, other:./misc.bin
Example: Reading metadata from a DLA file
// Get the size of the metadata
size_t metaSize = 0;
NeuronRuntime_getMetadataInfo(runtime, "quant", &metaSize);
// Metadata in dla is copied to 'data'
char* data = static_cast<char*>(malloc(sizeof(char) * metaSize));
NeuronRuntime_getMetadata(runtime, "quant", data, metaSize);
--show-builtin-ops
Show built-in operations supported by ncc-tflite.
--no-verify
Bypass TFLite model verification. Use this option when the given TFLite model cannot be run by the TFLite interpreter.
--verbose
Enable verbose mode. Detailed progress is shown during compilation.
--version
Print version information.
|
Note: |
|
These options are not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
--gno <opt1,opt2,...> Available graphite neuron optimizations: [NDF, SMP, BMP]
- NDF: Enables Network Deep Fusion transformation. This is an optimization strategy for reducing DRAM access.
- SMP: Enables Symmetric Multiprocessing transformation. This is an optimization strategy for executing the network in parallel on multiple DLA cores. The aim is to make graphs utilize the computation power of multiple cores more efficiently.
- BMP: Enables Batch Multiprocess transformation. This is an optimization strategy for executing each batch dimension of the network in parallel on multiple MDLA cores. The aim is to make graphs with multiple batches utilize the computation power of multiple cores more efficiently.
|
Note: |
|
These options are not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx). |
--num-mdla <num>
Hint the compiler to use <num> MDLA cores. With a multi-core platform, the compiler tries to generate commands for parallel execution.
--mdla-bw <num>
Provide the compiler with MDLA bandwidth.
--mdla-freq <num>
Provide the compiler with MDLA frequency.
--mdla-wt-pruned
Hint the compiler that the weight of a given model has been pruned.
--prefer-large-acc <num>
Hint the compiler to use a larger accumulator for improving accuracy. A higher value allows larger integer summation or multiplication, but a smaller value is ignored. Do not use this option if most of the results of summation or multiplication are smaller than 2^32.
--fc-to-conv
Hint the compiler to convert Fully Connected (FC) to Conv2D.
--use-sw-dilated-conv
Hint the compiler to use multiple non-dilated convolution to simulate a dilated convolution. This option increases the utilization rate of hardware with less internal buffer and allows dilation rates beside {1, 2, 4, 8}.
--use-sw-deconv
Hint the compiler to convert DeConvolution to Conv2Ds. This option increases the utilization rate of hardware but also the memory footprint.
--req-per-ch-conv
Hint the compiler to re-quantize the per-channel quantized Convolutions if they have unsupported scales of outputs. Enabling this option might reduce accuracy, because the re-quantization chooses the maximal scale of input_scale * filter_scale as the new output scale.
--trim-io-alignment
Hint the compiler to perform operations that could potentially reduce required paddings for inputs and outputs of the given network. NOTE: Enabling this option might introduce additional computation.
4.1.2.1.2 Neuron Runtime (neuronrt)
neuronrt invokes the Neuron runtime, which can execute statically compiled networks (.dla files). neuronrt allows users to either use C-Model to simulate inference on MDLA or perform on-device inference.
neuronrt [-m<device>] -a<dla_file> [-d] [-c<num>] [-p<mode>] -i <input.bin> -o <output.bin>
-m <device> Specify which device will be used to execute the DLA file.
<device> can be: null/cmodel/hw, default is null. If 'cmodel' is chosen,
users need to further set CModel library in env.
-a <pathToDla> Specify the ahead-of-time compiled network (.dla file)
-d Show I/O id-shape mapping table.
-i <pathToInputBin> Specify an input bin file. If there are multiple inputs, specify them
one-by-one in order, like -i input0.bin -i input1.bin.
-o <pathToOutputBin> Specify an output bin file. If there are multiple outputs, specify them
one-by-one in order, like -o output0.bin -o output1.bin.
-u Use recurrent execution mode.
-c <num> Repeat the inference <num> times. It can be used for profiling.
-b <boostValue> Specify the boost value for Quality of Service. Range is 0 to 100.
-p <priority> Specify the priority for Quality of Service. The available <priority>
arguments are 'urgent', 'normal', and 'low'.
-r <preference> Specify the execution preference for Quality of Service. The available
<preference> arguments are 'performance', and 'power'.
-t <ms> Specify the deadline for Quality of Service in ms.
Suggested value: 1000/FPS.
-e <strategy> ** This option takes no effect in Neuron 5.0. The parallelism is fully
controlled by the compiler-time option. To be removed in Neuron 6.0. **
Specify the strategy to execute commands on the MDLA cores. The available
<strategy> arguments are 'auto', 'single', and 'dual'. Default is auto.
If 'auto' is chosen, the scheduler decides the execution strategy.
If 'single' is chosen, all commands are forced to execute on a single MDLA.
If 'dual' is chosen, commands are forced to execute on dual MDLA.
-v Show the version of Neuron Runtime library
|
Note: |
|
The following options are not supported on MediaTek TV platforms (MT58xx/MT76xx/MT90xx/MT96xx/MT99xx):
|
4.1.2.1.2.2 I/O ID-Shape Mapping Table
If the -d option is specified, neuronrt will show I/O information of the .dla file specified by the -a option.
Example output:
Input :
Handle = 1, <1 x 128 x 64 x 3>, size = 98304 bytes
Handle = 0, <1 x 128 x 128 x 3>, size = 196608 bytes
Output :
Handle = 0, <1 x 128 x 192 x 5>, size = 491520 bytes
The row with Handle = <N> provides the I/O information for the N-th Input/Output in the compiled network.
Let’s analyze the I/O information of the input tensor in the second row of the example:
Handle = 1, <1 x 128 x 64 x 3>, size = 98304 bytes
The input tensor with handle=1 is the second input in the compiled network, and has shape <1 x 128 x 64 x 3> with a total data size of 98304 bytes. The example is a float32 network, therefore data size is calculated using the following method:
(1 x 128 x 64 x 3) x 4 (4 bytes for float32) = 98304
4.1.2.1.3 Examples
The following shows two examples for running a neural network model on a MediaTek device using Neuron tools.
4.1.2.1.3.1 Example: Single Input/Output
$ ${SW_RELEASE_DIR}/host/bin/ncc-tflite ${MODEL_DIR}/model.tflite –o model.dla
# MDLA device node requires system user or above permission
$ adb root
# copy neuronrt executable to device.
$ adb push ${SW_RELEASE_DIR}/${TARGET}/bin/neuronrt /data/local/tmp
# copy share library to device.
$ adb push ${SW_RELEASE_DIR}/${TARGET}/lib/* /data/local/tmp
# copy input binary to device.
$ adb push ${MODEL_DIR}/tf_input*.bin /data/local/tmp
# copy pre-compiled dla files to device.
$ adb push ${MODEL_DIR}/model.dla /data/local/tmp
# Network inference
$ adb shell LD_LIBRARY_PATH=/data/local/tmp \
/data/local/tmp/neuronrt \
-m hw \
-a /data/local/tmp/model.dla \
-i /data/local/tmp/input.bin \
-o /data/local/tmp/output.bin
4.1.2.1.3.2 Example: Multiple Inputs/Outputs
# Use "-i" or "-o" to specify the input/output files in order.
# Use "neuronrt -d to show the index of input/output id.'
$ adb shell LD_LIBRARY_PATH=/data/local/tmp \
/data/local/tmp/neuronrt \
-m hw \
-a /data/local/tmp/model.dla \
-i /data/local/tmp/input_0.bin \
-i /data/local/tmp/input_1.bin \
-i /data/local/tmp/input_2.bin \
-o /data/local/tmp/output.bin
4.1.2.2 Neuron Runtime API
Neuron Runtime API provides a set of API functions that users can invoke from within a C/C++ program to create a run-time environment, parse a compiled model file, and perform on-device network inference.
NeuroPilot 5 includes two versions of Neuron Runtime API.
4.1.2.2.1 Neuron Runtime API V1
To use Neuron Runtime API Version 1 (V1) in an application, include header RuntimeAPI.h. For a full list of Neuron Runtime API V1 functions, see 5.4.3. RuntimeAPI.h.
This section describes the typical workflow and has C++ examples of API usage.
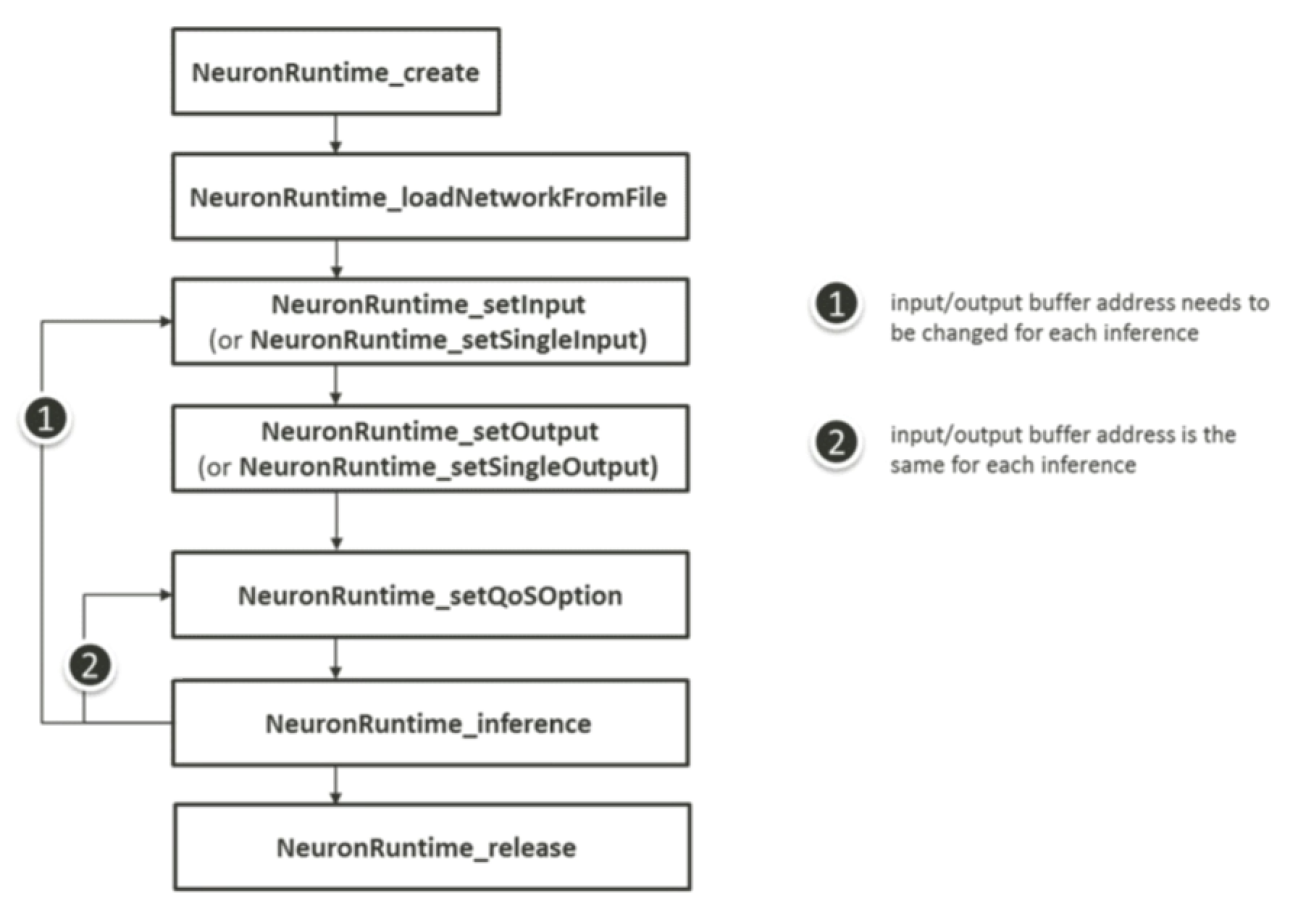
The sequence of API call in a typical user development flow is as follows:
- Use NeuronRuntime_create to create a neuron runtime.
- Use NeuronRuntime_loadNetworkFromFile to load a compiled network from a DLA file. Or use NeuronRuntime_loadNetworkFromBuffer to load compiled network from a memory buffer.
Using NeuronRuntime_loadNetworkFromFile will also setup the structure of QoS according to the shape of the compiled network.
- Use NeuronRuntime_setInput to set the input buffer for the model. Or use NeuronRuntime_setSingleInput to set the input if the model has only one input.
- Use NeuronRuntime_setOutput to set the output buffer for the model. Or use NeuronRuntime_setSingleOutput to set the the output if the model has only one output.
- (Optional) Prepare QoSOptions for inference:
- Set QoSOptions.preference to NEURONRUNTIME_PREFER_PERFORMANCE or NEURONRUNTIME_PREFER_POWER.
- Set QoSOptions.priority to NEURONRUNTIME_PRIORITY_LOW, NEURONRUNTIME_PRIORITY_MED, or NEURONRUNTIME_PRIORITY_HIGH.
- Set QoSOptions.abortTime and QoSOptions.deadline for configuring abort time and deadline.
|
Note: |
|
Non-zero value in QoSOptions.deadline implies that this inference will be scheduled as a real-time task. Both could be set to zero if there is no requirement on deadline or abort time. |
- Set profiled QoS data in QoSOptions.profiledQoSData. This field could be left as nullptr. Please refer to QoS Tuning Flow section for details.
- If the QoSOptions.profiledQoSData is nullptr, set QoSOptions.boostValue as a value between 0 (lowest frequency) and 100 (highest frequency). This value will be viewed as a hint for the underlying scheduler, and the execution boost value (actual boost value during execution) might be altered accordingly. Otherwise, if QoSOptions.profiledQoSData is not nullptr, set QoSOptions.boostValue to NEURONRUNTIME_BOOSTVALUE_PROFILED as a hint to use the profiled boost value set in QoSOptions.profiledQoSData.
- (Optional) Use NeuronRuntime_setQoSOption to configure the QoS settings for inference.
Users must check the return value. In case it generates NEURONRUNTIME_BAD_DATA, the input profiledQoSData must be regenerated again with the new version of compiled network. This essentially means that the structure of QoS data built in step 2 is not compatible with QoSOptions.profiledQoSData.
- Use NeuronRuntime_inference to perform inference with the compiled model and data in the input buffer. The result of the inference will be stored in the output buffer.
- (Optional) Perform inference again. Repeat from step 3 to step 7 if all settings are the same.
- Use NeuronRuntime_release to release the runtime resources.
4.1.2.2.1.2 QoS Tuning Flow (Optional)
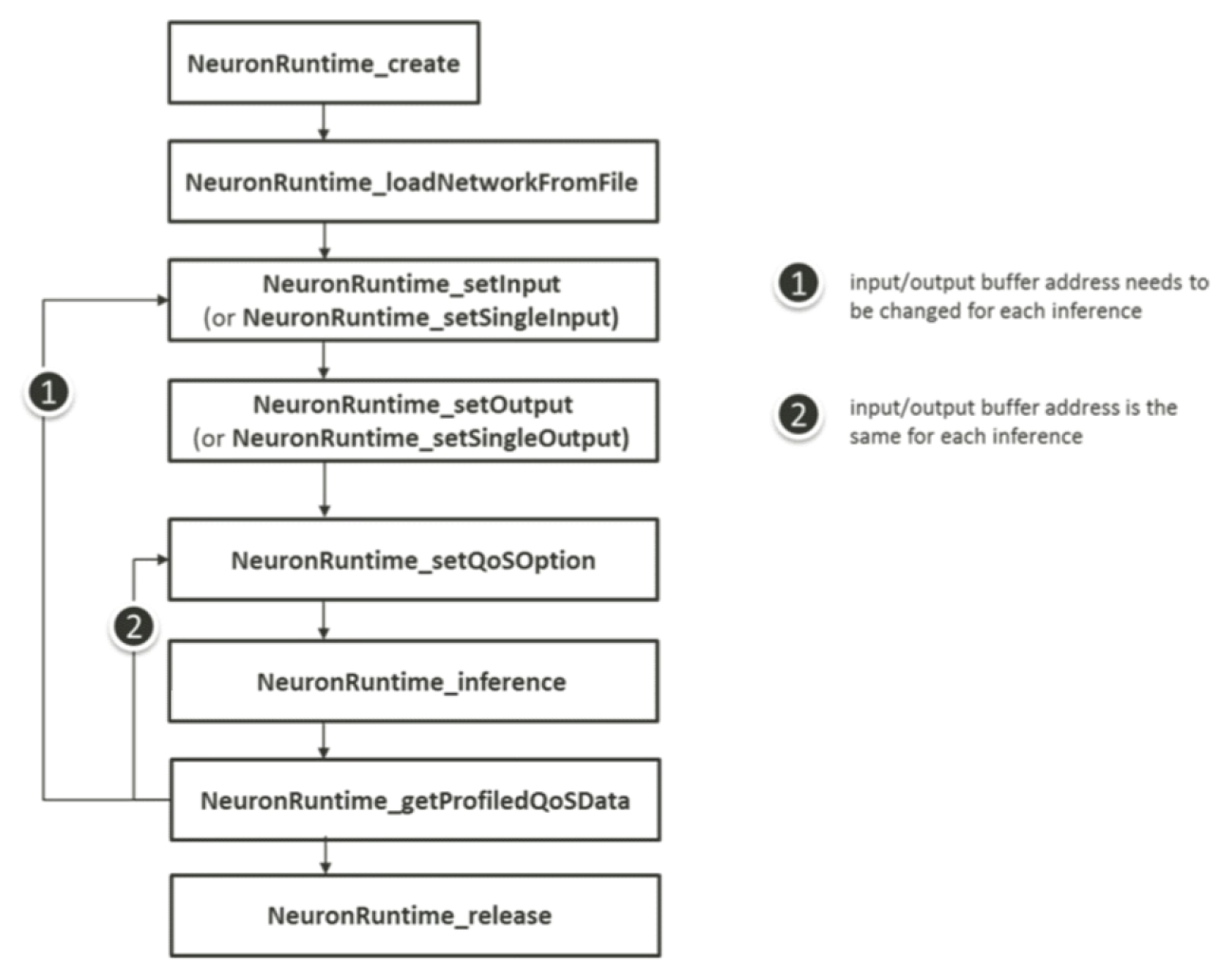
A typical QoS tuning flow consists of two sub-flows, namely, 1) iterative performance/power tuning, and 2) inference using the tuned QoS parameters. Both these flows are further explained in terms of the steps involved.
4.1.2.2.1.2.1 Iterative Performance/Power Tuning
- Use NeuronRuntime_create to create a Neuron Runtime instance.
- Load a compiled network using one of the following functions:
- Use NeuronRuntime_loadNetworkFromFile to load a compiled network from a DLA file.
- Use NeuronRuntime_loadNetworkFromBuffer to load a compiled network from a memory buffer. Using NeuronRuntime_loadNetworkFromFile also sets up the structure of the QoS according to the shape of the compiled network.
- Use NeuronRuntime_setInput to set the input buffer for the model. Or use NeuronRuntime_setSingleInput to set the input if the model has only one input.
- Use NeuronRuntime_setOutput to set the output buffer for the model. Or use NeuronRuntime_setSingleOutput to set the output if the model has only one output.
- Prepare QoSOptions for inference:
- Set QoSOptions.preference to NEURONRUNTIME_PREFER_PERFORMANCE or NEURONRUNTIME_PREFER_POWER.
- Set QoSOptions.priority to NEURONRUNTIME_PRIORITY_LOW, NEURONRUNTIME_PRIORITY_MED, or NEURONRUNTIME_PRIORITY_HIGH.
- Set QoSOptions.abortTime and QoSOptions.deadline for configuring abort time and deadline.
|
Note: |
|
- If the profiled QoS data is not presented, QoSOptions.profiledQoSData should be nullptr. QoSOptions.profiledQoSData will then be allocated in step 8 by invoking NeuronRuntime_getProfiledQoSData.
- Set QoSOptions.boostValue to an initial value between 0 (lowest frequency) and 100 (highest frequency). This value is viewed as a hint for the underlying scheduler, and the execution boost value (actual boost value during execution) might be altered accordingly.
- Use NeuronRuntime_setQoSOption to configure the QoS settings for inference.
- Use NeuronRuntime_inference to perform the inference.
- Use NeuronRuntime_getProfiledQoSData to check the inference time and execution boost value.
- If the inference time is too short, users should update QoSOptions.boostValue to a value less than execBootValue (executing boost value) and then repeat step 5.
- If the inference time is too long, users should update QoSOptions.boostValue to a value greater than execBootValue (executing boost value) and then repeat step 5.
- If the inference time is good, the tuning process of QoSOptions.profiledQoSData is complete.
|
Note: |
|
The profiledQoSData allocated by NeuronRuntime_getProfiledQoSData is destroyed after calling NeuronRuntime_release. The caller should store the contents of QoSOptions.profiledQoSData for later inferences. |
- Use NeuronRuntime_release to release the runtime resource.
4.1.2.2.1.2.2 Inference Using the Tuned QoSOptions.profiledQoSData
- Use NeuronRuntime_create to create a Neuron Runtime instance.
- Load a compiled network using one of the following functions:
- Use NeuronRuntime_loadNetworkFromFile to load a compiled network from a DLA file.
- Use NeuronRuntime_loadNetworkFromBuffer to load a compiled network from a memory buffer. Using NeuronRuntime_loadNetworkFromFile also sets up the structure of the QoS according to the shape of the compiled network.
- Use NeuronRuntime_setInput to set the input buffer for the model. Or use NeuronRuntime_setSingleInput to set the input if the model has only one input.
- Use NeuronRuntime_setOutput to set the output buffer for the model. Or use NeuronRuntime_setSingleOutput to set the output if the model has only one output.
- Prepare QoSOptions for inference:
- Set QoSOptions.preference to NEURONRUNTIME_PREFER_PERFORMANCE or NEURONRUNTIME_PREFER_POWER.
- Set QoSOptions.priority to NEURONRUNTIME_PRIORITY_LOW, NEURONRUNTIME_PRIORITY_MED, or NEURONRUNTIME_PRIORITY_HIGH.
- Set QoSOptions.abortTime and QoSOptions.deadline for configuring abort time and deadline.
|
Note: |
|
- Allocate QoSOptions.profiledQoSData and fill its contents with the previously tuned values.
- Set QoSOptions.boostValue to NEURONRUNTIME_BOOSTVALUE_PROFILED.
- Use NeuronRuntime_setQoSOption to configure the QoS settings for inference.
Users must check the return value. A return value of NEURONRUNTIME_BAD_DATA means the structure of the QoS data built in step 2 is not compatible with QoSOptions.profiledQoSData. The input profiledQoSData must be regenerated with the new version of the compiled network.
- Use NeuronRuntime_inference to perform the inference.
- (Optional) Perform inference again. If all settings are the same, repeat step 3 to step 7.
- Use NeuronRuntime_release to release the runtime resource.
Call NeuronRuntime_create_with_options to create a Neuron Runtime instance with user-specified options.
|
Option Name |
Description |
|
–disable-sync-input |
Disable input sync in Neuron. |
|
–disable-invalidate-output |
Disable output invalidation in Neuron. |
For example:
// Create Neuron Runtime instance with options
int error = NeuronRuntime_create_with_options("--disable-sync-input --disable-invalidate-output", optionsToDeprecate, runtime)
4.1.2.2.1.4 Suppress I/O Mode (Optional)
Suppress I/O mode is a special mode that can be used to eliminate the pre-processing and post-processing time entirely. Users need to layout the input/output tensors to HW shapes (network shape is unchanged) during inference. It is typically done using the following steps:
- Compile the network with --suppress-input-conversion or/and --suppress-output-conversion option to enable suppress I/O Mode.
- Set supressInputConversion=true and suppressOutputConversion=true while calling NeuronRuntime_create.
- Pass IO handlers to NeuronRuntime_setInput and NeuronRuntime_setOutput.
- Use NeuronRuntime_getInputPaddedSize to get aligned data size and pass the size to NeuronRuntime_setInput. Use NeuronRuntime_getOutputPaddedSize to get aligned data size and pass the size to NeuronRuntime_setOutput.
- Align each dimension of input data to hardware-compatible sizes (no changes in network shape). The hardware-compatible size (in pixels) for each dimension can be found by calling NeuronRuntime_getInputPaddedDimensions.
- Output will be aligned to hardware-compatible shape. The hardware-compatible size (in pixels) for each dimension can be found by calling NeuronRuntime_getOutputPaddedDimensions. A small code snippet is shown below for example.
// Get the aligned sizes of each dimension.
RuntimeAPIDimensions dims;
int err_code = NeuronRuntime_getInputPaddedDimensions(runtime, handle, &dims);
// Hardware aligned sizes of each dimensions in pixels.
uint32_t alignedN = dims.dimensions[RuntimeAPIDimIndex::N];
uint32_t alignedH = dims.dimensions[RuntimeAPIDimIndex::H];
uint32_t alignedW = dims.dimensions[RuntimeAPIDimIndex::W];
uint32_t alignedC = dims.dimensions[RuntimeAPIDimIndex::C];
4.1.2.2.1.5 Example: Using Runtime API
A sample C++ program is given below to illustrate the usage of above mentioned APIs and user flows.
#include <cassert>
#include <dlfcn.h>
#include <fstream>
#include <iostream>
#include <vector>
#include "neuron/api/RuntimeAPI.h"
// typedef to the functions pointer signatures.
typedef
int (*FnNeuronRuntime_create)(const EnvOptions* options, void** runtime);
typedef
int (*FnNeuronRuntime_loadNetworkFromFile)(void* runtime, const char* pathToDlaFile);
typedef
int (*FnNeuronRuntime_loadNetworkFromBuffer)(void* runtime, const void* buffer, size_t size);
typedef
int (*FnNeuronRuntime_setInput)(void* runtime, uint64_t handle, const void* buffer, size_t length,
BufferAttribute attr);
typedef
int (*FnNeuronRuntime_setSingleInput)(void* runtime, const void* buffer, size_t length,
BufferAttribute attr);
typedef
int (*FnNeuronRuntime_setOutput)(void* runtime, uint64_t handle, void* buffer, size_t length,
BufferAttribute attr);
typedef
int (*FnNeuronRuntime_setSingleOutput)(void* runtime, void* buffer, size_t length,
BufferAttribute attr);
typedef
int (*FnNeuronRuntime_setQoSOption)(void* runtime, const QoSOptions* qosOption);
typedef
int (*FnNeuronRuntime_getInputSize)(void* runtime, uint64_t handle, size_t* size);
typedef
int (*FnNeuronRuntime_getSingleInputSize)(void* runtime, size_t* size);
typedef
int (*FnNeuronRuntime_getOutputSize)(void* runtime, uint64_t handle, size_t* size);
typedef
int (*FnNeuronRuntime_getSingleOutputSize)(void* runtime, size_t* size);
typedef
int (*FnNeuronRuntime_getProfiledQoSData)(void* runtime, ProfiledQoSData** profiledQoSData,
uint8_t* execBoostValue);
typedef
int (*FnNeuronRuntime_inference)(void* runtime);
typedef
void (*FnNeuronRuntime_release)(void* runtime);
static FnNeuronRuntime_create fnNeuronRuntime_create;
static FnNeuronRuntime_loadNetworkFromFile fnNeuronRuntime_loadNetworkFromFile;
static FnNeuronRuntime_loadNetworkFromBuffer fnNeuronRuntime_loadNetworkFromBuffer;
static FnNeuronRuntime_setInput fnNeuronRuntime_setInput;
static FnNeuronRuntime_setSingleInput fnNeuronRuntime_setSingleInput;
static FnNeuronRuntime_setOutput fnNeuronRuntime_setOutput;
static FnNeuronRuntime_setSingleOutput fnNeuronRuntime_setSingleOutput;
static FnNeuronRuntime_setQoSOption fnNeuronRuntime_setQoSOption;
static FnNeuronRuntime_getInputSize fnNeuronRuntime_getInputSize;
static FnNeuronRuntime_getSingleInputSize fnNeuronRuntime_getSingleInputSize;
static FnNeuronRuntime_getOutputSize fnNeuronRuntime_getOutputSize;
static FnNeuronRuntime_getSingleOutputSize fnNeuronRuntime_getSingleOutputSize;
static FnNeuronRuntime_getProfiledQoSData fnNeuronRuntime_getProfiledQoSData;
static FnNeuronRuntime_inference fnNeuronRuntime_inference;
static FnNeuronRuntime_release fnNeuronRuntime_release;
void * load_func(void * handle, const char * func_name) {
/* Load the function specified by func_name, and exit if the loading is failed. */
void * func_ptr = dlsym(handle, func_name);
if (func_name == nullptr) {
std::cerr << "Find " << func_name << " function failed." << std::endl;
exit(2);
}
return func_ptr;
}
int main(int argc, char * argv[]) {
// argv[0]: executable name
// argv[1]: model.dla
// argv[2]: input.bin
if (argc != 3) {
std::cerr << "Usage: " << argv[0] << " model.dla input.bin" << std::endl;
exit(1);
}
// Read input
std::ifstream ifs(argv[2], std::ios::binary);
if (!ifs.is_open()) {
std::cerr << "Can't read " << argv[2] << std::endl;
exit(1);
}
// Prepare a memory buffer to save the image pixels
std::vector<char> input_buffer( (std::istreambuf_iterator<char>(ifs)),
std::istreambuf_iterator<char>() );
char* buf = input_buffer.data();
// Open the share library
void* handle = dlopen("./libneuron_runtime.so", RTLD_LAZY);
if (handle == nullptr) {
std::cerr << "Failed to open libneuron_runtime.so." << std::endl;
exit(1);
}
// Setup the environment options for the Neuron Runtime
EnvOptions envOptions = {
.deviceKind = kEnvOptHardware,
.MDLACoreOption = MDLACoreMode::Single, // Force single MDLA
.suppressInputConversion = false, // Please refer to the explanation above
.suppressOutputConversion = false, // Please refer to the explanation above
};
// Setup the QoS options for the Neuron Runtime
// Please refer to the explanation above for details
QoSOptions qosOptions = {
NEURONRUNTIME_PREFER_PERFORMANCE, // Preference
NEURONRUNTIME_PRIORITY_MED, // Priority
NEURONRUNTIME_BOOSTVALUE_MAX, // Boost value
0, // Deadline
0, // Abort time
nullptr, // Profiled QoS Data
};
// Declare function pointer to each functions,
// and load the function address into function pointer
#define LOAD(name) fn##name = reinterpret_cast<Fn##name>(load_func(handle, #name))
LOAD(NeuronRuntime_create);
LOAD(NeuronRuntime_loadNetworkFromFile);
LOAD(NeuronRuntime_loadNetworkFromBuffer);
LOAD(NeuronRuntime_setInput);
LOAD(NeuronRuntime_setSingleInput);
LOAD(NeuronRuntime_setOutput);
LOAD(NeuronRuntime_setSingleOutput);
LOAD(NeuronRuntime_getInputSize);
LOAD(NeuronRuntime_setQoSOption);
LOAD(NeuronRuntime_getSingleInputSize);
LOAD(NeuronRuntime_getOutputSize);
LOAD(NeuronRuntime_getSingleOutputSize);
LOAD(NeuronRuntime_getProfiledQoSData);
LOAD(NeuronRuntime_inference);
LOAD(NeuronRuntime_release);
#undef LOAD_FUNCTIONS
// Step 1. Create neuron runtime environment
void* runtime;
int err_code = (*fnNeuronRuntime_create)(&envOptions, &runtime);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to create Neuron runtime." << std::endl;
exit(3);
}
// Step 2. Load the compiled network(*.dla) from file
err_code = (*fnNeuronRuntime_loadNetworkFromFile)(runtime, argv[1]);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to load network from file." << std::endl;
exit(3);
}
// (Optional) Check the required input buffer size
size_t required_input_size;
err_code = (*fnNeuronRuntime_getSingleInputSize)(runtime, &required_input_size);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to get single input size for network." << std::endl;
exit(3);
}
std::cout << "The required size of the input buffer is " << required_input_size << std::endl;
// Step 3. Set the input buffer with our memory buffer (pixels inside)
BufferAttribute attr {NON_ION_FD};
err_code = (*fnNeuronRuntime_setSingleInput)(runtime, static_cast<void *>(buf),
required_input_size, attr);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to set single input for network." << std::endl;
exit(3);
}
// (Optional) Check the required output buffer size
size_t required_output_size;
err_code = (*fnNeuronRuntime_getSingleOutputSize)(runtime, &required_output_size);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to get single output size for network." << std::endl;
exit(3);
}
std::cout << "The required size of the output buffer is " << required_output_size << std::endl;
// Step 4. Set the output buffer
unsigned char * out_buf = new unsigned char[required_output_size];
err_code = (*fnNeuronRuntime_setSingleOutput)(runtime, static_cast<void *>(out_buf),
required_output_size, attr);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to set single output for network." << std::endl;
exit(3);
}
// (Optional) Set QoS Option
err_code = (*fnNeuronRuntime_setQoSOption)(runtime, &qosOptions);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to set QoS option, using default setting instead" << std::endl;
}
// Step 5. Do the inference with Neuron Runtime
err_code = (*fnNeuronRuntime_inference)(runtime);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to inference the input." << std::endl;
exit(3);
}
// (Optional) Get profiled QoS Data
// Neuron Rutime would allocate ProfiledQoSData instance when input profiledQoSData is nullptr.
ProfiledQoSData* profiledQoSData = nullptr;
uint8_t executingBoostValue;
err_code = (*fnNeuronRuntime_getProfiledQoSData)(runtime, &profiledQoSData,
&executingBoostValue);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to Get QoS Data" << std::endl;
}
// (Optional) Print out profiled QoS Data and executing boost value
if (profiledQoSData != nullptr) {
std::cout << "Dump the profiled QoS Data:" << std::endl;
std::cout << "executing boost value = " << +executingBoostValue << std::endl;
for (uint32_t i = 0u; i < profiledQoSData->numSubgraph; ++i) {
for (uint32_t j = 0u; j < profiledQoSData->numSubCmd[i]; ++j) {
std::cout << "SubCmd[" << i << "][" << j << "]:" << std::endl;
std::cout << "execution time = " << profiledQoSData->qosData[i][j].execTime
<< std::endl;
std::cout << "boost value = " << +profiledQoSData->qosData[i][j].boostValue
<< std::endl;
std::cout << "bandwidth = " << profiledQoSData->qosData[i][j].bandwidth
<< std::endl;
}
}
} else {
std::cerr << "profiledQoSData is nullptr" << std::endl;
}
// Step 6. Release the runtime resource
(*fnNeuronRuntime_release)(runtime);
// NOTE: profiledQoSData would be destroyed after NeuronRuntime_release.
// You should never de-reference profiledQoSData again.
// We check the inference result by finding the highest score in the output
unsigned char top = out_buf[0];
size_t top_idx = 0;
for (size_t i = 1; i < required_output_size; ++i) {
if (out_buf[i] > top) {
top = out_buf[i];
top_idx = i;
}
}
std::cout << "The top index is " << top_idx << std::endl;
return 0;
}
4.1.2.2.1.6 Example: Using dma-buf
A sample C++ program is given below to illustrate the integration of the Neuron Runtime APIs and the dma-buf.
#include <dlfcn.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <unistd.h>
#include <BufferAllocator/BufferAllocatorWrapper.h>
#include "RuntimeAPI.h"
typedef struct {
void *buffer_addr;
unsigned int share_fd;
unsigned int length;
} MemBufferShareFd;
void * load_func(void * handle, const char * func_name) {
/* Load the function specified by func_name, and exit if the loading is failed. */
void * func_ptr = dlsym(handle, func_name);
if (func_name == nullptr) {
printf("Find %s function failed.", func_name);
}
return func_ptr;
}
int main(int argc, char * argv[]) {
constexpr bool useCacheableBuffer = false;
void * handle;
void * runtime;
// typedef to the functions pointer signatures.
typedef int (*NeuronRuntime_create)(const EnvOptions* options, void** runtime);
typedef int (*NeuronRuntime_loadNetworkFromFile)(void* runtime, const char* dlaFile);
typedef int (*NeuronRuntime_setInput)(void* runtime, uint64_t handle, const void* buffer,
size_t length, BufferAttribute attr);
typedef int (*NeuronRuntime_setOutput)(void* runtime, uint64_t handle, void* buffer,
size_t length, BufferAttribute attr);
typedef int (*NeuronRuntime_inference)(void* runtime);
typedef void (*NeuronRuntime_release)(void* runtime);
typedef int (*NeuronRuntime_getInputSize)(void* runtime, uint64_t handle, size_t* size);
typedef int (*NeuronRuntime_getOutputSize)(void* runtime, uint64_t handle, size_t* size);
BufferAllocator* bufferAllocator = CreateDmabufHeapBufferAllocator();
FILE *fp;
// 1 * 244 * 244 * 3 is the size of the input buffer
MemBufferShareFd inputBuffer = {nullptr, 0, 1 * 299 * 299 * 3 * sizeof(char)};
if (useCacheableBuffer) {
// mtk_mm is the heap name of the dma-buf with cacheable buffer
inputBuffer.share_fd = DmabufHeapAlloc(bufferAllocator, "mtk_mm", inputBuffer.length, 0, 0);
} else {
// mtk_mm-uncached is the heap name of the dma-buf with uncacheable buffer
inputBuffer.share_fd = DmabufHeapAlloc(bufferAllocator, "mtk_mm-uncached", inputBuffer.length, 0, 0);
}
inputBuffer.buffer_addr = ::mmap(nullptr, inputBuffer.length, PROT_READ | PROT_WRITE, MAP_SHARED, inputBuffer.share_fd, 0);
if (inputBuffer.buffer_addr == MAP_FAILED) {
printf("mmap failed sharedFd = %d, size = %d, 0x%p: %s\n",
inputBuffer.share_fd, inputBuffer.length, inputBuffer.buffer_addr, strerror(errno));
return EXIT_FAILURE;
}
fp = fopen("./input.bin", "rb");
if (useCacheableBuffer) {
DmabufHeapCpuSyncStart(bufferAllocator, inputBuffer.share_fd, kSyncWrite, nullptr, nullptr);
}
if (nullptr != fp) {
fread(inputBuffer.buffer_addr, sizeof(char), inputBuffer.length / sizeof(char), fp);
fclose(fp);
}
if (useCacheableBuffer) {
DmabufHeapCpuSyncEnd(bufferAllocator, inputBuffer.share_fd, kSyncWrite, nullptr, nullptr);
}
// 1 * 1001 is the size of the output buffer
MemBufferShareFd outputBuffer = {nullptr, 0, 1 * 1001 * sizeof(char)};
if (useCacheableBuffer) {
// mtk_mm is the heap name of the dma-buf with cacheable buffer
outputBuffer.share_fd = DmabufHeapAlloc(bufferAllocator, "mtk_mm", outputBuffer.length, 0, 0);
} else {
// mtk_mm-uncached is the heap name of the dma-buf with uncacheable buffer
outputBuffer.share_fd = DmabufHeapAlloc(bufferAllocator, "mtk_mm-uncached", outputBuffer.length, 0, 0);
}
outputBuffer.buffer_addr = ::mmap(nullptr, outputBuffer.length, PROT_READ | PROT_WRITE, MAP_SHARED, outputBuffer.share_fd, 0);
if (outputBuffer.buffer_addr == MAP_FAILED) {
printf("mmap failed sharedFd = %d, size = %d, 0x%p: %s\n",
outputBuffer.share_fd, outputBuffer.length, outputBuffer.buffer_addr, strerror(errno));
return EXIT_FAILURE;
}
// Open the share library
handle = dlopen("./libneuron_runtime.so", RTLD_LAZY);
if (handle == nullptr) {
printf("Failed to open libneuron_runtime.so.");
return EXIT_FAILURE;
}
// Setup the environment options for the Neuron Runtime
EnvOptions envOptions = {
.deviceKind = 0,
.MDLACoreOption = Single,
.CPUThreadNum = 1,
.suppressInputConversion = false,
.suppressOutputConversion = false,
};
// Declare function pointer to each functions,
// and load the function address into function pointer
#define LOAD_FUNCTIONS(FUNC_NAME, VARIABLE_NAME) \
FUNC_NAME VARIABLE_NAME = reinterpret_cast<FUNC_NAME>(load_func(handle, #FUNC_NAME));
LOAD_FUNCTIONS(NeuronRuntime_create, rt_create)
LOAD_FUNCTIONS(NeuronRuntime_loadNetworkFromFile, loadNetworkFromFile)
LOAD_FUNCTIONS(NeuronRuntime_setInput, setInput)
LOAD_FUNCTIONS(NeuronRuntime_setOutput, setOutput)
LOAD_FUNCTIONS(NeuronRuntime_inference, inference)
LOAD_FUNCTIONS(NeuronRuntime_release, release)
LOAD_FUNCTIONS(NeuronRuntime_getInputSize, getInputSize)
LOAD_FUNCTIONS(NeuronRuntime_getOutputSize, getOutputSize)
#undef LOAD_FUNCTIONS
// Step 1. Create neuron runtime environment
int err_code = (*rt_create)(&envOptions, &runtime);
if (err_code != NEURONRUNTIME_NO_ERROR) {
printf("Failed to create Neuron runtime.\n");
return EXIT_FAILURE;
}
// Step 2. Load the compiled network(*.dla) from file
err_code = (*loadNetworkFromFile)(runtime, argv[1]);
if (err_code != NEURONRUNTIME_NO_ERROR) {
printf("Failed to load network from file.\n");
return EXIT_FAILURE;
}
// (Options) Check the required input buffer size
size_t required_size;
err_code = (*getInputSize)(runtime, 0, &required_size);
if (err_code != NEURONRUNTIME_NO_ERROR) {
printf("Failed to get single input size for network.\n");
return EXIT_FAILURE;
}
printf("The required size of the input buffer is %lu\n", required_size);
// Step 3. Set the input buffer with our memory buffer (pixels inside)
err_code = (*setInput)(runtime, 0, static_cast<void *>(inputBuffer.buffer_addr), inputBuffer.length,
{static_cast<int>(inputBuffer.share_fd)});
if (err_code != NEURONRUNTIME_NO_ERROR) {
printf("Failed to set single input for network.\n");
return EXIT_FAILURE;
}
// (Options) Check the required output buffer size
err_code = (*getOutputSize)(runtime, 0, &required_size);
if (err_code != NEURONRUNTIME_NO_ERROR) {
printf("Failed to get single output size for network.\n");
return EXIT_FAILURE;
}
printf("The required size of the output buffer is %lu\n", required_size);
// Step 4. Set the output buffer
err_code = (*setOutput)(runtime, 0, static_cast<void *>(outputBuffer.buffer_addr), outputBuffer.length,
{static_cast<int>(outputBuffer.share_fd)});
if (err_code != NEURONRUNTIME_NO_ERROR) {
printf("Failed to set single output for network.\n");
return EXIT_FAILURE;
}
// Step 5. Do the inference with Neuron Runtime
err_code = (*inference)(runtime);
if (err_code != NEURONRUNTIME_NO_ERROR) {
printf("Failed to inference the input.\n");
return EXIT_FAILURE;
}
// Step 6. Release the runtime resource
(*release)(runtime);
fp = fopen("./output.bin", "wb");
if (useCacheableBuffer) {
DmabufHeapCpuSyncStart(bufferAllocator, outputBuffer.share_fd, kSyncRead, nullptr, nullptr);
}
if (nullptr != fp) {
fwrite(outputBuffer.buffer_addr, sizeof(char), outputBuffer.length / sizeof(char), fp);
fclose(fp);
}
if (useCacheableBuffer) {
DmabufHeapCpuSyncEnd(bufferAllocator, outputBuffer.share_fd, kSyncRead, nullptr, nullptr);
}
if (::munmap(inputBuffer.buffer_addr, inputBuffer.length) != 0) {
printf("inputbuffer munmap failed address = 0x%p, size = %d: %s\n",
inputBuffer.buffer_addr, inputBuffer.length, strerror(errno));
return EXIT_FAILURE;
}
close(inputBuffer.share_fd);
if (::munmap(outputBuffer.buffer_addr, outputBuffer.length) != 0) {
printf("outputbuffer munmap failed address = 0x%p, size = %d: %s\n",
outputBuffer.buffer_addr, outputBuffer.length, strerror(errno));
return EXIT_FAILURE;
}
close(outputBuffer.share_fd);
FreeDmabufHeapBufferAllocator(bufferAllocator);
return 0;
}
4.1.2.2.2 Neuron Runtime API V2
To use Neuron Runtime API Version 2 (V2) in an application, include header RuntimeV2.h. For a full list of Neuron Runtime API V2 functions, see 5.4.4. RuntimeV2.h.
This section describes the typical workflow and has C++ examples of API usage.
The sequence of API calls to accomplish a synchronous inference request is as follows:
- Call NeuronRuntimeV2_create() to create the Neuron runtime.
- Prepare input descriptors. Each descriptor is a struct named IOBuffer. The i-th descriptor corresponds to the i-th input of the model. All input descriptors should be placed consecutively.
- Prepare output descriptors for model outputs in a similar way.
- Construct a SyncInferenceRequest variable, for example req, which points to the input and output descriptors.
- Call NeuronRuntimeV2_run(runtime, req) to issue the inference request.
- Call NeuronRuntimeV2_release to release the runtime resource.
4.1.2.2.2.2 QoS Tuning Flow (Optional)
The sequence of API calls to accomplish a synchronous inference request with QoS options is as follows:
- Call NeuronRuntimeV2_create() to create neuron runtime.
- Prepare input descriptors. Each descriptor is a struct named IOBuffer. The i-th descriptor corresponds to the i-th input of the model. All input descriptors should be placed consecutively.
- Prepare output descriptors for model outputs in a similar way.
- Construct a SyncInferenceRequest variable, for example req, pointing to the input and output descriptors.
- Construct a QoSOptions variable, for example qos, and assign the options. Every field is optional:
- Set qos.preference to NEURONRUNTIME_PREFER_PERFORMANCE, NEURONRUNTIME_PREFER_POWER, or NEURONRUNTIME_HINT_TURBO_BOOST for the inference mode in runtime.
- Set qos.boostValue to NEURONRUNTIME_BOOSTVALUE_MAX, NEURONRUNTIME_BOOSTVALUE_MIN, or an integer in the range [0, 100] for the inference boost value in runtime. This value is viewed as a hint for the scheduler.
- Set qos.priority to NEURONRUNTIME_PRIORITY_LOW, NEURONRUNTIME_PRIORITY_MED, NEURONRUNTIME_PRIORITY_HIGH for the inference priority to the scheduler.
- Set qos.abortTime to indicate the maximum inference time for the inference, in msec. This field should be zero, unless you want to abort the inference.
- Set qos.deadline to indicate the deadline for the inference, in msec. Setting any non-zero value notifies the scheduler that this inference is a real-time task. This field should be zero, unless this inference is a real-time task.
- Set qos.delayedPowerOffTime to indicate the delayed power off time after inference completed, in msec. After the delayed power off time expires and there are no other incoming inference requests, the underlying devices power off for power-saving purpose. Set this field to NEURONRUNTIME_POWER_OFF_TIME_DEFAULT to use the default power off policy in the scheduler.
- Set qos.powerPolicy to NEURONRUNTIME_POWER_POLICY_DEFAULT to use the default power policy in the scheduler. This field is reserved and is not active yet.
- Set qos.applicationType to NEURONRUNTIME_APP_NORMAL to indicate the application type to scheduler. This field is reserved and is not active yet.
- Set qos.maxBoostValue to an integer in the range [0, 100] for the maximum runtime inference boost value. This field is reserved and is not active yet.
- Set qos.minBoostValue to an integer in the range [0, 100] for the minimum runtime inference boost value. This field is reserved and is not active yet.
- Call NeuronRuntimeV2_setQoSOption(runtime, qos) to configure the QoS options.
- Call NeuronRuntimeV2_run(runtime, req) to issue the inference request.
- Call NeuronRuntimeV2_release to release the runtime resource.
Call NeuronRuntimeV2_create_with_options to create a Neuron Runtime instance with user-specified options.
|
Option Name |
Description |
|
–disable-sync-input |
Disable input sync in Neuron. |
|
–disable-invalidate-output |
Disable output invalidation in Neuron. |
For example:
// Create Neuron Runtime instance with options
int error = NeuronRuntimeV2_create_with_options("--disable-sync-input --disable-invalidate-output", optionsToDeprecate, runtime)
4.1.2.2.2.4 Suppress I/O Mode (Optional)
Suppress I/O mode is a special mode which eliminates MDLA pre-processing and post-processing time. The user must layout the inputs and outputs to the MDLA hardware shape (network shape is unchanged) during inference. To do this, follow these steps:
- Compile the network with --suppress-input or/and --suppress-output option to enable suppress I/O Mode.
- Fill the ION descriptors to the IOBuffer when preparing SyncInferenceRequest or AsyncInferenceRequest.
- Call NeuronRuntimeV2_getInputPaddedSize to get the aligned data size, and then set this value in SyncInferenceRequest or AsyncInferenceRequest.
- Call NeuronRuntimeV2_getOutputPaddedSize to get the aligned data size, and then then set this value in SyncInferenceRequest or AsyncInferenceRequest.
- Align each dimension of the input data to the hardware-required size. There are no changes on network shape. The hardware-required size, in pixels, of each dimension can be found in *dims. *dims is returned by NeuronRuntime_getInputPaddedDimensions(void* runtime, uint64_t handle, RuntimeAPIDimensions* dims).
- Align each dimension of the output data to the hardware-required size. The hardware required size, in pixels, of each dimension can be found in *dims. *dims is returned by NeuronRuntime_getOutputPaddedDimensions (void* runtime, uint64_t handle, RuntimeAPIDimensions* dims).
Example code to use this API:
// Get the aligned sizes of each dimension.
RuntimeAPIDimensions dims;
int err_code = NeuronRuntime_getInputPaddedDimensions(runtime, handle, &dims);
// hardware aligned sizes of each dimensions in pixels.
uint32_t alignedN = dims.dimensions[RuntimeAPIDimIndex::N];
uint32_t alignedH = dims.dimensions[RuntimeAPIDimIndex::H];
uint32_t alignedW = dims.dimensions[RuntimeAPIDimIndex::W];
uint32_t alignedC = dims.dimensions[RuntimeAPIDimIndex::C];
4.1.2.2.2.5 Example: Using Runtime API
A sample C++ program is given below to illustrate the usage of the Neuron Runtime API V2 and user flows.
#include "neuron/api/RuntimeV2.h"
#include <algorithm>
#include <dlfcn.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <vector>
void* LoadLib(const char* name) {
auto handle = dlopen(name, RTLD_NOW | RTLD_LOCAL);
if (handle == nullptr) {
std::cerr << "Unable to open Neuron Runtime library " << dlerror() << std::endl;
}
return handle;
}
void* GetLibHandle() {
// Load the Neuron library based on the target device.
// For example, for DX-1 use "libeneuron_runtime.5.so"
return LoadLib("libneuron_runtime.so");
}
inline void* LoadFunc(void* libHandle, const char* name) {
if (libHandle == nullptr) { std::abort(); }
void* fn = dlsym(libHandle, name);
if (fn == nullptr) {
std::cerr << "Unable to open Neuron Runtime function [" << name
<< "] Because " << dlerror() << std::endl;
}
return fn;
}
typedef
int (*FnNeuronRuntimeV2_create)(const char* pathToDlaFile,
size_t nbThreads, void** runtime, size_t backlog);
typedef
void (*FnNeuronRuntimeV2_release)(void* runtime);
typedef
int (*FnNeuronRuntimeV2_enqueue)(void* runtime, AsyncInferenceRequest request, uint64_t* job_id);
typedef
int (*FnNeuronRuntimeV2_getInputSize)(void* runtime, uint64_t handle, size_t* size);
typedef
int (*FnNeuronRuntimeV2_getOutputSize)(void* runtime, uint64_t handle, size_t* size);
typedef
int (*FnNeuronRuntimeV2_getInputNumber)(void* runtime, size_t* size);
typedef
int (*FnNeuronRuntimeV2_getOutputNumber)(void* runtime, size_t* size);
static FnNeuronRuntimeV2_create fnNeuronRuntimeV2_create;
static FnNeuronRuntimeV2_release fnNeuronRuntimeV2_release;
static FnNeuronRuntimeV2_enqueue fnNeuronRuntimeV2_enqueue;
static FnNeuronRuntimeV2_getInputSize fnNeuronRuntimeV2_getInputSize;
static FnNeuronRuntimeV2_getOutputSize fnNeuronRuntimeV2_getOutputSize;
static FnNeuronRuntimeV2_getInputNumber fnNeuronRuntimeV2_getInputNumber;
static FnNeuronRuntimeV2_getOutputNumber fnNeuronRuntimeV2_getOutputNumber;
static std::string gDLAPath; // NOLINT(runtime/string)
static uint64_t gInferenceRepeat = 5000;
static uint64_t gThreadCount = 4;
static uint64_t gBacklog = 2048;
static std::vector<int> gJobIdToTaskId;
void finish_callback(uint64_t job_id, void*, int status) {
std::cout << job_id << ": " << status << std::endl;
}
struct IOBuffers {
std::vector<std::vector<uint8_t>> inputs;
std::vector<std::vector<uint8_t>> outputs;
std::vector<IOBuffer> inputDescriptors;
std::vector<IOBuffer> outputDescriptors;
IOBuffers(std::vector<size_t> inputSizes, std::vector<size_t> outputSizes) {
inputs.reserve(inputSizes.size());
outputs.reserve(outputSizes.size());
for (size_t idx = 0 ; idx < inputSizes.size() ; idx++) {
inputs.emplace_back(std::vector<uint8_t>(inputSizes.at(idx)));
// Input data may be filled in inputs.back().
}
for (size_t idx = 0 ; idx < outputSizes.size() ; idx++) {
outputs.emplace_back(std::vector<uint8_t>(outputSizes.at(idx)));
// Output will be filled in outputs.
}
}
IOBuffers& operator=(const IOBuffers& rhs) = default;
AsyncInferenceRequest ToRequest() {
inputDescriptors.reserve(inputs.size());
outputDescriptors.reserve(outputs.size());
for (size_t idx = 0 ; idx < inputs.size() ; idx++) {
inputDescriptors.push_back({inputs.at(idx).data(), inputs.at(idx).size(), -1});
}
for (size_t idx = 0 ; idx < outputs.size() ; idx++) {
outputDescriptors.push_back({outputs.at(idx).data(), outputs.at(idx).size(), -1});
}
AsyncInferenceRequest req;
req.inputs = inputDescriptors.data();
req.outputs = outputDescriptors.data();
req.finish_cb = finish_callback;
return req;
}
};
int main(int argc, char* argv[]) {
const auto libHandle = GetLibHandle();
#define LOAD(name) fn##name = reinterpret_cast<Fn##name>(LoadFunc(libHandle, #name))
LOAD(NeuronRuntimeV2_create);
LOAD(NeuronRuntimeV2_release);
LOAD(NeuronRuntimeV2_enqueue);
LOAD(NeuronRuntimeV2_getInputSize);
LOAD(NeuronRuntimeV2_getOutputSize);
LOAD(NeuronRuntimeV2_getInputNumber);
LOAD(NeuronRuntimeV2_getOutputNumber);
void* runtime = nullptr;
if (fnNeuronRuntimeV2_create(gDLAPath.c_str(), gThreadCount, &runtime, gBacklog)
!= NEURONRUNTIME_NO_ERROR) {
std::cerr << "Cannot create runtime" << std::endl;
return EXIT_FAILURE;
}
// Get input and output number.
size_t nbInput, nbOutput;
fnNeuronRuntimeV2_getInputNumber(runtime, &nbInput);
fnNeuronRuntimeV2_getOutputNumber(runtime, &nbOutput);
// Prepare input/output buffers.
std::vector<size_t> inputSizes, outputSizes;
for (size_t idx = 0 ; idx < nbInput ; idx++) {
size_t size;
if (fnNeuronRuntimeV2_getInputSize(runtime, idx, &size)
!= NEURONRUNTIME_NO_ERROR) { return EXIT_FAILURE; }
inputSizes.push_back(size);
}
for (size_t idx = 0 ; idx < nbOutput ; idx++) {
size_t size;
if (fnNeuronRuntimeV2_getOutputSize(runtime, idx, &size)
!= NEURONRUNTIME_NO_ERROR) { return EXIT_FAILURE; }
outputSizes.push_back(size);
}
std::vector<IOBuffers> tests;
for (size_t i = 0 ; i < gInferenceRepeat ; i++) {
tests.emplace_back(inputSizes, outputSizes);
}
gJobIdToTaskId.resize(gInferenceRepeat);
// Enqueue inference request.
for (size_t i = 0 ; i < gInferenceRepeat ; i++) {
uint64_t job_id;
auto status = fnNeuronRuntimeV2_enqueue(runtime, tests.at(i).ToRequest(), &job_id);
gJobIdToTaskId.at(job_id) = i;
if (status != NEURONRUNTIME_NO_ERROR) { break; }
}
// Call release to wait for all tasks to finish.
fnNeuronRuntimeV2_release(runtime);
return EXIT_SUCCESS;
}
4.1.2.2.2.6 Example: Using dma-buf
A sample C++ program is given below to illustrate the integration of Neuron Runtime API V2 and the dma-buf.
#include <stdio.h>
#include <string.h>
#include <string>
#include <BufferAllocator/BufferAllocatorWrapper.h>
#include <vector>
#include <unistd.h>
#include <errno.h>
#include <sys/mman.h>
#include <RuntimeV2.h>
using namespace std;
typedef struct {
void *buffer_addr;
unsigned int share_fd;
unsigned int length;
} MemBufferShareFd;
int SampleSyncRequest(bool useCacheableBuffer) {
BufferAllocator* bufferAllocator = CreateDmabufHeapBufferAllocator();
FILE *fp;
// 1 * 244 * 244 * 3 is the size of the input buffer
MemBufferShareFd inputBuffer = {nullptr, 0, 1 * 224 * 224 * 3 * sizeof(char)};
if (useCacheableBuffer) {
// mtk_mm is the heap name of the dma-buf with cacheable buffer
inputBuffer.share_fd = DmabufHeapAlloc(bufferAllocator, "mtk_mm", inputBuffer.length, 0, 0);
} else {
// mtk_mm-uncached is the heap name of the dma-buf with uncacheable buffer
inputBuffer.share_fd = DmabufHeapAlloc(bufferAllocator, "mtk_mm-uncached", inputBuffer.length, 0, 0);
}
inputBuffer.buffer_addr = ::mmap(nullptr, inputBuffer.length, PROT_READ | PROT_WRITE, MAP_SHARED, inputBuffer.share_fd, 0);
if (inputBuffer.buffer_addr == MAP_FAILED) {
printf("mmap failed sharedFd = %d, size = %d, 0x%p: %s\n",
inputBuffer.share_fd, inputBuffer.length, inputBuffer.buffer_addr, strerror(errno));
return 1;
}
fp = fopen("./input.bin", "rb");
if (useCacheableBuffer) {
DmabufHeapCpuSyncStart(bufferAllocator, inputBuffer.share_fd, kSyncWrite, nullptr, nullptr);
}
if (nullptr != fp) {
fread(inputBuffer.buffer_addr, sizeof(char), inputBuffer.length / sizeof(char), fp);
fclose(fp);
}
if (useCacheableBuffer) {
DmabufHeapCpuSyncEnd(bufferAllocator, inputBuffer.share_fd, kSyncWrite, nullptr, nullptr);
}
SyncInferenceRequest sync_data = {
nullptr,
nullptr,
};
std::vector<IOBuffer> inputDescriptors;
std::vector<IOBuffer> outputDescriptors;
IOBuffer inputDescriptor = { nullptr, 0, 0, 0 };
IOBuffer outputDescriptor = { nullptr, 0, 0, 0 };
inputDescriptor.length = inputBuffer.length;
inputDescriptor.fd = inputBuffer.share_fd;
inputDescriptor.buffer = inputBuffer.buffer_addr;
inputDescriptors.push_back(inputDescriptor);
sync_data.inputs = inputDescriptors.data();
// 1 * 1001 is the size of the output buffer
MemBufferShareFd outputBuffer = {nullptr, 0, 1 * 1001 * sizeof(char)};
if (useCacheableBuffer) {
// mtk_mm is the heap name of the dma-buf with cacheable buffer
outputBuffer.share_fd = DmabufHeapAlloc(bufferAllocator, "mtk_mm", outputBuffer.length, 0, 0);
} else {
// mtk_mm-uncached is the heap name of the dma-buf with uncacheable buffer
outputBuffer.share_fd = DmabufHeapAlloc(bufferAllocator, "mtk_mm-uncached", outputBuffer.length, 0, 0);
}
outputBuffer.buffer_addr = ::mmap(nullptr, outputBuffer.length, PROT_READ | PROT_WRITE, MAP_SHARED, outputBuffer.share_fd, 0);
if (outputBuffer.buffer_addr == MAP_FAILED) {
printf("mmap failed sharedFd = %d, size = %d, 0x%p: %s\n",
outputBuffer.share_fd, outputBuffer.length, outputBuffer.buffer_addr, strerror(errno));
return 1;
}
outputDescriptor.buffer = outputBuffer.buffer_addr;
outputDescriptor.fd = outputBuffer.share_fd;
outputDescriptor.length = outputBuffer.length;
outputDescriptors.push_back(outputDescriptor);
sync_data.outputs = outputDescriptors.data();
// Neuron runtime init
void* runtime;
if (NeuronRuntimeV2_create("./model.dla", 1, &runtime, /* backlog */2048) != NEURONRUNTIME_NO_ERROR) {
return EXIT_FAILURE;
}
printf("run--begin");
// Neuron runtime inference
int result = NeuronRuntimeV2_run(runtime, sync_data);
if (result!= NEURONRUNTIME_NO_ERROR) {
printf("run with failed with error code: %d---end", result);
return EXIT_FAILURE;
}
printf("run with OK---end");
// Neuron runtime release
NeuronRuntimeV2_release(runtime);
fp = fopen("./output.bin", "wb");
if (useCacheableBuffer) {
DmabufHeapCpuSyncStart(bufferAllocator, outputBuffer.share_fd, kSyncRead, nullptr, nullptr);
}
if (nullptr != fp) {
fwrite(outputBuffer.buffer_addr, sizeof(char), outputBuffer.length / sizeof(char), fp);
fclose(fp);
}
if (useCacheableBuffer) {
DmabufHeapCpuSyncEnd(bufferAllocator, outputBuffer.share_fd, kSyncRead, nullptr, nullptr);
}
if (::munmap(inputBuffer.buffer_addr, inputBuffer.length) != 0) {
printf("inputbuffer munmap failed address = 0x%p, size = %d: %s\n",
inputBuffer.buffer_addr, inputBuffer.length, strerror(errno));
return 1;
}
close(inputBuffer.share_fd);
if (::munmap(outputBuffer.buffer_addr, outputBuffer.length) != 0) {
printf("outputbuffer munmap failed address = 0x%p, size = %d: %s\n",
outputBuffer.buffer_addr, outputBuffer.length, strerror(errno));
return 1;
}
close(outputBuffer.share_fd);
FreeDmabufHeapBufferAllocator(bufferAllocator);
return 0;
}
int main(int argc, char * argv[]) {
int ret = 0;
bool useCacheableBuffer = false;
ret = SampleSyncRequest(useCacheableBuffer);
if (0 != ret) {
printf("\n === SampeSyncRequest error! === \n");
}
return ret;
}
|
Attention: |
|
Do not call Neuron Runtime V1 and V2 API functions on the same model. Use only Runtime V1 API or only Runtime V2 API. |
4.1.2.2.3 Runtime API Versions
Neuron Runtime V1
- For single task and sequential execution (synchronous inference).
- Inference API function: NeuronRuntime_inference (synchronous function call).
- Use Neuron Runtime V1 if there is no time overlap between each inference.
Neuron Runtime V2
- For multi-task execution in parallel (asynchronous inference).
- Inference API function: NeuronRuntimeV2_enqueue (asynchronous function call).
- Use Neuron Runtime V2 if the next inference will start before the previous inference has finished.
- Runtime V2 might increase power consumption, because parallel execution uses more hardware resources.
- Runtime V2 might increase memory footprint, because each parallel task maintains its own working buffer.
4.1.3 Quantization
4.1.3.1 Quantization Overview
Quantization is a model optimization technique that converts floating-point model data into lower-bit unsigned or signed integers. Quantization offers both model compression and performance improvements with a negligible loss in output quality, by taking advantage of the integer-only operator implementation on MediaTek platforms. In the NeuroPilot SDK, we provides two ways to quantize a model for different scenarios.
- Quantization-aware training emulates the inference-time quantization behavior and trains model parameters, such as weights and biases, while also considering quantization errors. In this scenario, the impact of quantization on the output quality is mitigated at deployment. In the NeuroPilot SDK, Quantization Tool provides quantization-aware training with extensions for different training frameworks.
- Post-training quantization is used on a pre-trained floating-point model directly, without incurring the additional burden of the model retraining pipeline. In the NeuroPilot SDK, Converter Tool provides post-training quantization techniques.
4.1.3.2 Quantization Tool Introduction
4.1.3.2.1 Background
Quantization Tool modifies a given model in order to simulate the quantization behavior and retrieve the proper quantization range, meaning the minimum and maximum values. After the model is modified, users can begin the fine-tuning process until they obtain satisfactory output quality. While modifying a model, Quantization Tool performs batch normalization folding and inserts quantizers at the necessary locations. A quantizer is a block of operations used to simulate the quantization impact and deduce the quantization range.
Batch normalization folding is a widely-used technique to improve the inference efficiency of models with batch normalization layers located after the convolutional and fully-connected layers. Because the batch normalization layer is folded into the weight and bias tensor of the preceding layers during inference, the quantization-aware training process cannot accurately simulate the effects of quantization without simulating this folding behavior. The NeuroPilot SDK applies the folding behavior described in this Google research paper. A quantizer is then applied to the weight tensor after the weight tensor’s values are scaled by the parameters of the batch normalization layer.
After the fine-tuning process is done, the modified model can be used for deployment. Converter Tool in the NeuroPilot SDK recognizes the quantizers inserted in the model, and uses their quantization information to quantize the model.
4.1.3.2.1.1 Quantization Representation
Currently, Quantization Tool only supports linear (also known as uniform) quantization. With linear quantization, floating-point values are mapped to quantized values in a uniform fashion. During the quantization-aware training process, the quantization parameters are represented by the quantization range and the quantization bitwidth. However, after conversion, we use zero_point and scale parameters to express the quantization mappings. The zero_point value is the quantized value that maps to the floating point zero value. The scale value describes the floating-point magnitude difference between two consecutive quantized values. The following shows the mapping formula:
|
Note: |
|
The mapping between the quantization range and quantization bitwidth to zero_point and scale is not a one-to-one mapping. During conversion, the quantization range is nudged in order to ensure the zero_point value exists. This nudging is also simulated in the quantization-aware training tool. |
4.1.3.2.1.2 Quantization Configuration File
Quantization Tool is based on a special quantization configuration file. This configuration file is a JSON file that records the quantizer targets, which are the locations where quantizers will be inserted, and the detailed settings of each quantizer. Quantization Tool provides APIs to produce this configuration file and configure global quantization settings. Users can also manually edit the configuration file to modify the quantization-aware training behavior.
|
Important: |
|
Quantization Tool requires that the model structure in training mode is identical to the model structure in evaluation mode. This is because the same configuration file is used for both the training model and the evaluation model. The evaluation model is the model used for deployment on MediaTek platforms. |
Following are the settings that can be adjusted on each of the quantizer targets.
4.1.3.2.1.2.1 Bitwidth
The quantization bitwidth is the bitwidth used by the integer values after quantization. The quantization bitwidth affects the number of integer values used to represent the floating-point data. The higher the bitwidth, the less quantization loss is incurred. Currently, Quantization Tool support a quantization bitwidth setting of 2 to 16, inclusive.
|
Important: |
|
MediaTek platforms currently only support 8-bit and 16-bit data types. As a result, the NeuroPilot Converter Tool round ups the quantization bitwidth. For example, if bitwidth is set to 12 then the tensor will be expressed as a 16-bit data type after conversion. However, the exact tensor data will still be in the 12-bit range, because the scale value is unaffected by the rounding up process. |
4.1.3.2.1.2.2 Quantizer Modes
The quantizer contains several operations that help to deduce the quantization range and simulate the quantization impact. The quantizer has two modes:
- Training mode: Used for model training. The quantizer keeps updating the quantization range based on the training data, and simulates the quantization impact.
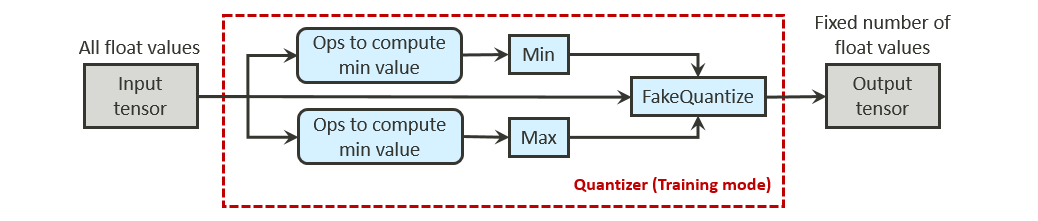
- Evaluation mode: Used for model deployment. The quantizer does not update the quantization range anymore. Instead, it restores the quantization range deduced from the training mode and follows the interface that the NeuroPilot model converter tool defines, such as the built-in FakeQuantize operators.
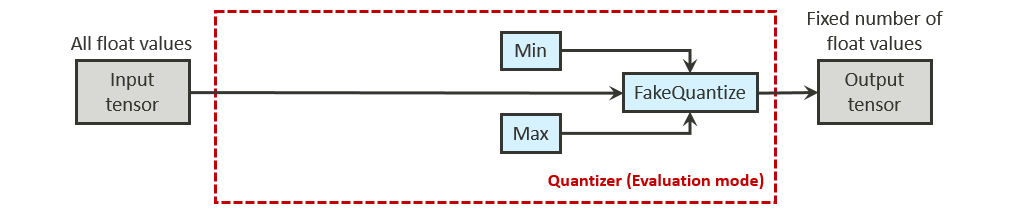
4.1.3.2.1.2.3 Quantizer Types and Settings
Quantization Tool defines several types of quantizer that control the behavior of how the quantization range is deduced, and how the quantization impact is simulated in the training mode. The supported quantizer types and their corresponding settings are described below.
- LastValueQuantizer: This quantizer uses the minimum and maximum values of the last batch of data that was fed to the model as the quantization range. It uses the official fake-quantize operator from the training framework to simulate the quantization impact and handle the back-propagation gradient. This quantizer is applied by default to the constant weight tensors of the convolutional operators.
- EMAQuantizer: This quantizer calculates the exponential moving average of the minimum and maximum values of all previous batches, and then uses these averages as the quantization range. It uses the official fake-quantize operator from the training framework to simulate the quantization impact and handle the back-propagation gradient. This quantizer is applied by default to the activation tensors, in order to avoid outliers and get a reasonable quantization range based on the training dataset. This quantizer type requires that the following settings are configured in the configuration file:
- ema_decay: A float value. The exponential moving average decay rate.
- AllValuesQuantizer: This quantizer uses the minimum and maximum values of all the batches of data that were fed to the model as the quantization range. It uses the official fake-quantize operator from the training framework to simulate the quantization impact and handle the back-propagation gradient.
- ConstantQuantizer: This quantizer takes a constant minimum and maximum value as the quantization range. These values do not change during training. It uses the official fake-quantize operator from the training framework to simulate the quantization impact and handle the back-propagation gradient. This quantizer type requires that the following settings are configured in the configuration file:
- min_vals: A float value or a list of float values. The minimum values to use. Each value must be less than or equal to zero.
- max_vals: A float value or a list of float values. The maximum values to use. Each value must be greater than or equal to zero.
- UnionQuantizer: This quantizer deduces the minimum and maximum values by unioning the quantization ranges of all the source quantizers (find the global minimum and maximum values of these quantization ranges). If only a single source quantizer target is provided, the minimum and maximum value is copied from it. It leverages the official fake-quantize operator to simulate the quantization impact and handle the back-propagation gradient. This quantizer type requires that the following settings are configured in the configuration file:
- sources: A list of string values. The target names of the source quantizers. Should match the target_name field in the quantizer_targets settings.
- LogTholdQuantizer: This quantizer trains a log2 threshold parameter to deduce the minimum and maximum values of the quantization range. This quantizer performs EMA for a given batch of data to initialize the threshold parameter. Currently, this quantizer is only supported in TensorFlow V1. This quantizer type requires that the following settings are configured in the configuration file:
- ema_decay: A float value. The exponential moving average decay rate used during initialization.
- num_init_batches: An integer value. The number of batches used during initialization.
4.1.3.2.1.2.4 Symmetric Quantization and Asymmetric Quantization
- Asymmetric quantization means the quantization range is asymmetric. This means the zero_point value can be any arbitrary value within the range defined by the quantized data type. Asymmetric quantization generally provides better quantization results, and better fits the typical activation value distribution.
- Symmetric quantization means the quantization range is symmetric. This results in a zero_point value of 0 for a signed quantized data type, such as int8. Symmetric quantization offers ways to simplify the integer-only operator implementation and avoid the extra cost required to handle the zero_point values.
4.1.3.2.1.2.5 Per-axis Quantization and Per-tensor Quantization
- Per-tensor quantization means there is only one set of quantization parameters, specifically the quantization range, for the entire tensor.
- Per-axis quantization means there are multiple quantization parameters along the given axis.
MediaTek platforms support per-axis quantization on the output channel axis of the convolution weight tensor. This is called per-output-channel quantization. Per-output-channel quantization allows more quantization granularity, and is especially useful for cases that the weight tensors have distinct value range across different output channels, such as in Mobilenet-V1 and Mobilenet-V2.
4.1.3.2.1.3 Manipulating the Quantization-Aware Training Behavior
Quantization Tool provides APIs for users to control the runtime behavior of quantization-aware training during the model training process.
4.1.3.2.1.3.1 Enabling/Disabling the Quantizers
A quantizer can have one of the following states:
- Enabled: The quantizer simulates the quantization impact on the corresponding target tensors.
- Disabled: The quantizer does not simulate the quantization impact on the corresponding target tensors. The quantizer keeps updating the quantization range based on the input training data, but the corresponding target tensors are not affected.
By default, all quantizers are enabled. Users can disable quantizers to disable the quantization impact at the start of the training process in the following cases:
- Training loss is not stable yet.
- The quantization ranges are not stable yet.
|
Warning: |
|
For quantizer types that use the training gradient to update the quantization ranges, disabling the quantizer forces the gradient values to become zero. In this case, the quantization ranges might not be updated as expected. |
4.1.3.2.1.3.2 Freezing/Unfreezing the Quantizers
A quantizer can have one of the following states:
- Not frozen: The quantizer keeps updating the quantization range based on the input training data.
- Frozen: The quantizer stops updating the quantization range based on the input training data. The quantizer still simulates the quantization impact and affects the corresponding target tensors.
By default, all the quantizers are not frozen.
|
Warning: |
|
For quantizer types that use the training gradient to update the quantization ranges, freezing the quantizer only forces the gradient values to become zero. However, if a momentum-based optimizer, such as Adam Optimizer, is used, then the quantization ranges are updated using the previous momentum values. |
4.1.3.2.1.3.3 Freezing/Unfreezing the Batch Normalization Layers
During the training process the batch normalization layers use the mini-batch statistics (i.e. mean and variance) to normalize the corresponding tensor and keep the running statistics of the mini-batch mean and variance. After freezing, these batch normalization layers act the same as they do in evaluation mode. This means that the running statistics are used to do normalization, and are no longer updated.
Freezing affects both standalone batch normalization layers, and batch normalization layers that have been folded to the previous affine layers, such as Conv2D.
4.1.3.2.2 TensorFlow V1 Quantization-Aware Training Tool
4.1.3.2.2.1 General Workflow
The following is a summary of the typical workflow for using the quantization-aware training tool in a TensorFlow V1 environment.
- Generate the quantization configuration file based on the model used for deployment.
- (Optional) Manually update the settings in the configuration file to obtain desired quantization-aware training behavior.
- After building the training graph, in the training script create a QuantizeHandler object and use the prepare function to prepare the training graph. The prepare function performs batchnorm folding and inserts the quantizers into the training graph, based on the quantization configuration file. Note that users should set is_training=True in the prepare function at this stage.
- Build the remaining training pipeline in the training script and start training. After the training has finished, save both the model checkpoint (containing the training variables, such as convolution weights) and the quantization-aware training checkpoint (containing the quantization range of all the quantizers).
- After building the evaluation graph, in the model export script create a QuantizeHandler object and use the prepare function to prepare the evaluation graph. Note that users should set is_training=False in the prepare function at this stage. This is because evaluation graph is prepared for deployment instead of model training.
- Restore both the model checkpoint and quantization-aware training checkpoint, freeze the variables, and exported the frozen graph as a file. This frozen model is a typical floating-point model with many FakeQuantize operators inserted at different locations in the graph.
- Use Converter Tool to convert the fake-quantized frozen model file to a quantized TensorFlow Lite model file.
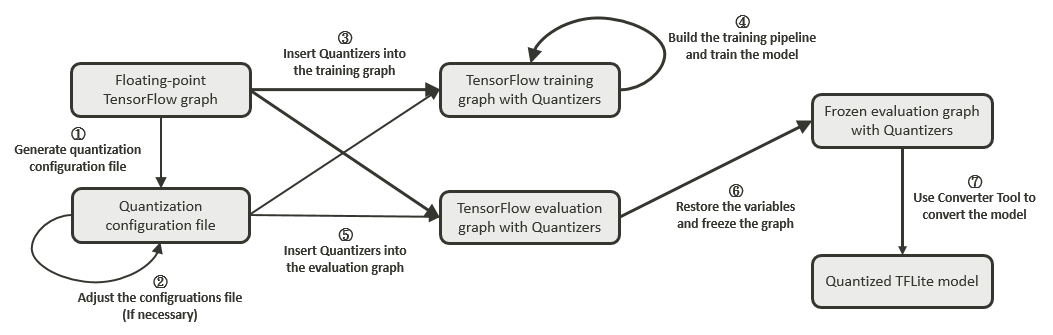
4.1.3.2.2.2 Generating the Quantization Configuration File
Quantization Tool provides two different methods for generating the quantization configuration file, which differ mainly in how the quantizer targets are deduced.
- Use Converter Tool:(Default) The quantizer targets are deduced based on how the given model is converted and optimized. For example, tensors that are folded during the conversion process are not included in the configuration file. With this approach, it is possible to identify each tensor that requires a quantization range during conversion.
- Use pre-defined patterns: The target tensors are deduced based on the pre-defined operation patterns. This method focuses on convolutional operations because these operations are more critical in the quantization-aware training process, and tries to match some commonly-used operation blocks in the graph. These operation blocks may include bias addition, activations, and bypass addition.
|
Note: |
|
Using pre-defined patterns is not guaranteed to find all the tensors that require quantization ranges during conversion. This is because the pre-defined patterns focuses on only the convolutional blocks of typical network structures. For some cases, users should also use the post-training quantization mechanism in order to produce a fully-quantized result model. |
4.1.3.2.3 TensorFlow V2 Quantization-Aware Training Tool
4.1.3.2.3.1 Limitations
The TensorFlow V2 quantization-aware training tool is designed on top of the Keras API. Therefore, users must build their models based on the tf.keras API.
Quantization Tool supports the following approaches of creating a network model through Keras API: Sequential Model (built with Sequential APIs), Functional Model (built with Functional APIs). Quantization Tool does not support Model subclassing. For more information on these three approaches, see 3 ways to create a Keras model with TensorFlow 2.0 (Sequential, Functional, and Model Subclassing).
Quantization Tool does not support the following kinds of special Keras layers: tf.keras.layers.Lambda layers, subclassing layers, TFOpLambda (or TensorFlowOpLayer) layers. When encountering one of these special Keras layers, Quantization Tool ignores the actual operators (or sub-layers) embedded inside the layer. This means Quantization Tool does not identify any quantizer targets from the layer. By manually adding extra quantizer targets in the quantization configuration file, users can insert quantizers at the output-side of the layer.
|
Note: |
|
The TFOpLambda (or TensorFlowOpLayer) layer is a special TensorFlow Keras layer that is inserted automatically when users use TensorFlow operations (instead of Keras layers) to construct a TensorFlow Keras model.
In the above example, the last layer in the model is either TFOpLambda layer or TensorFlowOpLayer layer, depending on the TensorFlow library version. |
4.1.3.2.3.2 General Workflow
The following is a summary of the typical workflow for using the quantization-aware training tool in a TensorFlow V2 environment.
- Manually rewrite the model to create a TensorFlow Keras Sequential Model or Functional Model.
- Generate the quantization configuration file based on the TensorFlow model. Before generating the quantization configuration, make sure to apply automatic TensorFlow Keras layer fusion using function mtk_quantization.tfv2.keras.fuse_layers.
- (Optional) Manually update the settings in the configuration file to obtain the desired quantization-aware training behavior.
- In the training script, after building the model and applying automatic TensorFlow Keras layer fusion, create a QuantizeHandler object and use the prepare function to prepare the training model for quantization. The prepare function inserts the quantizers into the Keras model, based on the quantization configuration file
- Build the remaining training pipeline in the training script and start training.
- After the training is finished, export the model with either SavedModel format or Keras H5 format.
- Use the converter tool to convert the fake-quantized model file to a quantized TensorFlow Lite model file.
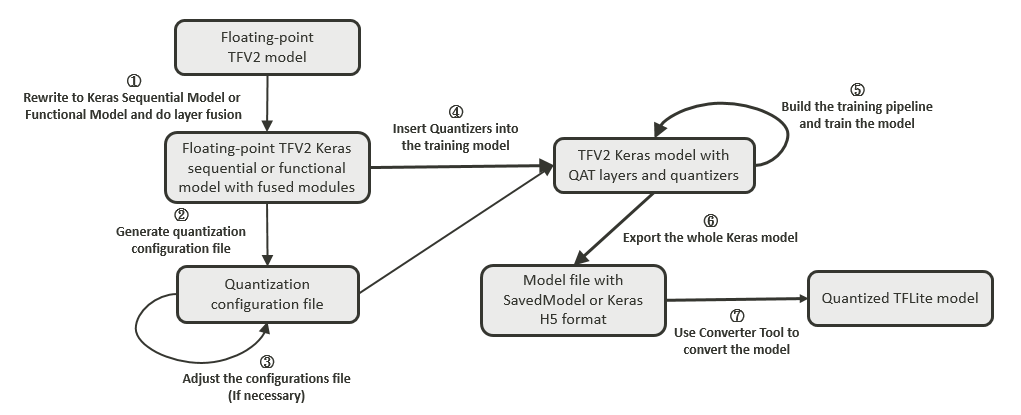
4.1.3.2.3.3 Automatic Module Fusion
To achieve better performance and higher accuracy, some operators such as Conv + BatchNorm + ReLU are fused together during the model deployment process. To better simulate the fusion impact during the training process, the quantization-aware training tool automatically traverses the given TensorFlow Keras model and fuses some layers together.
The returned TensorFlow Keras model is mathematically equivalent to the original model. However, in the returned model some of the layers might be replaced by fused layers defined by Quantization Tool. These fused layers are recognized and specially handled by Quantization Tool.
4.1.3.2.4 PyTorch Quantization-Aware Training Tool
4.1.3.2.4.1 General Workflow
The following is a summary of the typical workflow for using the quantization-aware training tool in a PyTorch environment.
- Manually rewrite the use of functional operators to module form whenever possible. For example, switch from the torch.relu and torch.nn.functional.relu functions to the torch.nn.ReLU module.
- Generate the quantization configuration file based on the PyTorch model. Make sure to apply automatic PyTorch module fusion using function mtk_quantization.pytorch.fuse_modules before generating the quantization configuration.
- (Optional) Manually update the settings in the configuration file to obtain the desired quantization-aware training behavior.
- In the training script, after building the model and applying automatic PyTorch module fusion, create a QuantizeHandler object and use the prepare function to prepare the training model for quantization. The prepare function inserts the quantizers into the training model, based on the quantization configuration file
- Build the remaining training pipeline in the training script and start training.
- After the training is finished, change the model to evaluation mode and generate a ScriptModule model for deployment using the torch.jit APIs. Users can also save the state dict of the model for future use. This state dict contains both the original model parameters, such as convolution weights, and the quantization-aware training related parameters.
- Use the converter tool to convert the fake-quantized ScriptModule model file to a quantized TensorFlow Lite model file.
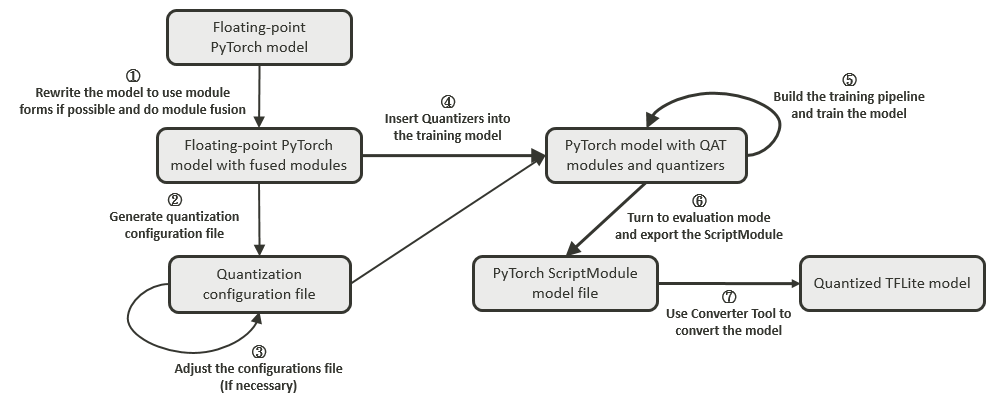
4.1.3.2.4.2 Rewriting the Operators to Module Form
Due to the dynamic computational graph convention adopted in PyTorch, the quantization-aware training tool analyzes and operates on the torch.nn.Module objects contained in the PyTorch model. For example, automatic module fusion is done on the children modules only, and activation quantizers are inserted to specific torch.nn.Module objects using the forward hook mechanism.
For this reason, we recommend that users rewrite their model so that it is built based on torch.nn.Module objects whenever possible. For example, switch from the torch.relu and torch.nn.functional.relu function to the torch.nn.ReLU module. For special operators that do not have module forms, such as arithmetic operators and the torch.cat function, PyTorch wrapper modules are defined in mtk_quantization.pytorch.functional.
|
Note: |
|
The quantization-aware training tool supports the PyTorch official intrinsic modules (torch.nn.intrinsic) produced from the official manual module fusion mechanism (the torch.quantization.fuse_modules API). The Automatic Module Fusion function supports these models, in order to better fit the capabilities of MediaTek platforms. |
|
Warning: |
|
The quantization-aware training tool supports the official torch.nn.quantized.FloatFunctional wrapper module introduced in the official tool. However, no further module fusion will be performed on this module. |
4.1.3.2.4.3 Automatic Module Fusion
To achieve better performance and higher accuracy, some operators such as Conv + BatchNorm + ReLU are fused together during the model deployment process. To better simulate the fusion impact during the training process, the quantization-aware training tool provides an automatic mechanism that traverses the given PyTorch model and fuses some children modules together.
The returned PyTorch model is mathematically equivalent to the original model. However, in the returned PyTorch model some of the modules might be replaced by fused modules defined in mtk_quantization.pytorch.intrinsic. These fused modules are recognized and specially handled by Quantization Tool.
|
Warning: |
|
The automatic module fusion function is based on an internal graph representation of the PyTorch model. This graph structure is generated based on the gradient connections recorded by the PyTorch Autograd engine. Therefore, we cannot support data-dependent control flow blocks. |
4.1.3.3 Quantization Tool Examples
This section provides some examples for using the quantization-aware training tool.
4.1.3.3.1 TensorFlow V1 Example (with Session)
4.1.3.3.1.1 Model Structure
import tensorflow as tf
def build_model(image, is_training):
"""Builds a simple convolutional neural network for the MNIST dataset.
Args:
image: The input tensor of shape Nx784.
is_training: A bool value. Whether this model is built for training or inference.
Returns:
out: The prediction logits of shape Nx10
"""
with tf.variable_scope('model', reuse=tf.AUTO_REUSE):
image = tf.reshape(image, shape=[-1, 28, 28, 1])
conv1 = tf.layers.conv2d(image, 32, 5, activation=tf.nn.relu)
conv1 = tf.layers.max_pooling2d(conv1, 2, 2)
conv2 = tf.layers.conv2d(conv1, 64, 3, activation=tf.nn.relu)
conv2 = tf.layers.max_pooling2d(conv2, 2, 2)
fc1 = tf.contrib.layers.flatten(conv2)
fc1 = tf.layers.dense(fc1, 1024)
if is_training:
fc1 = tf.layers.dropout(fc1, rate=0.1, training=is_training)
out = tf.layers.dense(fc1, 10)
return out
4.1.3.3.1.2 Training and Exporting the Floating-Point Model
Here, we train the model for 30,000 steps to obtain the pre-trained checkpoint files. The number of steps is just an arbitrary number for demonstration.
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# Build the model
image = tf.placeholder(tf.float32, [None, 784], name='image')
label = tf.placeholder(tf.int64, [None], name='label')
output = build_model(image, is_training=True)
# Build training pipelines
loss = tf.losses.sparse_softmax_cross_entropy(labels=label, logits=output)
loss = tf.reduce_mean(loss)
train_op = tf.train.AdamOptimizer(1e-4).minimize(loss)
mnist = input_data.read_data_sets('./workspace')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(30000):
batch_image, batch_label = mnist.train.next_batch(32)
sess.run(train_op, {image: batch_image, label: batch_label})
# Export the checkpoint
tf.train.Saver().save(sess, './workspace/float/model')
After the checkpoint files are generated, we can export the frozen evaluation model (e.g. the GraphDef file).
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
image = tf.placeholder(tf.float32, [None, 784], name='image')
output = build_model(image, is_training=False)
mnist = input_data.read_data_sets('./workspace')
with tf.Session() as sess:
tf.train.Saver().restore(sess, './workspace/float/model')
# Evaluate the model
output_npy = sess.run(output, {image: mnist.test.images})
accuracy = np.mean(np.equal(np.argmax(output_npy, axis=1), mnist.test.labels))
print('\nTest accuracy {}%'.format(accuracy * 100))
frozen_graph_def = tf.graph_util.convert_variables_to_constants(
sess, sess.graph_def, [output.op.name]
)
with open('./workspace/float/model.pb', 'wb') as f:
f.write(frozen_graph_def.SerializeToString())
4.1.3.3.1.3 Generating the Quantization Configuration File
Before doing quantization-aware training, we need to generate the quantization configuration file based on the frozen floating-point evaluation model.
import mtk_quantization
generator = mtk_quantization.tfv1.MixedPrecisionConfigGenerator.from_frozen_graph_def_file(
'./workspace/float/model.pb', ['image'], [[1, 784]], ['model/dense_1/BiasAdd']
)
generator.use_per_output_channel_quantization = False
generator.export_config('./workspace/quant_config.json')
The quantization configuration file will be similar to the following. Users can edit this configuration file to achieve the desired behavior.
{
"version": "...",
"quantizer_targets": {
"constant_weights": [
{
"target_name": "model/conv2d/kernel/read:0",
"bitwidth": 8,
"quantizer": {
"type": "LastValueQuantizer",
"settings": {}
},
...
},
{
"target_name": "model/conv2d_1/kernel/read:0",
"bitwidth": 8,
"quantizer": {
"type": "LastValueQuantizer",
"settings": {}
},
...
},
{
"target_name": "model/dense/kernel/read:0",
"bitwidth": 8,
"quantizer": {
"type": "LastValueQuantizer",
"settings": {}
},
...
},
{
"target_name": "model/dense_1/kernel/read:0",
"bitwidth": 8,
"quantizer": {
"type": "LastValueQuantizer",
"settings": {}
},
...
}
],
"activations": [
{
"target_name": "model/conv2d/Relu:0",
"bitwidth": 8,
"quantizer": {
"type": "EMAQuantizer",
"settings": {
"ema_decay": 0.999
}
},
...
},
{
"target_name": "model/conv2d_1/Relu:0",
"bitwidth": 8,
"quantizer": {
"type": "EMAQuantizer",
"settings": {
"ema_decay": 0.999
}
},
...
},
{
"target_name": "model/dense/BiasAdd:0",
"bitwidth": 8,
"quantizer": {
"type": "EMAQuantizer",
"settings": {
"ema_decay": 0.999
}
},
...
},
{
"target_name": "model/dense_1/BiasAdd:0",
"bitwidth": 8,
"quantizer": {
"type": "EMAQuantizer",
"settings": {
"ema_decay": 0.999
}
},
...
}
]
},
"generator_settings": {
...
}
}
4.1.3.3.1.4 Fine-Tuning the Model with Quantization-Aware Training APIs
Here, we do quantization-aware training based on the floating-point checkpoint files and the above quantization configuration. This is done by using the QuantizeHandler class in the training code.
import mtk_quantization
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
image = tf.placeholder(tf.float32, [None, 784], name='image')
label = tf.placeholder(tf.int64, [None], name='label')
output = build_model(image, is_training=True)
quantize_handler = mtk_quantization.tfv1.QuantizeHandler()
output, = quantize_handler.prepare(True, './workspace/quant_config.json', tensors_to_update=[output])
# Build training pipelines
loss = tf.losses.sparse_softmax_cross_entropy(labels=label, logits=output)
loss = tf.reduce_mean(loss)
train_op = tf.train.AdamOptimizer(1e-4).minimize(loss)
mnist = input_data.read_data_sets('./workspace')
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, './workspace/float/model')
quantize_handler.init(sess)
for i in range(1000):
batch_image, batch_label = mnist.train.next_batch(32)
sess.run(train_op, {image: batch_image, label: batch_label})
saver.save(sess, './workspace/qat/model')
quantize_handler.save(sess, './workspace/qat/qat')
After the training process is finished, we can export the frozen evaluation graph with the FakeQuantize operators inside.
import mtk_quantization
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
image = tf.placeholder(tf.float32, [None, 784], name='image')
output = build_model(image, is_training=False)
quantize_handler = mtk_quantization.tfv1.QuantizeHandler()
output, = quantize_handler.prepare(False, './workspace/quant_config.json', tensors_to_update=[output])
mnist = input_data.read_data_sets('./workspace')
with tf.Session() as sess:
tf.train.Saver().restore(sess, './workspace/qat/model')
quantize_handler.restore(sess, './workspace/qat/qat')
# Evaluate the model
output_npy = sess.run(output, {image: mnist.test.images})
accuracy = np.mean(np.equal(np.argmax(output_npy, axis=1), mnist.test.labels))
print('\nTest accuracy {}%'.format(accuracy * 100))
frozen_graph_def = tf.graph_util.convert_variables_to_constants(
sess, sess.graph_def, [output.op.name]
)
with open('./workspace/qat/model.pb', 'wb') as f:
f.write(frozen_graph_def.SerializeToString())
Integrating with Variable Sharing Training Method “””””””””””^^””””””””””””””””””””””””””””””””””””
In addition to the above two-pass method, where the training and evaluation parts are in different graphs , the QuantizeHandler class also supports the variable sharing method by using tf.variable_scope(). With the variable sharing convention, the training and evaluation parts reside in a single graph and variables are shared between the two parts.
import numpy as np
import mtk_quantization
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
image = tf.placeholder(tf.float32, [None, 784], name='image')
label = tf.placeholder(tf.int64, [None], name='label')
train_output = build_model(image, is_training=True)
eval_output = build_model(image, is_training=False)
# The training mode quantize handler
train_quantize_handler = mtk_quantization.tfv1.QuantizeHandler()
train_output, = train_quantize_handler.prepare(
True, './workspace/quant_config.json', tensors_to_update=[train_output]
)
# The evaluation mode quantize handler. It uses all the variables created by the train_quantize_handler
eval_quantize_handler = mtk_quantization.tfv1.QuantizeHandler()
eval_output, = eval_quantize_handler.prepare(
False,
'./workspace/quant_config.json',
tensors_to_update=[eval_output],
variable_sharing_scope_mappings={'model/': 'model_1/'}
)
# Build training pipelines
loss = tf.losses.sparse_softmax_cross_entropy(labels=label, logits=train_output)
loss = tf.reduce_mean(loss)
train_op = tf.train.AdamOptimizer(1e-4).minimize(loss)
mnist = input_data.read_data_sets('./workspace')
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, './workspace/float/model')
train_quantize_handler.init(sess)
for step in range(1000):
batch_image, batch_label = mnist.train.next_batch(32)
sess.run(train_op, {image: batch_image, label: batch_label})
if (step + 1) % 50 == 0:
eval_output_npy = sess.run(eval_output, {image: mnist.test.images})
accuracy = np.mean(np.equal(np.argmax(eval_output_npy, axis=1), mnist.test.labels))
print('Step #{}: Test accuracy {}%'.format(step + 1, accuracy * 100))
saver.save(sess, './workspace/qat/model')
train_quantize_handler.save(sess, './workspace/qat/qat')
After the training process is finished, we can export the frozen evaluation graph, with FakeQuantize operators inside, using the above scripts.
4.1.3.3.1.5 Converting to a Quantized TFLite Model
After the quantization-aware training process, the resulting TensorFlow model can be converted to a quantized TFLite model based on the quantization ranges (i.e. the minimum and maximum values) deduced from the training process.
import mtk_converter
converter = mtk_converter.TensorFlowV1Converter.from_frozen_graph_def_file(
'./workspace/qat/model.pb',
['image'],
[[1, 784]],
['model/dense_1/BiasAdd/act_quant/FakeQuantWithMinMaxVars']
)
converter.quantize = True
converter.input_value_ranges = [(0.0, 1.0)]
converter.convert_to_tflite(output_file='./workspace/qat/model.tflite')
The structure of the quantized TFLite model would be like:
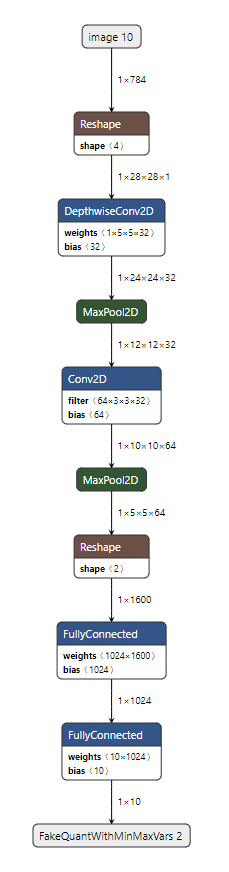
4.1.3.3.2 TensorFlow V1 Example (with Estimator)
4.1.3.3.2.1 Model Function
Defines the model_fn that returns a tf.estimator.EstimatorSpec.
import tensorflow as tf
def neural_net(input_dict):
"""Define the network structure."""
x = input_dict['input']
x = tf.reshape(x, [-1, 28, 28, 1])
conv1 = tf.layers.conv2d(x, filters=16, kernel_size=5, padding='same', activation=tf.nn.relu)
pool1 = tf.layers.max_pooling2d(conv1, pool_size=2, strides=2)
conv2 = tf.layers.conv2d(
pool1, filters=36, kernel_size=5, padding='same', activation=tf.nn.relu
)
pool2 = tf.layers.max_pooling2d(conv2, pool_size=2, strides=2)
flat = tf.layers.flatten(pool2)
logits = tf.layers.dense(flat, units=10)
return logits
def model_fn(features, labels, mode, params):
"""Define the model function for tf.estimator."""
# Build the neural network
logits = neural_net(features)
# If prediction mode, early return
if mode == tf.estimator.ModeKeys.PREDICT:
estim_specs = tf.estimator.EstimatorSpec(mode, predictions=logits)
return estim_specs
# Define loss
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=logits, labels=tf.cast(labels, tf.int32)
),
name='loss'
)
if mode == tf.estimator.ModeKeys.EVAL:
# Evaluate the accuracy of the model
acc_op = tf.metrics.accuracy(labels=labels, predictions=tf.argmax(logits, axis=1))
estim_specs = tf.estimator.EstimatorSpec(
mode=mode, loss=loss, eval_metric_ops={'accuracy': acc_op}
)
return estim_specs
assert mode == tf.estimator.ModeKeys.TRAIN
# Define train_op
optimizer = tf.train.AdamOptimizer(learning_rate=params['learning_rate'])
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
estim_specs = tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
return estim_specs
4.1.3.3.2.2 Training and Exporting the Floating-Point Model
Here, we train the model for 2,000 steps to obtain the pre-trained SavedModel files. The number of steps is just an arbitrary number for demonstration.
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('./workspace/dataset')
tf.logging.set_verbosity(tf.logging.INFO)
NUM_STEPS = 2000
BATCH_SIZE = 128
# Build the Estimator
params = {'learning_rate': 1e-3}
estimator = tf.estimator.Estimator(model_fn, params=params, model_dir='./workspace/float')
# Define the input function for training
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={'input': mnist.train.images},
y=mnist.train.labels,
batch_size=BATCH_SIZE,
num_epochs=None,
shuffle=True
)
# Train the Model
estimator.train(input_fn=train_input_fn, steps=NUM_STEPS)
# Define the input function for evaluation
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={'input': mnist.test.images},
y=mnist.test.labels,
batch_size=BATCH_SIZE,
shuffle=False
)
# Evaluate the Model
eval_results = estimator.evaluate(input_fn=eval_input_fn)
print("Testing Accuracy:", eval_results['accuracy'])
# Export as SavedModel
def serving_input_receiver_fn():
"""Input function for serving."""
input_ = tf.placeholder(tf.float32, shape=[1, 784], name='model_input')
features = {'input': input_}
receiver_tensors = {'input': input_}
return tf.estimator.export.ServingInputReceiver(features, receiver_tensors)
estimator.export_saved_model('./workspace/float/saved_model', serving_input_receiver_fn)
The SavedModel is written to a timestamped export directory under ./workspace/float/saved_model.
4.1.3.3.2.3 Generating the Quantization Configuration File
Before doing quantization-aware training, we need to generate the quantization configuration file based on the floating-point evaluation SavedModel.
mtk_generate_tfv1_quantization_config_file \
--input_saved_model_dir=./workspace/float/saved_model/$(TIMESTAMP) \
--use_per_output_channel_quantization=False \
--output_file=./workspace/quant_config.json
4.1.3.3.2.4 Fine-Tuning the Model with Quantization-Aware Training APIs
Here, we do quantization-aware training based on the floating-point SavedModel files and the above quantization configuration. This is done by using the prepare_model_fn function in the training code.
Note that the quantization-related variables will be stored together with the model variables after calling prepare_model_fn.
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mtk_quantization
mnist = input_data.read_data_sets('./workspace/dataset')
tf.logging.set_verbosity(tf.logging.INFO)
NUM_STEPS = 1000
BATCH_SIZE = 128
# Prepare the model_fn for quantization-aware training
context, model_fn = mtk_quantization.tfv1.estimator.prepare_model_fn(
model_fn, './workspace/quant_config.json'
)
# Build the Estimator
config = tf.estimator.RunConfig(save_checkpoints_steps=500)
params = {'learning_rate': 1e-4}
estimator = tf.estimator.Estimator(
model_fn,
params=params,
config=config,
model_dir='./workspace/qat',
warm_start_from='./workspace/float'
)
# Define the input function for training
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={'input': mnist.train.images},
y=mnist.train.labels,
batch_size=BATCH_SIZE,
num_epochs=None,
shuffle=True
)
# Train the model
estimator.train(input_fn=train_input_fn, steps=NUM_STEPS)
# Define the input function for evaluation
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={'input': mnist.test.images},
y=mnist.test.labels,
batch_size=BATCH_SIZE,
shuffle=False
)
# Evaluate the model
eval_results = estimator.evaluate(input_fn=eval_input_fn)
print("Testing Accuracy:", eval_results['accuracy'])
# Export as SavedModel
def serving_input_receiver_fn():
"""Input function for serving."""
input_ = tf.placeholder(tf.float32, shape=[1, 784], name='model_input')
features = {'input': input_}
receiver_tensors = {'input': input_}
return tf.estimator.export.ServingInputReceiver(features, receiver_tensors)
estimator.export_saved_model('./workspace/qat/saved_model', serving_input_receiver_fn)
The SavedModel is written to a timestamped export directory under ./workspace/qat/saved_model.
Note that users can use the context returned by prepare_model_fn to further control the created QuantizeHandler by writing hooks. The following example hook prints the quantizer status during evaluation.
class PrintQuantizerStatusEvalHook(tf.estimator.SessionRunHook):
"""Hook to print quantizer status during evaluation."""
def __init__(self, context):
"""Init PrintQuantizerStatusEvalHook."""
self._context = context
def after_create_session(self, sess, coord):
"""Print the status of the eval quantizer."""
print('-------')
print('Dump quantizer status for id {}'.format(id(self._context.eval_quantize_handler)))
print('')
for key, quantizer in self._context.eval_quantize_handler._quantizer_dict.items():
print(
'{}: is_training={}, minmax={}, frozen={}'.format(
key,
quantizer._is_training,
quantizer.get_minmax(sess),
quantizer.is_frozen(sess)
)
)
eval_print_status_hook = PrintQuantizerStatusEvalHook(context)
estimator.evaluate(input_fn=eval_input_fn, hooks=[eval_print_status_hook])
The following example hook prints the quantizer status and freezes the quantizer during training.
class PrintQuantizerStatusTrainHook(tf.estimator.SessionRunHook):
"""Hook to print quantizer status during training."""
def __init__(self, context, print_every_n_steps, freeze_after_n_print=None):
"""Init PrintQuantizerStatusTrainHook."""
self._context = context
self._global_step_tensor = None
self._print_every_n_steps = print_every_n_steps
self._print_count = 0
self._freeze_after_n_print = freeze_after_n_print
def begin(self):
"""Get global_setp_tensor."""
self._global_step_tensor = tf.train.get_or_create_global_step()
def after_run(self, run_context, run_values):
"""Print the status of training quantizer and freeze the quantizer."""
sess = run_context.session
step = sess.run(self._global_step_tensor)
if step % self._print_every_n_steps != 0:
return
print('-------')
print(
'Dump quantizer status for id {} @ step {}'
''.format(id(self._context.train_quantize_handler), step)
)
print('')
for key, quantizer in self._context.train_quantize_handler._quantizer_dict.items():
print(
'{}: is_training={}, minmax={}, frozen={}'.format(
key,
quantizer._is_training,
quantizer.get_minmax(sess),
quantizer.is_frozen(sess)
)
)
self._print_count += 1
if (
self._freeze_after_n_print is not None and
self._freeze_after_n_print == self._print_count
):
self._context.train_quantize_handler.freeze_all_quantizers(sess)
train_print_status_hook = PrintQuantizerStatusTrainHook(context, 100, freeze_after_n_print=5)
estimator.train(input_fn=train_input_fn, hooks=[train_print_status_hook], steps=1000)
4.1.3.3.2.5 Converting to a Quantized TFLite Model
After the quantization-aware training process, the resulting TensorFlow model can be converted to a quantized TFLite model based on the quantization ranges (i.e., min/max values) deduced from the training process.
mtk_tensorflow_v1_converter
--input_saved_model_dir=./workspace/qat/saved_model/$(TIMESTAMP) \
--output_file=./workspace/qat/model.tflite \
--quantize=True \
--input_value_ranges=0.0,1.0
4.1.3.3.3 TensorFlow V2 Example
4.1.3.3.3.1 Model Structure
Suppose the original model structure is as follows.
import tensorflow as tf
def build_model():
"""Build the model.
Returns:
A Keras sequential model.
"""
model = tf.keras.Sequential(
[
tf.keras.layers.Reshape((28, 28, 1), input_shape=(28, 28)),
tf.keras.layers.Conv2D(32, 5, activation='relu'),
tf.keras.layers.Conv2D(64, 3, use_bias=False),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.ReLU(),
tf.keras.layers.MaxPool2D(2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128),
tf.keras.layers.Dense(10),
]
)
return model
4.1.3.3.3.2 Training the Floating-Point Model
Here, we train the model for two epochs to obtain the pre-trained model file.
import tensorflow as tf
from model import build_model
# Load dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255., x_test / 255.
# Build the model
model = build_model()
# Build training pipeline
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=2, validation_data=(x_test, y_test))
model.save('./workspace/float/model')
4.1.3.3.3.3 Generating the Quantization Configuration File
Before doing quantization-aware training, we need to generate the quantization configuration file based on the TensorFlow model.
import tensorflow as tf
import mtk_quantization
model = tf.keras.models.load_model('workspace/float/model')
model = mtk_quantization.tfv2.keras.fuse_layers(model)
config_generator = mtk_quantization.tfv2.keras.ConfigGenerator(model)
config_generator.export_config('./workspace/quant_config.json')
The quantization configuration file is similar to the following. Users can edit this configuration file to achieve the desired behavior.
{
"version": "...",
"quantizer_targets": {
"constant_weights": [
{
"target_name": "conv2d:kernel",
...
},
{
"target_name": "conv2d_1:kernel",
...
},
{
"target_name": "dense:kernel",
...
},
{
"target_name": "dense_1:kernel",
...
}
],
"activations": [
{
"target_name": "conv2d:activation",
...
},
{
"target_name": "conv2d_1:output",
...
},
{
"target_name": "dense:activation",
...
},
{
"target_name": "dense_1:activation",
...
}
]
},
"generator_settings": {
...
}
}
4.1.3.3.3.4 Fine-Tuning the Model with Quantization-Aware Training APIs
Here, we do quantization-aware training based on the pre-trained model and the above quantization configuration. This is done by using the QuantizeHandler class in the training code.
import tensorflow as tf
import mtk_quantization
# Load dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255., x_test / 255.
# Load the pre-trained model
model = tf.keras.models.load_model('workspace/float/model')
# Prepare the model for quantization-aware training
model = mtk_quantization.tfv2.keras.fuse_layers(model)
quantize_handler = mtk_quantization.tfv2.keras.QuantizeHandler()
qat_model = quantize_handler.prepare(model, 'workspace/quant_config.json')
# Build training pipeline
qat_model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
qat_model.fit(x_train, y_train, epochs=1, validation_data=(x_test, y_test))
qat_model.save('./workspace/qat/model')
4.1.3.3.3.5 Converting to a Quantized TFLite Model
After finishing the quantization-aware training process, the resulting model can be converted to a quantized TFLite model based on the quantization ranges (i.e. the minimum and maximum values) deduced from the training process.
import mtk_converter
converter = mtk_converter.TensorFlowConverter.from_saved_model_dir(
'./workspace/qat/model', default_batch_size=1
)
converter.quantize = True
converter.input_value_ranges = [(0.0, 1.0)]
converter.convert_to_tflite(output_file='./workspace/qat/model.tflite')
The structure of the quantized TFLite model looks like this:
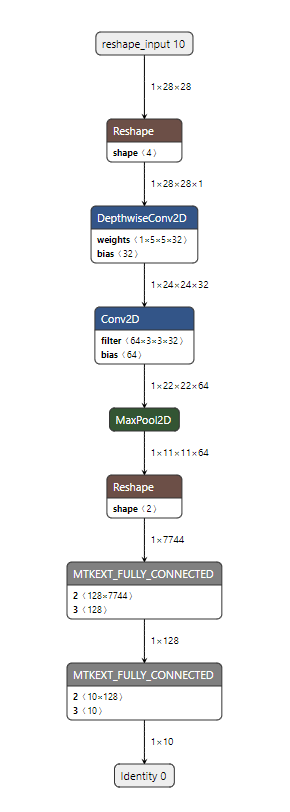
|
Note: |
|
The resulting model contains MediaTek TFLite custom operator extensions (i.e., the MTKEXT_FULLY_CONNECTED operators) because we use per-output-channel quantization for the FullyConnected operators. This setting is beyond the definition of the TFLite built-in operators. |
4.1.3.3.4 PyTorch Example
4.1.3.3.4.1 Model structure
Suppose the original model structure is as follows.
import torch
import torch.nn.functional as F
class Net(torch.nn.Module):
"""The network model."""
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 16, 5)
self.conv2 = torch.nn.Conv2d(16, 16, 3, padding=1, bias=False)
self.bn = torch.nn.BatchNorm2d(16)
self.pool = torch.nn.MaxPool2d(2)
self.linear1 = torch.nn.Linear(2304, 128)
self.linear2 = torch.nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
tmp = self.conv2(x)
tmp = self.bn(tmp)
tmp = F.relu(tmp)
x = x + tmp
x = self.pool(x)
x = torch.flatten(x, 1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
To do quantization-aware training, we first rewrite the source code to use torch.nn.Modules to construct the model if possible.
The result is as follows.
import torch
import torch.nn.functional as F
import mtk_quantization
class QuantizableNet(torch.nn.Module):
"""The modified network model for quantization-aware training."""
def __init__(self):
super(QuantizableNet, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 16, 5)
self.conv2 = torch.nn.Conv2d(16, 16, 3, padding=1, bias=False)
self.bn = torch.nn.BatchNorm2d(16)
self.relu1 = torch.nn.ReLU()
self.add = mtk_quantization.pytorch.functional.Add()
self.pool = torch.nn.MaxPool2d(2)
self.linear1 = torch.nn.Linear(2304, 128)
self.relu2 = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
tmp = self.conv2(x)
tmp = self.bn(tmp)
tmp = self.relu1(tmp)
x = self.add(x, tmp)
x = self.pool(x)
x = torch.flatten(x, 1)
x = self.linear1(x)
x = self.relu2(x)
x = self.linear2(x)
return x
|
Note: |
|
After applying automatic module fusion on the QuantizableNet instance, we can observe the following:
|
4.1.3.3.4.2 Training the Floating-Point Model
Here, we train the model for two epochs to obtain the pre-trained state_dict file.
import os
import torch
import torch.nn.functional as F
import torchvision
from model import QuantizableNet
transform = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
]
)
dataset = torchvision.datasets.MNIST('./workspace', train=True, download=True, transform=transform)
dataset_loader = torch.utils.data.DataLoader(dataset, batch_size=64)
eval_dataset = torchvision.datasets.MNIST('./workspace', train=False, download=True, transform=transform)
eval_dataset_loader = torch.utils.data.DataLoader(eval_dataset, batch_size=1000)
model = QuantizableNet()
model.train()
# Train the model
optimizer = torch.optim.Adadelta(model.parameters(), lr=1e-2)
for epoch in range(2):
for batch_idx, (data, target) in enumerate(dataset_loader):
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
os.makedirs('./workspace/float', exist_ok=True)
torch.save(model.state_dict(), './workspace/float/state_dict.pt')
# Test the model
model.eval()
correct = 0
for data, target in eval_dataset_loader:
pred = model(data).argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print('Accuracy: {:.2f}%'.format(100 * correct / len(eval_dataset_loader.dataset)))
4.1.3.3.4.3 Generating the Quantization Configuration File
Before doing quantization-aware training, we need to generate the quantization configuration file based on the PyTorch model.
import torch
import mtk_quantization
from model import QuantizableNet
example_input = torch.randn(1, 1, 28, 28)
model = QuantizableNet()
model = mtk_quantization.pytorch.fuse_modules(model, example_input)
config_generator = mtk_quantization.pytorch.ConfigGenerator(model)
config_generator.export_config('./workspace/quant_config.json', example_inputs=example_input)
|
Note: |
|
The model structure will not change based on the input data, so we can pass a random tensor as example input data. |
The quantization configuration file is similar to the following. Users can edit this configuration file to achieve the desired behavior.
{
"version": "...",
"quantizer_targets": {
"constant_weights": [
{
"target_name": "linear2.weight",
...
},
{
"target_name": "conv1.weight",
...
},
{
"target_name": "conv2.folded_weight",
...
},
{
"target_name": "linear1.weight",
...
}
],
"activations": [
{
"target_name": "conv2",
...
},
{
"target_name": "conv1",
...
},
{
"target_name": "linear1",
...
},
{
"target_name": "add",
...
},
{
"target_name": "linear2",
...
}
]
},
"generator_settings": {
...
}
}
4.1.3.3.4.4 Fine-Tuning the Model with Quantization-Aware Training APIs
Here, we do quantization-aware training based on the pre-trained state_dict file and the above quantization configuration. This is done by using the QuantizeHandler class in the training code.
import mtk_quantization
import os
import torch
import torch.nn.functional as F
import torchvision
from model import QuantizableNet
transform = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
]
)
dataset = torchvision.datasets.MNIST('./workspace', train=True, download=True, transform=transform)
dataset_loader = torch.utils.data.DataLoader(dataset, batch_size=64)
# Note that the pre-trained state_dict should be restored before module fusion.
# It is because we do not apply module fusion when producing the pre-trained model.
model = QuantizableNet()
model.load_state_dict(torch.load('./workspace/float/state_dict.pt'))
# Prepare the model for quantization-aware training
model = mtk_quantization.pytorch.fuse_modules(model, torch.randn(1, 1, 28, 28))
quantize_handler = mtk_quantization.pytorch.QuantizeHandler()
qat_model = quantize_handler.prepare(model, './workspace/quant_config.json')
qat_model.train()
# Train the model
optimizer = torch.optim.Adadelta(qat_model.parameters(), lr=1e-4)
for epoch in range(2):
for batch_idx, (data, target) in enumerate(dataset_loader):
optimizer.zero_grad()
output = qat_model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
os.makedirs('./workspace/qat', exist_ok=True)
torch.save(qat_model.state_dict(), './workspace/qat/state_dict.pt')
|
Note: |
|
We do not apply module fusion when producing the pre-trained state_dict file, so we should load it back before the module fusion step. Otherwise, the state_dict file should be loaded after the module fusion step. |
After the training process is finished, we can export the ScriptModule model file, with FakeQuantize operators inside, for deployment.
import mtk_quantization
import os
import torch
import torchvision
from model import QuantizableNet
transform = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
]
)
dataset = torchvision.datasets.MNIST('./workspace', train=False, download=True, transform=transform)
dataset_loader = torch.utils.data.DataLoader(dataset, batch_size=1000)
# Load the state_dict after quantization-aware training
model = QuantizableNet()
model = mtk_quantization.pytorch.fuse_modules(model, torch.randn(1, 1, 28, 28))
quantize_handler = mtk_quantization.pytorch.QuantizeHandler()
qat_model = quantize_handler.prepare(model, './workspace/quant_config.json')
qat_model.load_state_dict(torch.load('./workspace/qat/state_dict.pt'))
# Test the model
qat_model.eval()
correct = 0
for data, target in dataset_loader:
pred = qat_model(data).argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
print('Accuracy: {:.2f}%'.format(100 * correct / len(dataset_loader.dataset)))
# Export as ScriptModule file
torch.jit.save(torch.jit.trace(qat_model.cpu().eval(), torch.randn(1, 1, 28, 28)), './workspace/qat/model.pt')
4.1.3.3.4.5 Converting to a Quantized TFLite Model
After finishing the quantization-aware training process, the resulting ScriptModule model file can be converted to a quantized TFLite model based on the quantization ranges (i.e. the minimum and maximum values) deduced from the training process.
import mtk_converter
converter = mtk_converter.PyTorchConverter.from_script_module_file(
'./workspace/qat/model.pt',
[[1, 1, 28, 28]],
)
converter.quantize = True
converter.input_value_ranges = [(-0.4242, 2.8215)]
converter.convert_to_tflite(output_file='./workspace/qat/model.tflite')
The structure of the quantized TFLite model looks like this:
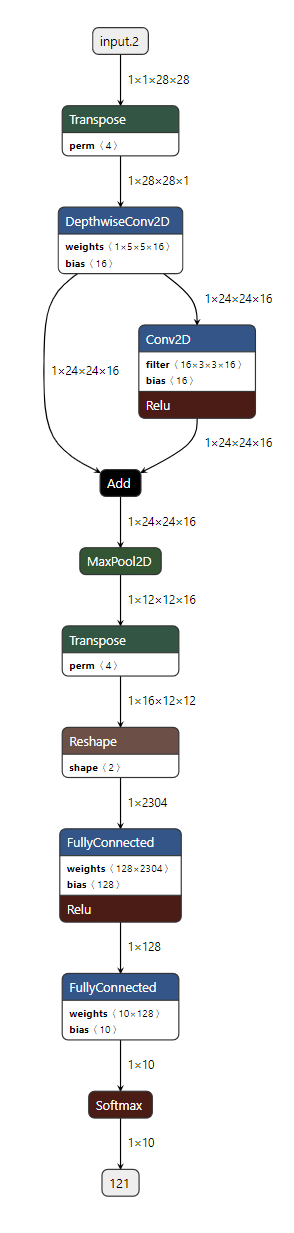
|
Note: |
|
The resulting model contains MediaTek TFLite custom operator extensions (i.e., the MTKEXT_FULLY_CONNECTED operators) because we use per-output-channel quantization for the FullyConnected operators. This setting is beyond the definition of the TFLite built-in operators. |
4.2 Application Development
4.2.1 Neuron Adapter API
Neuron Adapter API provides APIs to create, compile, and execute neural network models on MediaTek devices.
The sequence of API calls is similar to the Android NNAPI programming flow. For a full list of APIs, see 5.3. Neuron Adapter API Reference.
4.2.1.1 Development Workflow
Neuron Adapter API follows the same programming model as the Android Neural Networks API (NNAPI).

The sequence of API calls is as follows.
- Build a model.
- Call NeuronModel_create to create a model.
- Call NeuronModel_addOperand, NeuronModel_setOperandValue, NeuronModel_addOperation and NeuronModel_identifyInputsAndOutputs to configure the content of the model.
- Call NeuronModel_finish when the model configuration is finished.
- Compile the model.
- Call NeuronCompilation_create to create a new compilation context from the model constructed in step 1.
- Call NeuronCompilation_finish to trigger the compilation flow in the Neuron software layer.
- Perform inference on the model.
- Call NeuronExecution_create to create a new inference context from the compilation finished in step 2b.
- Call NeuronExecution_setInput or NeuronExecution_setInputFromMemory to configure inputs.
- Call NeuronExecution_setOuput or NeuronExecution_setOutputFromMemory to configure outputs.
- Call NeuronExecution_compute to start synchronous inference.
- Clean up resources.
- Call NeuronExecution_free, NeuronCompilation_free, and NeuronModel_free to clean up the inference content, compilation context, and model.
4.2.1.2 Example: Using Neuron Adapter API
#include <dlfcn.h>
#include <fstream>
#include <iostream>
#include "neuron/api/NeuronAdapter.h"
void* load_func(void* handle, const char* func_name) {
/* Load the function specified by func_name, and exit if the loading is
* failed. */
void* func_ptr = dlsym(handle, func_name);
if (func_ptr == nullptr) {
std::cerr << "Find " << func_name << " function failed." << std::endl;
exit(2);
}
return func_ptr;
}
int main() {
void* handle;
// typedef to the build functions pointer signatures
typedef int (*Neuron_getVersion)(NeuronRuntimeVersion * version);
typedef int (*NeuronModel_create)(NeuronModel * *model);
typedef void (*NeuronModel_free)(NeuronModel * model);
typedef int (*NeuronModel_finish)(NeuronModel * model);
typedef int (*NeuronModel_addOperand)(NeuronModel * model, const NeuronOperandType* type);
typedef int (*NeuronModel_setOperandValue)(NeuronModel * model, int32_t index,
const void* buffer, size_t length);
typedef int (*NeuronModel_addOperation)(NeuronModel * model, NeuronOperationType type,
uint32_t inputCount, const uint32_t* inputs,
uint32_t outputCount, const uint32_t* outputs);
typedef int (*NeuronModel_identifyInputsAndOutputs)(
NeuronModel * model, uint32_t inputCount, const uint32_t* inputs, uint32_t outputCount,
const uint32_t* outputs);
typedef int (*NeuronCompilation_create)(NeuronModel * model, NeuronCompilation * *compilation);
typedef void (*NeuronCompilation_free)(NeuronCompilation * compilation);
typedef int (*NeuronCompilation_finish)(NeuronCompilation * compilation);
typedef int (*NeuronExecution_create)(NeuronCompilation * compilation,
NeuronExecution * *execution);
typedef void (*NeuronExecution_free)(NeuronExecution * execution);
typedef int (*NeuronExecution_setInput)(NeuronExecution * execution, int32_t index,
const NeuronOperandType* type, const void* buffer,
size_t length);
typedef int (*NeuronExecution_setOutput)(NeuronExecution * execution, int32_t index,
const NeuronOperandType* type, void* buffer,
size_t length);
typedef int (*NeuronExecution_compute)(NeuronExecution * execution);
// Open the shared library.
// In Android, /system/system_ext/lib64/libneuronusdk_adapter.mtk.so is provided for apps.
// Dlopen libneuronusdk_adapter.mtk.so if you are developing apps or components in /system.
// Otherwise, dlopen libneuron_adapter.so when developing in Linux or /vendor in Android.
handle = dlopen("libneuron_adapter.so", RTLD_LAZY);
if (handle == nullptr) {
std::cerr << dlerror() << std::endl;
std::cerr << "Failed to open libneuron_adapter.so." << std::endl;
exit(2);
}
#define LOAD_FUNCTIONS(FUNC_NAME, VARIABLE_NAME) \
FUNC_NAME VARIABLE_NAME = reinterpret_cast<FUNC_NAME>(load_func(handle, #FUNC_NAME));
LOAD_FUNCTIONS(Neuron_getVersion, neuron_getVersion)
LOAD_FUNCTIONS(NeuronModel_create, neuron_model_create)
LOAD_FUNCTIONS(NeuronModel_free, neuron_model_free)
LOAD_FUNCTIONS(NeuronModel_finish, neuron_model_finish)
LOAD_FUNCTIONS(NeuronModel_addOperand, neuron_model_addOperand)
LOAD_FUNCTIONS(NeuronModel_setOperandValue, neuron_model_setOperandValue)
LOAD_FUNCTIONS(NeuronModel_addOperation, neuron_model_addOperation)
LOAD_FUNCTIONS(NeuronModel_identifyInputsAndOutputs, neuron_model_identifyInputsAndOutputs)
LOAD_FUNCTIONS(NeuronCompilation_create, neuron_compilation_create)
LOAD_FUNCTIONS(NeuronCompilation_free, neuron_compilation_free)
LOAD_FUNCTIONS(NeuronCompilation_finish, neuron_compilation_finish)
LOAD_FUNCTIONS(NeuronExecution_create, neuron_execution_create)
LOAD_FUNCTIONS(NeuronExecution_free, neuron_execution_free)
LOAD_FUNCTIONS(NeuronExecution_setInput, neuron_execution_setInput)
LOAD_FUNCTIONS(NeuronExecution_setOutput, neuron_execution_setOutput)
LOAD_FUNCTIONS(NeuronExecution_compute, neuron_execution_compute)
#undef LOAD_FUNCTIONS
NeuronRuntimeVersion version;
(*neuron_getVersion)(&version);
std::cout << "Neuron version " << static_cast<uint32_t>(version.major) << "."
<< static_cast<uint32_t>(version.minor) << "." << static_cast<uint32_t>(version.patch)
<< std::endl;
NeuronModel* model = NULL;
int neuron_errCode = (*neuron_model_create)(&model);
if (NEURON_NO_ERROR != neuron_errCode) {
std::cerr << "Fail to create model" << std::endl;
exit(1);
}
NeuronOperandType tensor3x4Type;
tensor3x4Type.type = NEURON_TENSOR_QUANT8_ASYMM;
tensor3x4Type.scale = 0.5f; // For quantized tensors
tensor3x4Type.zeroPoint = 0; // For quantized tensors
tensor3x4Type.dimensionCount = 2;
uint32_t dims[2] = {3, 4};
tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers
NeuronOperandType activationType;
activationType.type = NEURON_INT32;
activationType.scale = 0.f;
activationType.zeroPoint = 0;
activationType.dimensionCount = 0;
activationType.dimensions = NULL;
// Now we add the operands for required by current OP
(*neuron_model_addOperand)(model, &tensor3x4Type); // operand 0
(*neuron_model_addOperand)(model, &tensor3x4Type); // operand 1
(*neuron_model_addOperand)(model, &activationType); // operand 2
(*neuron_model_addOperand)(model, &tensor3x4Type); // operand 3
const int sizeOfTensor =
3 * 4; // The formula for size calculation is dim0 * dim1 * elementSize
uint8_t mem3x4[sizeOfTensor] = {0x01, 0x01, 0x01, 0x01, 0x01, 0x01,
0x01, 0x01, 0x01, 0x01, 0x01, 0x01};
(*neuron_model_setOperandValue)(model, 1, mem3x4, sizeOfTensor);
// values of the activation operands
int32_t noneValue = NEURON_FUSED_NONE;
(*neuron_model_setOperandValue)(model, 2, &noneValue, sizeof(noneValue));
// We have two operations in our example
// The first consumes operands 1, 0, 2, and produces operand 3
uint32_t addInputIndexes[3] = {1, 0, 2};
uint32_t addOutputIndexes[1] = {3};
(*neuron_model_addOperation)(model, NEURON_ADD, 3, addInputIndexes, 1, addOutputIndexes);
(*neuron_model_addOperand)(model, &tensor3x4Type); // operand 4
(*neuron_model_addOperand)(model, &activationType); // operand 5
(*neuron_model_addOperand)(model, &tensor3x4Type); // operand 6
(*neuron_model_setOperandValue)(model, 4, mem3x4, sizeOfTensor);
(*neuron_model_setOperandValue)(model, 5, &noneValue, sizeof(noneValue));
// The second consumes operands 3, 4, 5, and produces operand 6
uint32_t multInputIndexes[3] = {3, 4, 5};
uint32_t multOutputIndexes[1] = {6};
(*neuron_model_addOperation)(model, NEURON_MUL, 3, multInputIndexes, 1, multOutputIndexes);
// Our model has one input (0) and one output (6)
uint32_t modelInputIndexes[1] = {0};
uint32_t modelOutputIndexes[1] = {6};
(*neuron_model_identifyInputsAndOutputs)(model, 1, modelInputIndexes, 1, modelOutputIndexes);
(*neuron_model_finish)(model);
// Compile the model
NeuronCompilation* compilation;
int ret = (*neuron_compilation_create)(model, &compilation);
if (ret != NEURON_NO_ERROR) {
std::cerr << "Failed to create compilation" << std::endl;
exit(1);
}
if ((*neuron_compilation_finish)(compilation)) {
std::cout << "Compilation failed" << std::endl;
exit(1);
}
// Run the compiled model against a set of inputs
NeuronExecution* run1 = NULL;
(*neuron_execution_create)(compilation, &run1);
// Set the single input to our sample model. Since it is small, we won't use a
// memory buffer
uint8_t myInput[3][4] = {
{0x01, 0x01, 0x01, 0x01}, {0x01, 0x01, 0x01, 0x01}, {0x01, 0x01, 0x01, 0x01}};
(*neuron_execution_setInput)(run1, 0, NULL, myInput, sizeof(myInput));
// Set the output
uint8_t myOutput[3][4];
(*neuron_execution_setOutput)(run1, 0, NULL, myOutput, sizeof(myOutput));
(*neuron_execution_compute)(run1);
(*neuron_execution_free)(run1);
(*neuron_compilation_free)(compilation);
(*neuron_model_free)(model);
// dump input and output
std::cout << "Input: ";
std::string inputString;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
inputString += std::to_string((uint32_t)myInput[i][j]) + " ";
}
}
std::cout << inputString << std::endl;
std::cout << "Output: ";
std::string outputString;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
outputString += std::to_string((uint32_t)myOutput[i][j]) + " ";
}
}
std::cout << outputString << std::endl;
return 0;
}
4.2.1.3 Error Codes
A list of error codes returned by Neuron Adapter API functions and their meanings.
|
Error code |
Description |
Possible Causes |
|
NEURON_NO_ERROR |
The API function completed successfully. |
|
|
NEURON_OUT_OF_MEMORY |
Memory is insufficient for the API function. |
System has insufficient memory |
|
NEURON_INCOMPLETE |
Not in use. |
|
|
NEURON_UNEXPECTED_NULL |
A required pointer is null. |
Ensure the required arguments are not null. |
|
NEURON_OP_FAILED |
Cannot prepare the model before compilation. |
Check the error log for invalid operation data. |
|
NEURON_UNMAPPABLE |
Cannot finish compilation. |
Refer to 4.2.1.4. Error Messages: Model Compilation Errors. |
|
NEURON_BAD_STATE |
Called the API function during the wrong workflow. |
Check the error log for the incorrect API workflow. |
|
NEURON_BAD_VERSION |
Not in use. |
4.2.1.4 Error Messages: Model Compilation Errors
If the returned value of NeuronCompilation_finish is NEURON_UNMAPPABLE, then the given model is not supported by the underlying hardware. Please check the log to see why this model is not supported.
The following is an example of a compilation failure.
I neuron : INFO: NIR[0]: ResizeLayer<0>
I neuron : ├ MDLA: Can't find a valid tile.
I neuron : ├ MDLA: [AlignCorner=True] (SF * (output-1)) must be equal or larger than (input-1).
I neuron : ├ MDLA: [AlignCorner=false] (SF * output) must be equal or larger than input.
I neuron : ├ VPU: nir.IsAlignCorners() == false AlignCorners is not support in resizeNearest
4.2.1.5 Compilation Cache
Neuron Adapter API provides two sets of API functions for configuring the compilation cache.
4.2.1.5.1 Android NNAPI Cache
This set of API functions follows Android NNAPI. For details on how to use these API functions with NeuronCompilation_finish, see the Android NNAPI documentation <https://source.android.com/docs/core/interaction/neural-networks/compilation-caching>.
int NeuronCompilation_setCaching(NeuronCompilation* compilation, const char* cacheDir,
const uint8_t* token);
4.2.1.5.2 Raw Data Buffer Cache
This set of API functions provides access to the compilation cache as a raw data buffer. This allows the user to copy the raw data buffer back to their application framework, in order to integrate the buffer with a custom cache management system.
4.2.1.5.2.1 Example: Getting and Storing the Cache
int err = NeuronCompilation_finish(compilation);
// Query the cache size after NeuronCompilation_finish.
err = NeuronCompilation_getCompiledNetworkSize(compilation, &compilationSize);
// Allocate the user buffer with the compilation size.
uint8_t *buffer = new uint8_t[compilationSize];
// Copy the cache into the user-allocated buffer.
NeuronCompilation_storeCompiledNetwork(compilation, buffer, compilationSize);
// User can now integrate this buffer with their own cache management systems.
// ...
// Remember to deallocate the buffer after the cache is saved to some storage.
delete[] buffer;
4.2.1.5.2.2 Example: Restoring the Cache
// Assume the cache is located at *cacheBuffer and the size of this buffer is cacheSize
NeuronModel *restoredModel = nullptr;
NeuronCompilation *restoredCompilation = nullptr;
int err = NeuronModel_restoreFromCompiledNetwork(&restoredModel, &restoredCompilation, cacheBuffer, cacheSize);
// The buffer can be deallocated after the cache is successfully restored
delete[] cacheBuffer;
// The restored compilation context can be used in execution using the same set of execution APIs.
NeuronExecution *run = NULL;
NeuronExecution_create(restoredCompilation, &run);
// .... omitted
Note that when calling NeuronModel_restoreFromCompiledNetwork, the system checks whether the cache version matches the Neuron Adapter API library version. If the versions do not match, then NeuronModel_restoreFromCompiledNetwork will return error NEURON_BAD_DATA to indicate the cache buffer is not usable. In this scenario, the user must reconstruct the model and compilation context.
int err = NeuronModel_restoreFromCompiledNetwork(&restoredModel, &restoredCompilation, cacheBuffer, cacheSize);
if (err == NEURON_BAD_DATA) {
// Either the version is not matched or the data is corrupted.
// User must reconstruct the compilation context using NeuronCompilation_finish.
}
4.2.1.6 Compiling a DLA File Offline Using Neuron Adapter API
Users can write code using the host version of Neuron Adapter API, located at host/lib/libneuron_adapter.so in the NeuronPilot SDK.
Users can use the host version of Neuron Adapter API to compile a model to a DLA (Deep Learning Archive) file on the local computer.
The DLA file can be deployed to devices for inference using Neuron Runtime API.
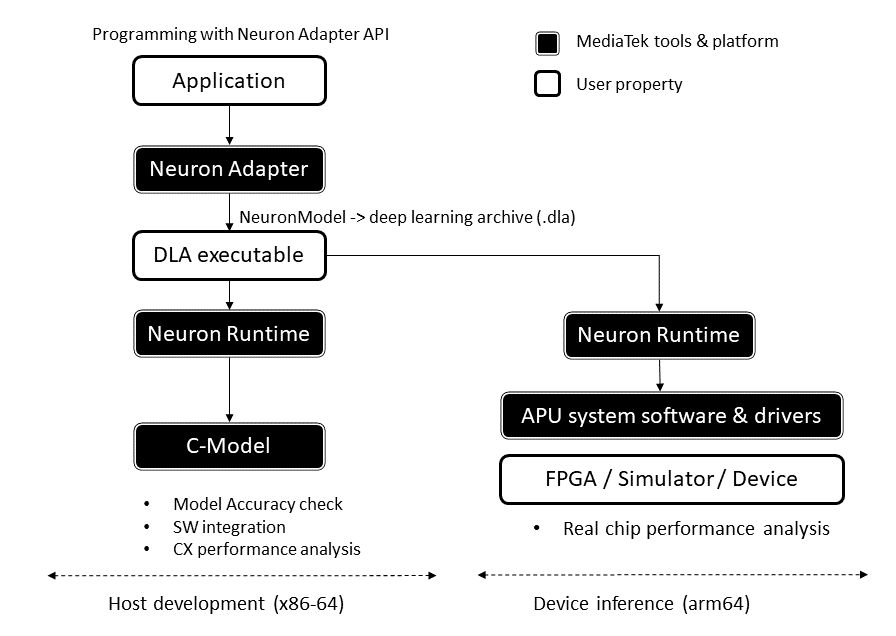
4.2.1.6.1 Step By Step Tutorial
- Save the path to the Neuron SDK package as variable $PATCH_TO_SDK.
PC:/home/mtk/my_workspace $ ls neuron_sdk/ host mt6771 mt6779 mt6785 mt6853 mt6873 mt6877 mt6885 mt6889 mt6891 mt6893 mt6983 mt8195 PC:/home/mtk/my_workspace $ export PATH_TO_SDK=/home/mtk/my_workspace/neuron_sdk/ - Save the example code from 4.2.1.2. Example: Using Neuron Adapter API to a file named sample.cpp. Then compile sample.cpp with the include path from the Neuron SDK package.
Now adapter_api_sample is ready to be executed with the Neuron SDK lib.PC:/home/mtk/my_workspace $ clang++ -I $PATH_TO_SDK/host/include/ sample.cpp -o adapter_api_sample -ldlPC:/home/mtk $ ls my_workspace neuron_sdk adapter_api_sample - Set environment variable LD_LIBRARY_PATH to the Neuron Adapter API host library folder.
PC:/home/mtk/my_workspace $ export LD_LIBRARY_PATH=$PATH_TO_SDK/host/lib:$LD_LIBRARY_PATH - Set environment variable MTKNN_ADAPTER_DLA_PLATFORM to the plaform target of the generated DLA.
PC:/home/mtk/my_workspace $ export MTKNN_ADAPTER_DLA_PLATFORM=mt6983 - Run the adapter_api_sample executable. Note that the inference output of NeuronExecution_compute is not a valid result, because inference is not performed on a device with an APU.
PC:/home/mtk/my_workspace $ ./adapter_api_sample Neuron version 5.0.0 Input: 1 1 1 1 1 1 1 1 1 1 1 1 Output: 88 184 235 130 88 127 0 0 128 54 0 0 - After the NeuronCompilation_finish function in adapter_api_sample has finished running with the return code NEURON_NO_ERROR, a DLA file is generated.
PC:/home/mtk/my_workspace $ ls neuron_sdk adapter_api_sample mt6893_1623287462210871.dla - The DLA file can be used with Neuron Runtime API. For details, see 4.1.2.2. Neuron Runtime API.
4.2.1.6.2 Platform Configuration
As described in the previous tutorial, the user must set a target platform using MTKNN_ADAPTER_DLA_PLATFORM before running the x86 executable.
4.2.1.6.2.1 Valid Platform Names
For a list of valid platform names, refer to the platform folder names in the Neuron SDK release package. This means that for each valid platform, there is a corresponding in the Neuron SDK directory.
The following is an example of supported platforms in an SDK release package. In this release, the valid platforms are mt6853, mt6873, mt6877, mt6885, and mt8195. Note that mt6889 and mt6891 are symlinks to mt6885, so use mt6885 for these two platforms.
PC:/home/mtk/my_workspace $ ls -l neuron_sdk/
drwxr-xr-x 5 user001 user001 4096 Jun 1 01:07 host
drwxr-xr-x 5 user001 user001 4096 Jun 1 01:08 mt6853
drwxr-xr-x 5 user001 user001 4096 Jun 1 01:08 mt6873
drwxr-xr-x 5 user001 user001 4096 Jun 1 01:08 mt6877
drwxr-xr-x 5 user001 user001 4096 Jun 1 01:09 mt6885
lrwxrwxrwx 1 user001 user001 6 Jun 1 01:09 mt6889 -> mt6885
lrwxrwxrwx 1 user001 user001 6 Jun 1 01:09 mt6891 -> mt6885
drwxr-xr-x 5 user001 user001 4096 Jul 29 03:23 mt6983
drwxr-xr-x 5 user001 user001 4096 Jun 1 01:09 mt8195
-rw------- 1 user001 user001 4570 Jun 1 01:09 readme.txt
4.2.1.6.2.2 Error: No Platform Name
If MTKNN_ADAPTER_DLA_PLATFORM is not set, then NeuronCompilation_create will give the following error.
PC:/home/mtk/my_workspace $ unset MTKNN_ADAPTER_DLA_PLATFORM
PC:/home/mtk/my_workspace $ ./adapter_api_sample
Neuron version 5.0.0
ERROR: Need to set environment variable MTKNN_ADAPTER_DLA_PLATFORM with a
platform string before calling NeuronCompilation_create
Failed to create compilation
PC:/home/mtk/my_workspace $
4.2.1.6.2.3 Error: Invalid Platform Name
If MTKNN_ADAPTER_DLA_PLATFORM is not a valid MediaTek platform, then NeuronCompilation_create will give the following error.
PC:/home/mtk/my_workspace $ export MTKNN_ADAPTER_DLA_PLATFORM=mt1234
PC:/home/mtk/my_workspace $ ./adapter_api_sample
Neuron version 5.0.0
ERROR: Not a valid platform: mt1234
Failed to create compilation
4.2.1.6.3 Adding a DLA File Prefix
The default DLA file name is <platform>_<timestamp>.dla. Users can add a custom prefix to the output DLA file name by setting MTKNN_ADAPTER_DLA_PREFIX.
PC:/home/mtk/my_workspace $ export MTKNN_ADAPTER_DLA_PREFIX=AI_Model
PC:/home/mtk/my_workspace $ ./adapter_api_sample
Neuron version 5.0.0
Input: 1 1 1 1 1 1 1 1 1 1 1 1
Output: 88 184 235 130 88 127 0 0 128 54 0 0
PC:/home/mtk/my_workspace $ ls
neuron_sdk adapter_api_sample mt6893_1623287462210871.dla AI_Model_mt6893_1623401911367620.dla
4.2.1.6.4 Setting the DLA Output Path
The default DLA file output path is the same directory as the x86 executable. Users can provide a custom output path by setting MTKNN_ADAPTER_DLA_DIR. Note that the output directory must already exist.
PC:/home/mtk/my_workspace $ export MTKNN_ADAPTER_DLA_DIR=generated_dla
PC:/home/mtk/my_workspace $ ./adapter_api_sample
Neuron version 5.0.0
ERROR: User provided MTKNN_ADAPTER_DLA_DIR is not a valid directory
ERROR: Error when generating DLA file: path error
Input: 1 1 1 1 1 1 1 1 1 1 1 1
Output: 200 33 174 27 236 127 0 0 64 114 216 27
PC:/home/mtk/my_workspace $ mkdir generated_dla
PC:/home/mtk/my_workspace $ ./adapter_api_sample
Neuron version 5.0.0
Input: 1 1 1 1 1 1 1 1 1 1 1 1
Output: 200 225 192 74 151 127 0 0 64 50 235 74
PC:/home/mtk/my_workspace $ ls generated_dla/
AI_Model_mt6893_1623402869522451.dla
4.2.2 OpenVX SDK
Khronos OpenVX, designed by Khronos Group, is an open standard for cross platform acceleration of computer vision applications. The NeuroPilot OpenVX SDK is based on the Khronos OpenVX sample framework.
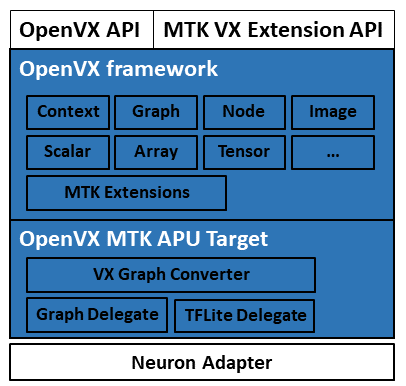
The NeuroPilot OpenVX SDK provides OpenVX standard APIs and MediaTek VX-extension APIs to developers of computer vision applications. The OpenVX framework in the NeuroPilot OpenVX SDK is modified to work with MediaTek AI Processing Unit (APU) targets. The OpenVX MediaTek APU Target module transforms an OpenVX graph into a MediaTek APU internal graph representation. An additional integrated TensorFlow Lite (TFLite) delegate module provides a method to incorporate neural network models in TensorFlow Lite format into OpenVX computation graphs. The OpenVX MediaTek APU Target module uses the interfaces provided by the NeuroPilot Neuron Adapter API library to deploy OpenVX computation graphs on MediaTek platforms.
- For a description of OpenVX APIs, see the OpenVX Specification.
- For a list of OpenVX API vision functions that are supported by the NeuroPilot OpenVX SDK, see 4.2.2.3. Supported Vision Functions.
- For a list of MediaTek VX extension APIs, see 5.5. OpenVX API Reference.
|
Note: |
|
Some embedded SoC platforms do not support OpenVX SDK. To check compatibility, please contact MediaTek. |
4.2.2.1 OpenVX Development Workflow
The NeuroPilot OpenVX SDK offers an offline development workflow, where applications developed with the NeuroPilot OpenVX SDK are compiled and executed on a computer called the host machine. An application executed on the host machine outputs a DLA (Deep Learning Archive) file. The DLA file can be deployed on MediaTek platforms for real device inference using the Neuron Runtime API.
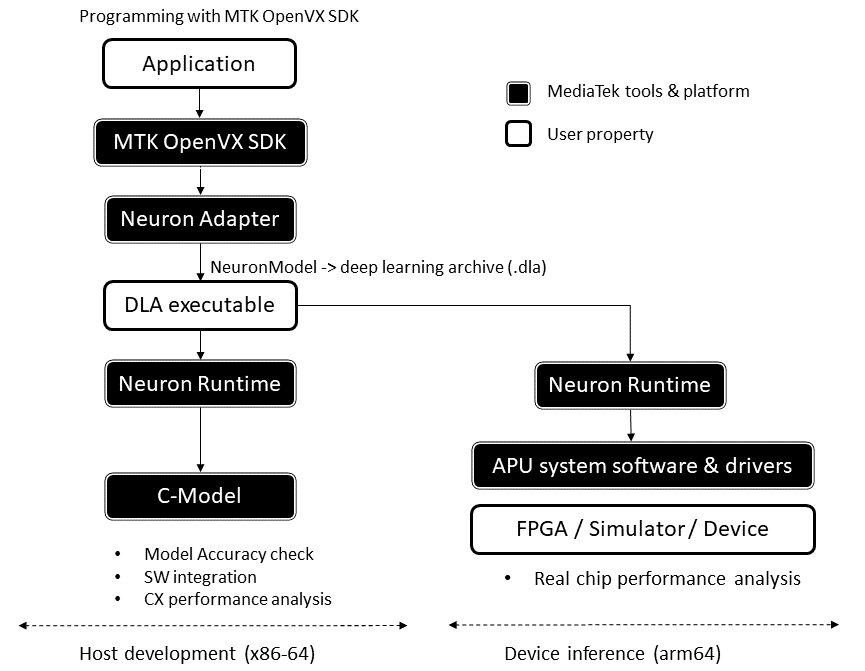
|
Note: |
|
The NeuroPilot OpenVX SDK workflow is similar to the Neuron Adapter API workflow described at 4.2.1.6. Compiling a DLA File Offline Using Neuron Adapter API. However, the application in this workflow is specifically developed using the NeuroPilot OpenVX SDK. |
The following sections provide guides on how to develop an OpenVX application, build the application with the NeuroPilot OpenVX SDK, and generate a DLA executable by running the application on a host machine.
4.2.2.1.1 Developing an OpenVX Application
This section describes a simple workflow for developing an OpenVX application from context and graph creation to graph execution. For a detailed description of OpenVX APIs, see the OpenVX Specification.
This example uses a simple binary threshold application. Complete source code can be found at 4.2.2.2.1. Single Threshold OP Example.
- Include VX headers. vx.h is required for OpenVX-graph-based applications. Users can also include vxu.h to use function-call-based utility functions.
#include <VX/vx.h>
- Create the context and graph.
vx_context context = vxCreateContext();
vx_graph graph = vxCreateGraph(context);
- Create input and output components. These include images, arrays, and other data objects that are connected to nodes (operators) in the graph.
vx_image images[] = {
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
};
- Add nodes (operators). Follow each node’s API description to provide parameters, input, and output images.
vxThresholdNode(graph, images[0], thresh, images[1]);
- Verify and execute the graph.
status = vxVerifyGraph(graph);
status = vxProcessGraph(graph);
- After the graph has finished executing, release the context, graph, images, and parameters.
vxReleaseThreshold(&thresh);
vxReleaseNode(&nodes[i]);
vxReleaseGraph(&graph);
vxReleaseImage(&images[i]);
vxReleaseContext(&context);
4.2.2.1.2 Building the OpenVX Application
This section provides an example showing how to build an OpenVX application from source code to an executable file.
- Copy the sample code listed at 4.2.2.2.1. Single Threshold OP Example, and then save it in a file named vx_graph_threshold.c.
[PC:/home/mtk/vx]$ls
vx_graph_threshold.c
- Copy the Neuron SDK install package to the same directory as vx_graph_threshold.c. Then unpack the Neuron SDK install package to a folder named neuron_sdk.
[PC:/home/mtk/vx]$ls
neuron-5.0.0-20210802-release.tar.gz vx_graph_threshold.c
[PC:/home/mtk/vx]$mkdir neuron_sdk
[PC:/home/mtk/vx]$tar zxvf neuron-5.0.0-20210802-release.tar.gz -C neuron_sdk --strip-components=1
[PC:/home/mtk/vx]$ls neuron_sdk/
host mt6771 mt6779 mt6785 mt6853 mt6873 mt6877 mt6885
mt6889 mt6891 mt6893 mt8195 readme.txt
- Compile the vx_graph_threshold.c together with the Neuron SDK host package.
[PC:/home/mtk/vx]$$clang \
-I ./neuron_sdk/host/include/ \
-L ./neuron_sdk/host/lib/ \
-o graph_threshold \
vx_graph_threshold.c \
-lopenvx -lvxmtk_nodes
[PC:/home/mtk/vx]$ls
graph_threshold neuron_sdk vx_graph_threshold.c
4.2.2.1.3 Generating the DLA File
- Set environment variable MTKNN_ADAPTER_DLA_PLATFORM to the DLA target platform.
- Add the full path to the Neuron SDK host/lib folder to environment variable LD_LIBRARY_PATH.
- Run the application, and then confirm the DLA file was generated.
[PC:/home/mtk/vx]$export MTKNN_ADAPTER_DLA_PLATFORM=mt6983
[PC:/home/mtk/vx]$export LD_LIBRARY_PATH=./neuron_sdk/host/lib/:$LD_LIBRARY_PATH
[PC:/home/mtk/vx]$./graph_threshold
...
Test Success
[PC:/home/mtk/vx]$ls mt*.dla
mt6983_1626867926540465.dla
|
Note: |
|
For details on how to customize the DLA file, see 4.2.1.6. Compiling a DLA File Offline Using Neuron Adapter API. |
4.2.2.2 Example Applications
4.2.2.2.1 Single Threshold OP Example
/**
* An example of how to construct an OpenVX graph with 1 CV OP.
*
* ┌─────────────┐ ┌─────────────────────┐ ┌─────────────┐
* │ image[0] │ │ vxThresholdNode │ │ image[1] │
* │ (1080x1920) │ │ (threshold:32) │ │ (1080x1920) │
* │ │ ──> │ (true: 53, false:0) │ ──> │ │
* └─────────────┘ └─────────────────────┘ └─────────────┘
*
* Here we use the vxThresholdNode as the CV OP.
* Refer to OpenVX specification on the detailed description about this node.
* https://www.khronos.org/registry/OpenVX/specs/1.3/html/OpenVX_Specification_1_3.html#_vxthresholdnode
*/
#include <VX/vx.h>
#include <stdio.h>
#ifndef dimof
#define dimof(x) (sizeof(x) / sizeof(x[0]))
#endif
int main(int argc, char* argv[]) {
vx_status status = VX_SUCCESS;
vx_context context = vxCreateContext();
if (vxGetStatus((vx_reference)context) == VX_SUCCESS) {
vx_uint32 i = 0, width = 1920, height = 1080;
vx_image images[] = {
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
};
vx_graph graph = vxCreateGraph(context);
if (vxGetStatus((vx_reference)graph) == VX_SUCCESS) {
// Setup vx_threshold parameters
vx_threshold thresh = vxCreateThresholdForImage(context, VX_THRESHOLD_TYPE_BINARY,
VX_DF_IMAGE_U8, VX_DF_IMAGE_U8);
// threshold
vx_pixel_value_t pa;
pa.S32 = 32;
vxCopyThresholdValue(thresh, &pa, VX_WRITE_ONLY, VX_MEMORY_TYPE_HOST);
// true value
vx_pixel_value_t ptrue, pfalse;
ptrue.S32 = 53;
pfalse.S32 = 0;
vxCopyThresholdOutput(thresh, &ptrue, &pfalse, VX_WRITE_ONLY, VX_MEMORY_TYPE_HOST);
vx_node nodes[] = {
vxThresholdNode(graph, images[0], thresh, images[1]),
};
status = vxVerifyGraph(graph);
if (status == VX_SUCCESS) {
status = vxProcessGraph(graph);
}
vxReleaseThreshold(&thresh);
for (i = 0; i < dimof(nodes); i++) {
vxReleaseNode(&nodes[i]);
}
vxReleaseGraph(&graph);
}
for (i = 0; i < dimof(images); i++) {
vxReleaseImage(&images[i]);
}
exit:
vxReleaseContext(&context);
}
if (status == VX_SUCCESS) {
printf("Test Success\n");
} else {
printf("Test Fail\n");
}
return status;
}
4.2.2.2.2 Background Subtraction 5 OPs Example
/**
* An example of how to construct a OpenVX graph with 5 CV OPs.
* ┌────────────┐
* │ image[1] │
* │ (1920x2560 │
* │ (bg) │
* └───┬────────┘
* │
* ┌──────────────────────┐ ┌─────────────────┐ ┌───▼────────────┐
* │ image[0] │ │ │ │ │
* │ (1920x2560 │ │ vxMedian3x3Node │ │ vxAbsDiffNode ├────┐
* │ (gray) │ ──► │ │ ──► │ │ │
* └──────────────────────┘ └─────────────────┘ └────────────────┘ │
* │
* ┌──────────────────────────────────────────────────────────────┘
* │
* ┌───────────▼──────────┐ ┌─────────────────┐ ┌────────────────┐
* │ vxThresholdNode │ │ │ │ │
* │ (threshold:127) │ │ vxDilate3x3Node │ │ vxErode3x3Node │
* │ (true: 255, false:0) │ ──► │ │ ──► │ │
* └──────────────────────┘ └─────────────────┘ └───────────┬────┘
* │
* │
* ┌───────▼────┐
* │ image[6] │
* │ (1920x2560 │
* │ (output) │
* └────────────┘
*
* Here we use these 5 CV OPs in the graph.
* vxMedian3x3Node, vxAbsDiffNode, vxThresholdNode, vxDilate3x3Node, vxErode3x3Node
* https://www.khronos.org/registry/OpenVX/specs/1.3/html/OpenVX_Specification_1_3.html#_vxmedian3x3node
* https://www.khronos.org/registry/OpenVX/specs/1.3/html/OpenVX_Specification_1_3.html#_vxabsdiffnode
* https://www.khronos.org/registry/OpenVX/specs/1.3/html/OpenVX_Specification_1_3.html#vxThresholdNode
* https://www.khronos.org/registry/OpenVX/specs/1.3/html/OpenVX_Specification_1_3.html#_vxdilate3x3node
* https://www.khronos.org/registry/OpenVX/specs/1.3/html/OpenVX_Specification_1_3.html#vxErode3x3Node
*/
#include <VX/vx.h>
#include <stdio.h>
#ifndef dimof
#define dimof(x) (sizeof(x) / sizeof(x[0]))
#endif
int main(int argc, char* argv[]) {
vx_status status = VX_SUCCESS;
vx_context context = vxCreateContext();
if (vxGetStatus((vx_reference)context) == VX_SUCCESS) {
vx_uint32 i = 0, width = 2560, height = 1920;
vx_image images[] = {
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
};
vx_graph graph = vxCreateGraph(context);
if (vxGetStatus((vx_reference)graph) == VX_SUCCESS) {
vx_threshold thresh = vxCreateThresholdForImage(context, VX_THRESHOLD_TYPE_BINARY,
VX_DF_IMAGE_U8, VX_DF_IMAGE_U8);
vx_pixel_value_t pa;
pa.S32 = 127;
vxCopyThresholdValue(thresh, &pa, VX_WRITE_ONLY, VX_MEMORY_TYPE_HOST);
vx_pixel_value_t ptrue, pfalse;
ptrue.S32 = 255;
pfalse.S32 = 0;
vxCopyThresholdOutput(thresh, &ptrue, &pfalse, VX_WRITE_ONLY, VX_MEMORY_TYPE_HOST);
vx_node nodes[] = {
vxMedian3x3Node(graph, images[0], images[2]),
vxAbsDiffNode(graph, images[2], images[1], images[3]),
vxThresholdNode(graph, images[3], thresh, images[4]),
vxDilate3x3Node(graph, images[4], images[5]),
vxErode3x3Node(graph, images[5], images[6]),
};
status = vxVerifyGraph(graph);
if (status == VX_SUCCESS) {
status = vxProcessGraph(graph);
}
vxReleaseThreshold(&thresh);
for (i = 0; i < dimof(nodes); i++) {
vxReleaseNode(&nodes[i]);
}
vxReleaseGraph(&graph);
}
for (i = 0; i < dimof(images); i++) {
vxReleaseImage(&images[i]);
}
exit:
vxReleaseContext(&context);
}
if (status == VX_SUCCESS) {
printf("Test Success\n");
} else {
printf("Test Fail\n");
}
return status;
}
4.2.2.2.3 CV + NN with Conv2D Example
The NeuroPilot OpenVX SDK provides extensions to the OpenVX API that let users integrate a pre-trained neural network (NN) model in TensorFlow Lite format with OpenVX computer vision (CV) nodes.
The following example shows how to utilize the MediaTek extended OpenVX APIs to include CV nodes and NN nodes in a single execution graph.
A user has a pre-trained TensorFlow Lite NN model file with the following content.
The user would like to add some CV pre-processing before the input to the TensorFlow Lite NN model.
The NeuroPilot OpenVX SDK provides MediaTek extension nodes to connect the CV_output of the pre-processing to the input of TensorFlow Lite NN model.
- mvxImageToTensorNode
vx_node mvxImageToTensorNode(vx_graph graph,
vx_image input,
vx_tensor output);
This node transforms the vx_image of the CV_output into a vx_tensor for input into the TensorFlow Lite NN model.
- mvxRequantizeNode
vx_node mvxRequantizeNode(vx_graph graph,
vx_tensor input,
vx_float32 scale,
vx_int32 zeroPoint,
vx_tensor output);
This node applies the model’s quantization parameters on the input tensor, and then stores the quantized result on the output tensor. Using a TFLITE file viewer such as Netron, record the model’s scale and zeroPoint, and then provide these values to the node.
- mvxTFLiteNode
vx_node mvxTFLiteNode(vx_graph graph,
vx_tensor input,
vx_float32 in_scale,
vx_int32 in_zeroPoint,
vx_array tflite,
vx_float32 out_scale,
vx_int32 out_zeroPoint,
vx_tensor output);
This nodes wraps the TensorFlow Lite NN model information. Using a TFLITE file viewer such as Netron, record the in_scale and in_zeroPoint of the input tensor, and the out_scale and out_zeroPoint of the output tensor. Then provide these values to the node. The vx_array tflite parameter is an array of characters for storing the binary content of the TFLITE file. For information on how to store the content of a TFLite file into vx_arrayRefer, see the The OpenVX Specification and the example code below.
The following code provides the CV + NN graph sample.
/*
* An example of how to construct a graph with OpenVX CV nodes and MediaTek NN nodes.
*
* ┌────────────────────────────────────────────────┐
* │ ▼
* │ ┌───────────┐ ┌─────────────────┐ ┌──────────────────────┐
* │ │ image[0] │ │ vxMedian3x3Node │ │ vxChannelCombineNode │
* │ │ (224x224) │ ──► │ │ ──► │ ├──┐
* │ └───────────┘ └─────────────────┘ └──────────────────────┘ │
* │ ▲ │
* │ │ │
* │ │ │
* │ ┌───────────┐ ┌─────────────────┐ │ │
* │ │ image[2] │ │ vxMedian3x3Node │ │ │
* │ │ (224x224) │ ──► │ ├────────┘ │
* │ └───────────┘ └─────────────────┘ │
* │ │
* └──────────────────────┐ │
* │ │
* ┌───────────┐ ┌─┴───────────────┐ │
* │ image[1] │ │ vxMedian3x3Node │ │
* │ (224x224) │ ──► │ │ │
* └───────────┘ └─────────────────┘ │
* │
* ┌─────────────────────────────────────────────────────────┘
* │
* ▼
* ┌──────────────────────┐ ┌───────────────────┐ ┌───────────────┐
* │ mvxImageToTensorNode │ │ mvxRequantizeNode │ │ mvxTFLiteNode │
* │ │ ──► │ │ ──► │ ├─┐
* └──────────────────────┘ └───────────────────┘ └───────────────┘ │
* │
* │
* ┌────────────────────────────────────────────────────────────────┘
* ▼
* ┌────────────────┐
* │ tensor[2] │
* │ (1x112x112x32) │
* └────────────────┘
*
* The CV nodes used in this graph:
* https://www.khronos.org/registry/OpenVX/specs/1.3/html/OpenVX_Specification_1_3.html#_vxmedian3x3node
* https://www.khronos.org/registry/OpenVX/specs/1.3/html/OpenVX_Specification_1_3.html#group_vision_function_channelcombine
*
* MTK NN nodes used in this graph:
* mvxImageToTensorNode, mvxRequantizeNode, mvxTFLiteNode. Refer to VX/vx_ext_mediatek.h for API
* description of these nodes.
*
* Use a TFLite viewer, e.g. netron, to check the content of the TFLite file,
* conv_224x224x3_112x112x32.tflite.
*/
#include <VX/vx.h>
#include <VX/vx_ext_mediatek.h>
#include <stdio.h>
#include "vx_tflite_utils.h"
#ifndef dimof
#define dimof(x) (sizeof(x) / sizeof(x[0]))
#endif
int main(int argc, char* argv[]) {
vx_status status = VX_SUCCESS;
vx_context context = vxCreateContext();
// Use a TFLite viewer, e.g. netron, to preview this file.
// This TFLite file contains a CONV2D NN operation.
const char tflite_file[128] = "conv_224x224x3_112x112x32.tflite";
char* tflite_buffer = NULL;
size_t tflite_size = 0;
if (vxGetStatus((vx_reference)context) == VX_SUCCESS) {
vx_uint32 i = 0, width = 224, height = 224;
size_t tensor_dims_in[4] = {1, 224, 224, 3};
size_t tensor_dims_out[4] = {1, 112, 112, 32};
// Read the content of tflite_file into an allocated buffer
status = create_and_read_tflite_buffer(tflite_file, &tflite_buffer, &tflite_size);
if (status != VX_SUCCESS) {
goto exit;
}
// Contrust a vx_array and copy the tflite buffer into it
vx_array tflite_array = vxCreateArray(context, VX_TYPE_CHAR, tflite_size);
vxAddArrayItems(tflite_array, tflite_size, tflite_buffer, sizeof(vx_char));
vx_image images[] = {vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_U8),
vxCreateImage(context, width, height, VX_DF_IMAGE_RGB)};
vx_tensor tensors[] = {
vxCreateTensor(context, 4, tensor_dims_in, VX_TYPE_UINT8, 0),
vxCreateTensor(context, 4, tensor_dims_in, VX_TYPE_UINT8, 0),
vxCreateTensor(context, 4, tensor_dims_out, VX_TYPE_UINT8, 0),
};
vx_graph graph = vxCreateGraph(context);
if (vxGetStatus((vx_reference)graph) == VX_SUCCESS) {
vx_node nodes[] = {
vxMedian3x3Node(graph, images[0], images[3]),
vxMedian3x3Node(graph, images[1], images[4]),
vxMedian3x3Node(graph, images[2], images[5]),
vxChannelCombineNode(graph, images[3], images[4], images[5], 0, images[6]),
mvxImageToTensorNode(graph, images[6], tensors[0]),
// Requantize the input tensor with the same parameter as the TFLite input.
mvxRequantizeNode(graph, tensors[0], 0.007874015718698502, 128, tensors[1]),
// Construct the TFLite node with input and output quantization parameters
// described in the TFLite file. You can use a TFLite viewer, e.g. netron, to
// check these parameters from the TFLite file.
mvxTFLiteNode(graph, tensors[1], 0.007874015718698502, 128, tflite_array,
0.023528477177023888, 0, tensors[2]),
};
status = vxVerifyGraph(graph);
if (status == VX_SUCCESS) {
status = vxProcessGraph(graph);
}
for (i = 0; i < dimof(nodes); i++) {
vxReleaseNode(&nodes[i]);
}
vxReleaseGraph(&graph);
}
for (i = 0; i < dimof(images); i++) {
vxReleaseImage(&images[i]);
}
for (i = 0; i < dimof(tensors); i++) {
vxReleaseTensor(&tensors[i]);
}
release_tflite_buffer(tflite_buffer);
exit:
vxReleaseContext(&context);
}
if (status == VX_SUCCESS) {
printf("Test Success\n");
} else {
printf("Test Fail\n");
}
return status;
}
Following is the content of the included file vx_tflite_utils.h.
- Note: create_and_read_tflite_buffer is a helper function that reads the TFLITE file into an allocated buffer for later use with vx_array.
- Note: release_tflite_buffer is a helper function to release the buffer created from create_and_read_tflite_buffer.
#ifndef _VX_TFLITE_UTILS_H_
#define _VX_TFLITE_UTILS_H_
#include <stdlib.h>
#include <VX/vx.h>
/**
* Read the content of a TFLite file into an allocated buffer
*
* @param file_path Path to the TFLite file
* @param buffer An allocated buffer with the TFLite content
* @param size Return the size of the TFLite file.
*
* @return VX_SUCCESS if successfull; VX_FAILURE if file operations on the given TFLite file
* was failed.
*/
vx_status create_and_read_tflite_buffer(const char* file_path, char** buffer, size_t* size) {
char* buffer_ = 0;
size_t size_;
FILE *f = fopen(file_path, "rb");
if (f) {
fseek(f, 0, SEEK_END);
size_ = ftell(f);
fseek(f, 0, SEEK_SET);
buffer_ = (char*)malloc(size_);
if (buffer_) {
fread(buffer_, 1, size_, f);
}
fclose(f);
*buffer = buffer_;
*size = size_;
return VX_SUCCESS;
} else {
printf("Failed to open tflite file\n");
return VX_FAILURE;
}
}
/**
* Release the buffer allocated from create_and_read_tflite_buffer
*
* @param buffer Buffer to be released
*
* @return VX_SUCCESS if successfull
*/
vx_status release_tflite_buffer(char* buffer) {
if (buffer) {
free(buffer);
return VX_SUCCESS;
} else {
return VX_FAILURE;
}
}
#endif
The constructed graph of this example code looks like this.
4.2.2.3 Supported Vision Functions
NeuroPilot OpenVX provides implementations of many Khronos OpenVX functions. The NeuroPilot OpenVX functions are listed in the following table, with information on whether the each function complies with the [REQ-#] requirements in the Khronos OpenVX Specification.
- Compliant - The function implements this requirement.
- Non-Compliant
- REQ-#: Modifications - The function implements this requirement with modifications.
- REQ-# - The function does not implement this requirement.
|
CV function |
Compliant |
Non-Compliant |
|
AbsDiff |
REQ-0001, REQ-0002, REQ-0003, |
|
|
Add |
REQ-0010, REQ-0011, REQ-0012, |
REQ-0013: Input 1 and input 2 must have the same data type |
|
And |
REQ-0045, REQ-0046, REQ-0050 |
REQ-0047: Does not support U1 format |
|
BilateralFilter |
REQ-0034, REQ-0035, REQ-0036, |
REQ-0038: Does not support src/dst with 3 dimensions [radiometric, width, height] |
|
Box3x3 |
REQ-0068, REQ-0069, REQ-0070, |
|
|
ChannelCombine |
REQ-0081, REQ-0082, REQ-0083, |
REQ-0086: Only supports RGB and RGBX |
|
ChannelExtract |
REQ-0088, REQ-0090, REQ-0091, |
REQ-0089: Only supports RGB and RGBX |
|
ColorConvert |
REQ-0094, REQ-0095, REQ-0096, |
REQ-0093: Supports the following conversions: |
|
ConvertDepth |
REQ-0124, REQ-0125, REQ-0126, |
REQ-0123: Does not support U1 format |
|
Convolve |
REQ-0139, REQ-0140, REQ-0141, |
REQ-0142: Only supports scales which are the power of 2 |
|
Dilate3x3 |
REQ-0156, REQ-0157, REQ-0160 |
REQ-0158: Does not support U1 format |
|
EqualizeHist |
REQ-0161, REQ-0162, REQ-0163, |
REQ-0166 |
|
Erode3x3 |
REQ-0167, REQ-0168, REQ-0171 |
REQ-0169: Does not support U1 format |
|
FastCorners |
REQ-0173, REQ-0174, REQ-0176, |
REQ-0175: Supports uchar |
|
Gaussian3x3 |
REQ-0181, REQ-0182, REQ-0183, |
|
|
HarrisCorners |
REQ-0217, REQ-0220, REQ-0221, |
REQ-0218: Only supports gradient 3x3 |
|
HalfScaleGaussian |
REQ-0400, REQ-0402, REQ-0403, |
REQ-0401: Does not support AREA |
|
Histogram |
REQ-0230, REQ-0232, REQ-0233, |
REQ-0234: Only supports 8/16bit histogram |
|
IntegralImage |
REQ-0246, REQ-0247, REQ-0248, |
|
|
Median3x3 |
REQ-0300, REQ-0301, REQ-0304, |
REQ-0302: Does not support U1 format |
|
Max |
REQ-0287, REQ-0288, REQ-0289, |
|
|
Min |
REQ-0306, REQ-0307, REQ-0308, |
|
|
Multiply |
REQ-0373, REQ-0374, REQ-0375, |
REQ-0371, |
|
NonMaxSuppression |
REQ-0338, |
|
|
Not |
REQ-0063, REQ-0064, REQ-0067 |
REQ-0065: Does not support U1 format |
|
OpticalFlowPyrLK |
REQ-0344, REQ-0349, REQ-0352, |
REQ-0345, |
|
Or |
REQ-0057, REQ-0058, REQ-0062 |
REQ-0059: Does not support U1 format |
|
Remap |
REQ-0392, REQ-0393, REQ-0394, |
REQ-0399 |
|
ScaleImage |
REQ-0400, REQ-0402, REQ-0403, |
REQ-0412, |
|
Sobel3x3 |
REQ-0416, REQ-0417, REQ-0418, |
|
|
Subtract |
REQ-0022, REQ-0023, REQ-0024, |
REQ-0025: Does not support type conversion, input 1 and input 2 must have the same data type |
|
TableLookup |
REQ-0421, REQ-0422, REQ-0423, |
|
|
Threshold |
REQ-0492, REQ-0494, REQ-0497 |
REQ-0495: Does not support U1 format |
|
WarpAffine |
REQ-0498, REQ-0499, REQ-0501, |
REQ-0500: Does not support U1 format |
|
WarpPerspective |
REQ-0508, REQ-0509, REQ-0510, |
|
|
WeightedAverage |
REQ-0520, REQ-0521, REQ-0522, |
REQ-0518: Deviation is caused by fixed-point representation |
|
Xor |
REQ-0051, REQ-0052, REQ-0056 |
REQ-0053: Does not support U1 format |
|
Pyramid Create |
REQ-0187, REQ-0188, REQ-0189, |
4.2.3 TFLite Shim API
TFLite Shim API is a convenience API that wraps the native C++ API for TensorFlow Lite. TFLite Shim API is considered a shim API because its purpose is to adapt a simple API to a more complex one.
TFLite Shim API is documented in detail at 1.7. Tflite Shim API Reference.
4.2.3.1 Example Code
To illustrate the general approach to writing TF Lite C++ models, some sample code is shown below.
- Include headers, including the standard Android Neural Network and Mediatek proprietary API.
#include <android/NeuralNetworks.h>
#include "NeuroPilotTFLiteShim.h"
- Specify the paths of the TF Lite model and input data.
const char* model_path = "mobilenet.tflite";
const char* input_path = "mobilenet_input.bin";
- Create an ANerualNetworksTFLite instance.
ANeuralNetworksTFLite* tflite = nullptr;
if (ANeuroPilotTFLiteWrapper_makeTFLite(&tflite,
model_path) != ANEURALNETWORKS_NO_ERROR) {
}
- Set the input tensor data that the model will consume.
if (ANeuroPilotTFLiteWrapper_setInputTensorData(tflite,
input_index,
input_buffer,
input_buffer_size) != ANEURALNETWORKS_NO_ERROR) {
ANeuroPilotTFLiteWrapper_free(tflite);
}
- Invoke the model.
if (ANeuroPilotTFLiteWrapper_invoke(tflite) != ANEURALNETWORKS_NO_ERROR) {
ANeuroPilotTFLiteWrapper_free(tflite);
}
- Retrieve the output tensor data.
if (ANeuroPilotTFLiteWrapper_getOutputTensorData(tflite,
output_index,
output_buffer,
output_buffer_size) != ANEURALNETWORKS_NO_ERROR) {
ANeuroPilotTFLiteWrapper_free(tflite);
}
- Prepare a float buffer to store the dequantized model output if the ANeuralNetworksTFLite instance is created from a quantized model.
int bufferSize = output_buffer_size * sizeof(float);
float buffer[bufferSize];
- Compute the dequantized output if the ANeuralNetworksTFLite instance is created from a quantized model.
if (ANeuroPilotTFLiteWrapper_getDequantizedOutputByIndex(tflite,
(void*)buffer,
bufferSize,
0) != ANEURALNETWORKS_NO_ERROR) {
ANeuroPilotTFLiteWrapper_free(tflite);
}
- Free the ANeuralNetworksTFLite instance before ending the program.
ANeuroPilotTFLiteWrapper_free(tflite);
4.2.3.2 Native Sample Code
TFLite Shim API Native sample code can be downloaded at neuropilot_downloads_android_sample_code. There is a Readme.txt file provided which explains the sample code organization, dependencies, build process, and expected results.
4.2.3.3 JNI Sample Code
TFLite Shim API JNI sample code can be downloaded at neuropilot_downloads_android_sample_code. There is a Readme.txt file provided which explains the sample code organization, dependencies, build process, and expected results.
|
Note: |
|
The user must pack the libtflite_static_mtk.so shared library into the APK. This library is included in the JNI sample code. |
4.2.3.4 Cache Usage
- Permission
- The cache must be put in a directory that has read/write permissions.
- Cache testing
- Test using the apk’s cache directory (context.getcachedir().getabsolutepath()) to verify the cache function works.
- Find a directory that has read/write permissions for cache generation.
- Putting the cache into the cache directory before the first initilization may improve compilation speed during the first initilization.
- The cache should be stored at the same path on different devices.
4.2.3.5 Delegate Usage Example
User can change delegate using
ANeuralNetworksTFLiteOptions_setAccelerationMode(ANeuralNetworksTFLiteOptions* options, AccelerationMode mode).
ANeuralNetworksTFLiteOptions_setAccelerationMode(ANeuralNetworksTFLiteOptions* options, AccelerationMode mode);
typedef enum {
// Use CPU to inference the model
NP_ACCELERATION_CPU = 0,
// Turns on Android NNAPI for hardware acceleration when it is available.
NP_ACCELERATION_NNAPI = 1,
// Use Neuron Delegate
NP_ACCELERATION_NEURON = 2,
} NpAccelerationMode;
Below is the example code:
ANeuralNetworksTFLite* tflite = nullptr;
ANeuralNetworksTFLiteOptions* options = nullptr;
ANeuralNetworksTFLiteOptions_create(&options);
//change mode in here
ANeuralNetworksTFLiteOptions_setAccelerationMode(options, NP_ACCELERATION_NEURON);
ANeuroPilotTFLiteWrapper_makeAdvTFLiteWithBuffer(&tflite, kAvgPoolModel,
sizeof(kAvgPoolModel), options);
ANeuroPilotTFLiteWrapper_invoke(tflite);
ANeuralNetworksTFLiteOptions_free(options);
ANeuroPilotTFLiteWrapper_free(tflite);
MediaTek provides a variety of tools and APIs so that developers can extract the highest performance and efficiency from MediaTek devices. This section describes the device-centric capabilities of Neuropilot.
4.3 Advanced Development
4.3.1 AI Benchmark Index
4.3.1.1 Introduction
The MediaTek AI Benchmark Index is a set of reference AI Benchmark results, compiled by MediaTek, for popular neural-network models running on MediaTek platforms with an APU. Each benchmark result contains data on hardware performance and power consumption.
The AI Benchmark Index can help in the following ways:
- Developers can quickly compare the performance and energy efficiency of different MediaTek platforms, without having to run benchmarks or have access to the hardware.
- Developers can understand the AI capabilities of different MediaTek APU platforms, to better decide which platforms to target for development.
- Developers can use the index as a reference guide when training one of the tested AI models or a similar model, to check whether their model performs as expected.
4.3.1.2 MediaTek Platforms AI Benchmark Index Table
|
Model |
Category |
Datatype |
Input/Output Size |
Framework |
#MACs (G) |
#Params (M) |
|
mobilenetv3_quant |
Image classification |
FIX8 |
Input: 512×512x3, Output: 1001 |
TensorFlow Lite |
1.25 |
5.20 |
|
yolo-v4-tiny-quant |
Object |
FIX8 |
Input: 416×416x3, Output: 84x2535 |
TensorFlow Lite |
3.45 |
5.77 |
|
deeplab-v3_quant |
Image segmentation |
FIX8 |
Input: 1024×1024x3, Output: 1024×1024x3 |
TensorFlow Lite |
26.32 |
2.13 |
|
unet_quant |
Image/video noise reduction |
FIX8 |
Input: 1024×1024x3, Output: 1024×1024x3 |
TensorFlow Lite |
70.26 |
1.85 |
|
vsr-quant |
Image/video super resolution |
FIX8 |
Input: 540×960x3, Output: 2160×3840x3 |
TensorFlow Lite |
9.97 |
0.02 |
|
ResNet-50 |
Reference model |
FIX8 |
Input: 224×224x3, Output: 1000 |
TensorFlow Lite |
3.48 |
24.32 |
|
Platforms/Performance & Energy Efficiency |
|||||||||
|
D1200/D1100 (MT6893) |
D9000 (MT6983) |
D8000/D8100 (MT6895) |
D9200 (MT6985) |
MT6886 |
|||||
|
FPS |
FPS/Watt |
FPS |
FPS/Watt |
FPS |
FPS/Watt |
FPS |
FPS/Watt |
FPS |
FPS/Watt |
|
115.93 |
61.03 |
644.24 |
160.14 |
480.16 |
148.04 |
698.73 |
153.15 |
264.00 |
114.96 |
|
123.30 |
47.63 |
657.62 |
141.85 |
503.84 |
146.71 |
737.33 |
142.55 |
318.33 |
143.24 |
|
21.08 |
9.03 |
102.21 |
15.51 |
73.19 |
14.02 |
119.57 |
15.47 |
38.68 |
14.75 |
|
13.63 |
6.10 |
81.83 |
11.99 |
58.75 |
11.39 |
101.00 |
12.23 |
34.60 |
13.90 |
|
6.83 |
3.31 |
58.34 |
12.29 |
53.66 |
13.23 |
86.96 |
15.23 |
32.61 |
15.86 |
|
165.21 |
86.51 |
545.97 |
124.28 |
485.78 |
131.80 |
616.04 |
126.67 |
284.75 |
127.47 |
4.3.1.3 Notes
- Platforms: If there are multiple chips in the same series, the best results in the series are shown.
- Platforms/Performance & Energy Efficiency:
- The performance and energy efficiency data was measured under optimal conditions, with the APU, CPU, and DRAM running at their highest frequencies in Performance mode.
- Energy efficiency data was measured using a hardware power monitoring device.
- Energy efficiency (FPS/Watt) tests were run in Performance mode, and therefore might not represent the optimal energy efficiency measurments for each platform.
- MediaTek can verify the accuracy and authenticity of the data in this index. However, we cannot guarantee that the developers can reproduce the exact results.
4.3.1.4 Downloads
To download all of the models used in these benchmarks, go to DL_Misc.
4.3.2 Platform-Aware Model Design Guide
4.3.2.1 Data Conversion Overhead
The MDLA only supports FP16. For FP32 models, the MDLA compiler uses the MediaTek DMA engine to automatically convert data types from FP32 to FP16 for each input, and convert FP16 to FP32 for each output. To disable this automatic conversion, use the following ncc-tflite compile options:
- --suppress-input: Disable automatic conversion of data types from FP32 to FP16 for each input, and disable data re-layout.
- --suppress-output: Disable automatic conversion of data types from FP16 to FP32 for each output, and disable data re-layout.
|
Note: |
|
To support asymmetric INT8 in MDLA 1.5, the MDLA compiler converts asymmetric INT8 to asymmetric UINT8 for each input, and converts asymmetric UINT8 to asymmetric INT8 for each output. To avoid these overheads on an MDLA 1.5, we suggest using UINT8 rather than INT8 for asymmetric quantization. The data type matrix table is shown below.
- HW means native hardware support in MDLA. No extra data conversion overheads.
- SW means data conversion is performed by software. We suggest users avoid these data types.
|
Data Type |
MDLA 1.5 |
MDLA 2.0 |
MDLA 3.0 |
|
FP32 (–relax-fp32) |
SW |
SW |
SW |
|
FP16 |
HW |
HW |
HW |
|
ASYM UINT8 |
HW |
HW |
HW |
|
ASM INT8 |
SW |
HW |
HW |
|
SYM INT8 |
HW |
HW |
HW |
|
SYM INT16 |
HW |
HW |
HW |
4.3.2.2 Data Layout Optimization
For memory read/write efficiency or hardware constraints, the MDLA may require a special tensor data layout.
The following conditions result in a data re-layout overhead at run time:
- A non-constant input tensor uses an incompatible data layout.
- An output tensor uses an incompatible data layout.
The following conditions result in a data re-layout overhead at compile time:
- A constant input tensor uses an incompatible data layout.
The following conditions result in other data re-layout overheads:
- When two operations A and B run on two different devices, for example the MDLA and the MVPU, then there may be a runtime data re-layout overhead between A and B if the data layout requirements of the two devices are incompatible.
4.3.2.2.1 MDLA Tensor Layouts
The MDLA uses NHWC format for the activation tensors. There are two kinds of data layouts for tensors in external memory (i.e., DRAM and APU TCM):
|
Data Layout |
Applicable Tensors |
Descriptions |
|
4C |
Tensors with C <= 4 |
|
|
16C |
Tensors with any C |
|
The data re-layout overhead mostly comes from MDLA input activation. MediaTek devices use the DMA engine to perform data re-layout at runtime, and we suggest users use an aligned channel size. For the output activation, the MDLA can efficiently output an NHWC tensor without pitch constraints. The data layout of each tensor is determined by the MDLA compiler, based on the given graph and MDLA constraints.
For example:
- Operation A supports 4C and 16C
- Operation B only supports 16C
- A and B are the inputs of an element-wise op (e.g., ADD) or CONCAT
Element-wise ops (e.g., ADD/MUL) and CONCAT require that all inputs use the same data layout. Therefore, the compiler prefers to use a 16C data layout for the output tensor of operation A to avoid data re-layout from 4C to 16C.
|
Optimization Hint To reduce data re-layout overheads, models should avoid using an unaligned channel size. Otherwise, use a channel size with a better data re-layout mechanism. |
|
Optimization Hint Users can use suppressInputConversion and suppressOutputConversion to bypass data re-layout overheads.
|
4.3.2.3 Op Optimization Hints
This section describes operation optimization based on TensorFlow Lite op definitions.
4.3.2.3.1 TFLite Operations
|
Op Name |
Version |
Available |
Optimization Hint |
|
ADD |
1 |
MDLA 1.5 |
|
|
MDLA 3.0 |
|
||
|
SUB |
1 |
MDLA 1.5 |
|
|
MDLA 2.0 |
|
||
|
MDLA 3.0 |
|
||
|
MUL |
1 |
MDLA 1.5 |
|
|
MDLA 3.0 |
|
||
|
DIV |
1 |
MDLA 1.5 |
None |
|
MAXIMUM |
1 |
MDLA 1.5 |
Hardware broadcast is not supported except when the smaller input is a constant. The MDLA compiler supports the SW method which needs extra DMA commands. |
|
MDLA 2.0 |
|
||
|
MDLA 3.0 |
|
||
|
MINIMUM |
1 |
MDLA 1.5 |
Hardware broadcast is not supported except when the smaller input is a constant. MDLA compiler supports the SW method which needs extra DMA commands. |
|
MDLA 2.0 |
|
||
|
MDLA 3.0 |
|
||
|
RESIZE_BILINEAR |
1 |
MDLA 1.5 |
Only supports 16C format. |
|
RESIZE_NEAREST |
1 |
MDLA 1.5 |
Only supports 16C format. |
|
AVERAGE_POOL_2D |
1 |
MDLA 1.5 |
|
|
MAX_POOL_2D |
1 |
MDLA 1.5 |
|
|
L2_POOL_2D |
1 |
MDLA 1.5 |
|
|
MAX_POOL_3D |
1 |
MDLA 3.0 |
|
|
CONV_2D |
1 |
MDLA 1.5 |
|
|
CONV_3D |
1 |
MDLA 3.0 |
Same as CONV_2D. |
|
RELU |
1 |
MDLA 1.5 |
|
|
RELU6 |
1 |
MDLA 1.5 |
|
|
RELU_N1_TO_1 |
1 |
MDLA 1.5 |
|
|
TANH |
1 |
MDLA 1.5 |
|
|
LOGISTIC |
1 |
MDLA 1.5 |
|
|
ELU |
1 |
MDLA 1.5 |
|
|
DEPTHWISE_CONV_2D |
1, 2 |
MDLA 1.5 |
|
|
TRANSPOSE_CONV |
1 |
MDLA 1.5 |
Supports 4C/16C format. There are two ways to run transpose convolution on MDLA: HW native support and SW support. SW-supported transpose convolution can be enabled with a compiler option. |
|
MDLA 3.0 |
|
||
|
CONCATENATION |
1 |
MDLA 1.5 |
The MDLA compiler optimizes away a concatenation operation if each of the operation’s operands only has one user. |
|
FULLY_CONNECTED |
1 |
MDLA 1.5 |
Avoid using FULLY_CONNECTED with or the compiler will insert requant after FULLY_CONNECTED for MDLA 1.5. |
|
RESHAPE |
1 |
MDLA 1.5 |
None |
|
SQUEEZE |
1 |
MDLA 1.5 |
None |
|
EXPAND_DIMS |
1 |
MDLA 1.5 |
None |
|
PRELU |
1 |
MDLA 1.5 |
|
|
SLICE |
1 |
MDLA 1.5 |
|
|
STRIDED_SLICE |
1 |
MDLA 1.5 |
4C: HW only supports strided-slice in W-direction. |
|
SPLIT |
1, 2, 3 |
MDLA 1.5 |
|
|
PAD |
1 |
MDLA 1.5 |
Pad can be fused into the following ops if the padding size <= 15 for H and W dimensions.
Otherwise, extra DMA operations are required. |
|
MDLA 3.0 |
Reflection and Symmetric padding only support NHWC 16C format. |
||
|
MEAN |
1 |
MDLA 1.5 |
HW only supports 16C. |
|
TRANSPOSE |
1 |
MDLA 1.5 |
None |
|
BATCH_TO_SPACE_ND |
1 |
MDLA 1.5 |
None |
|
SPACE_TO_BATCH_ND |
1 |
MDLA 1.5 |
SPACE_TO_BATCH_ND is supported by pure SW implementation; we suggest not using it frequently in your network. |
|
SPACE_TO_DEPTH |
1 |
MDLA 1.5 |
SPACE_TO_DEPTH is supported by pure SW implementation; we suggest not using it frequently in your network. |
|
MDLA 2.0 |
HW supports SPACE_TO_DEPTH. |
||
|
DEPTH_TO_SPACE |
1 |
MDLA 1.5 |
DEPTH_TO_SPACE is supported by pure SW implementation; we suggest not using it frequently in your network. |
|
MDLA 2.0 |
HW support DEPTH_TO_SPACE. |
||
|
NEG |
1 |
MDLA 1.5 |
|
|
ABS |
1 |
MDLA 1.5 |
|
|
POW |
1 |
MDLA 1.5 |
|
|
SQUARED_DIFFERENCE |
1 |
MDLA 1.5 |
SQUARED_DIFFERENCE = (EWE_SUB+EWE_MUL) |
|
QUANTIZE |
1 |
MDLA 1.5 |
Please refer to section: Quantization support. |
|
DEQUANTIZE |
1 |
MDLA 1.5 |
Please refer to section: Quantization support. |
|
Quantized LSTM (5 inputs) |
1, 2 |
MDLA 1.5 |
None |
|
EXP |
1 |
MDLA 2.0 |
|
|
SQUARE |
1 |
MDLA 2.0 |
|
|
SQRT |
1 |
MDLA 2.0 |
|
|
RSQRT |
1 |
MDLA 2.0 |
|
|
RCP |
1 |
MDLA 2.0 |
|
|
SOFTMAX |
1 |
MDLA 2.0 |
None |
4.3.2.3.2 MediaTek Custom Operations in TFLite
Some frequently-used TensorFlow operations do not exist in TFLite, for example: crop_and_resize. Our Tensorflow-to-TFLite converter provides MTK custom ops for customer use.
|
Op Name |
Version |
Available |
Optimization hint |
|
MTK_ABS |
1 |
MDLA 1.5 |
None |
|
MTK_MIN_POOL |
1 |
MDLA 1.5 |
|
|
MTK_TRANSPOSE_CONV |
1 |
MDLA 1.5 |
|
|
MTK_REVERSE |
1 |
MDLA 1.5 |
None |
|
MTK_ELU |
1 |
MDLA 1.5 |
None |
|
MTK_REQUANTIZE |
1 |
MDLA 1.5 |
Please refer to section: Quantization support |
|
MTK_DEPTH_TO_SPACE |
1 |
MDLA 1.5 |
DEPTH_TO_SPACE is supported by pure SW implementation; we suggest not using it frequently in your network. |
|
MTK_CROP_AND_RESIZE |
1 |
MDLA 1.5 |
None |
|
MTK_LAYER_NORMALIZATION |
2 |
MDLA 2.0 |
None |
4.3.2.4 Device Switch Overhead
MDLA compiler supports heterogeneous compilation and partitioning of the graph by device capabilities.
We define device switch overhead from A to B as the execution endpoint of device A to the execution start point of device B.

Figure 8-1. Device switch overhead
- Pre-processing input/output: Perform memory copy for temporary buffers if A and B’s device memory domains are different. For example, MDLA and DSP share the same memory domain so there is no memory copy overhead.
- Prepare for device execution: The initialization time of the device driver.
- Device execution: Hardware IP runtime. Note that the data re-layout overhead is included in this time.
Passing option --show-exec-plan to ncc-tflite displays how the compiler plans to partition the network and devices. To minimize the device switch overhead, we suggest users modify the network to run entirely on the MDLA if possible.
|
Data synchronization overhead The MDLA compiler and runtime manipulate MDLA and DSP device memory using Android’s ION interface. The cache invalidation and flush process will occur when control passes from the CPU to the APU, and from the APU to the CPU. This overhead is typically quite small (<1ms) and transparent to the user. |
|
Optimization Hint: Hardware buffer Users can use Android’s ION buffer for inputs and outputs in order to eliminate unnecessary data copying. Both the MDLA and DSP can directly access the ION buffer. |
4.3.2.5 Runtime Support Features
Users should avoid using features that require runtime support if possible. The following features have runtime overheads:
4.3.2.5.1 Dynamic Shape
Unlike the CPU, the MDLA requires that the shape of each tensor should be known and fixed at compile time. This also allows better optimizations (e.g., tiling) and memory management. To handle models with dynamic shapes, the MDLA compiler must patch MDLA instructions and re-allocate memory at runtime.
4.3.2.5.2 Control Flow
Control flow operations (e.g., IF and WHILE) are not currently natively supported by the MDLA. All control flow operations are handled by the MDLA runtime.
4.3.2.6 Quantization Support
Quantization refers to techniques for performing both computation and memory access with lower precision data. This enables performance gains in several important areas:
- Model size
- Memory bandwidth
- Inference time (due to savings in memory bandwidth and faster computing with integer arithmetic)
In addition to per-layer (per-tensor) quantization, MDLA version 1.5 and later also support per-channel quantization and mixed precision quantization (8-bit/16-bit).
4.3.2.6.1 Per-Channel Quantization
For per-channel quantization, the following data types of input and weight can be supported by MDLA version 1.5 and later.
Per-channel quantization support (MDLA 1.5 and later)
|
Input |
||||
|
ASYM UINT8 |
SYM INT8 |
SYM INT16 |
||
|
Weight |
ASYM UINT8 |
V |
V |
X |
|
SYM INT8 |
V |
V |
X (MDLA 1.5/2.0)/ V (MDLA3.0) |
|
|
SYM INT16 |
X |
X |
V |
4.3.2.6.2 Mixed Precision Quantization (8/16-bit)
To improve accuracy, users can mix 8-bit and 16-bit quantization as well as fp16 in a model. For example, users can use 16-bit quantization (or fp16) for accuracy-sensitive operations and use 8-bit quantization for operations that are not sensitive to accuracy.
The compiler will perform the following steps to support quantization operations:
MTK_REQUANTIZE (integer → integer)
- Try to fuse with the preceding single-use CONV_2D or FULLY_CONNECTED if the op exists.
- Try to fuse with the preceding single-use ABS, NEG, MIN or MAX if the op exists .
- There is no candidate predecessor that MTK_REQUANTIZE can fuse with.
- Map to a BN_ADD, if input and output are the same width.
- Map to a CONV_2D, if input and output width is different. # The CONV_2D with a filter with shape <c, 1, 1, c>.
QUANTIZE (floating-point→ integer)
- Try to fuse with the preceding single-use CONV_2D or FULLY_CONNECTED if the op exists.
- There is no candidate predecessor that QUANTIZE can fuse with.
- Map to a CONV_2D with a filter with shape <c, 1, 1, c>.
DEQUANTIZE (integer → floating-point)
- Check if there is a preceding single-use CONV_2D or FULLY_CONNECTED for fusion.
- There is no candidate predecessor that DEQUANTIZE can fuse with.
- Create a CONV_2D with a filter with shape <c, 1, 1, c>.
- Fuse the CONV_2D or FULLY_CONNECTED with DEQUANTIZE together.
|
Optimization Guide To reduce the overhead:
Note that the preceded layer should have only one use, otherwise compiler cannot merge or fuse the layer. All CONV_2D created by the compiler should have a filter with shape <c, 1, 1, c>. The bandwidth consumption is related to the channel size. |
4.3.2.6.3 Hybrid Quantization
Hybrid quantization stands for convolution-like operations that have float input with quantized weight. This could reduce model size significantly without losing accuracy. However, this kind of quantization is not natively supported by the MDLA 1.5. Operations with hybrid quantization will be executed using float16 type with dequantized weights
MediaTek tools for developers are designed to support developers throughout the entire program implementation process. For all neural network based applications, there is a neural network model development step, and an application programming step, which applies the NN model to the intended task. For advanced users, Neuropilot offers the ability to create custom ops in a neural network model. This is useful for when the network application is to a specialized task, or if more extensive performance is required.
This documentation provides a detailed description of Mediatek’s NeuroPilot software tool suite. This section begins by outlining the subjects covered in the documentation, and then proceeds on to provide an introduction to the various tools, terminology, and goals of the NeuroPilot software.
|
Note: |
|



