NeuroPilot 离线工具(Quantization, Converter etc.)常见问题
**在将模型从Caffe/PyTorch转换为TFLite格式后,因为输入从NCHW更改为NHWC,需要额外添加一个转置节点,有可能避免增加这个额外的操作吗?
【问题描述】
在将模型从Caffe/PyTorch转换为TFLite格式后,因为输入从NCHW更改为NHWC,需要额外添加一个转置节点,有可能避免增加这个额外的操作吗?

【解答】
为了避免添加这个额外的节点,您可以向Caffe/PyTorch模型添加一个wrapper。
对于Caffe,参见NeuroPilot SDK文档:Developer Tools > Model Development > Converter > Converter Tool Examples > Converting from Caffe > Floating-point (with NHWC Input/Output Tensors)。
对于PyTorch,参见NeuroPilot SDK文档:Developer Tools > Model Development > Converter > Converter Tool Examples > Converting from PyTorch > Floating-point (with NHWC Input/Output Tensors)。
**Per-axis Quantization(Per-channel Quantization)和 Per-tensor Quantization两种量化方式解析
【问题描述】
NeuroPilot Quantization tool支持的Per-axis Quantization (Per-channel Quantization)和 Per-tensor Quantization两种量化有什么区别?两者分别的适宜的使用场景是什么?对于最终量化出的模型精度有差异吗?分别通过什么参数进行配置使用?
【解答】
1)区别:
per-tensor就是整个神经网络层用一组量化参数(scale, zero-point),per-channel就是一层神经网络的每个通道用一组量化参数(scale, zero-point),最终会有多组(通道数)量化参数。
2)使用场景:
这个要依据客户模型的需求来看,是否要求每个 channel 有不同的量化参数需求,一般使用场景下一套量化参数(per-tensor)即可满足量化需求。
3)精度有差异吗:
要视具体情况而定,如果要求每个 channel 都有不同的量化参数,那肯定 per-channel 精度更高,反之,不一定。
4)参数配置:
在使用mtk_converter转模型时,通过use_per_output_channel_quantization参数来控制使用per-tensor Quantization (False)还是per-channel Quantization (True)
【适用NP版本】
NP5, NP6
NP-Online Doc Reference:
1. Developer Tools » Model Development » Quantization » Quantization Tool Introduction » Background » Per-axis Quantization and Per-tensor Quantization
2. Mediatek API Reference » Converter Tool API Documentation» Python API
**模型量化后精度不达标的情况,MTK建议有什么继续优化的方案? 混合精度在端侧是否有成熟方案?
【解答】
建议使用 QAT对模型进行量化。精度可以选择 a16w16, 如果对 performance 有要求,也可以使用 a16w8混合量化精度。
如果仍然不满足精度可以再 case by case 讨论。混合精度量化是NeuroPilot5.0后的成熟功能,已有成功落地的案例。
Note:
1)a16w16中的“a”指模型中的activation,“w”指模型中的weight
2)NP-Online Doc Reference:
Developer Tools » Model Development » Quantization » Quantization Tool Introduction » Quantization-Aware Training Tool
**如何判断模型OP是symmetric 还是asymmetric minmax?它们之间的误差范围是多少?
【问题描述】
如何根据Quantization-Aware Training后生成的pb,判断模型OP是symmetric 还是asymmetric minmax?它们之间的误差范围是多少?
【解答】
判断条件:
1)首先查看模型的ATTRIBUTES: narrow range是False还是True?如果是False,则为asymmetric;如果是True,则再进入2)进行判断。
2)查看Fakequant OP中的min/max值,根据bit width来判断,例如min =? (-128/127) * max
参考:Developer Tools » Model Development » Converter » Appendix – Integrate with Custom Quantization-aware Training Tools
【例子】
1)asymmetric
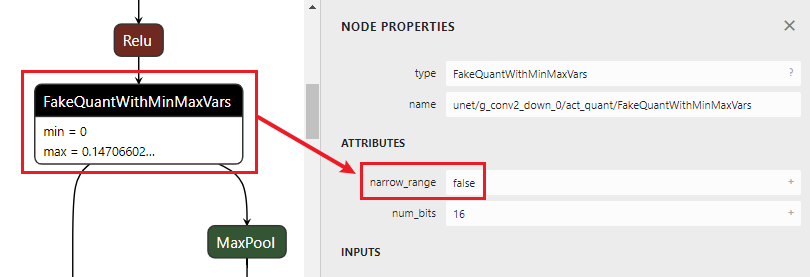

2)symmetric

Neuron SDK常见问题(包括Tools和Neuron RuntimeAPI)
** TFlite编译dla时,报错不支持float32,如何进一步处理?
【问题描述】

【解答】
使用NeuronSDK中的ncc-tflite编译DLA时有参数 “--relax-fp32” 可以将float32 转为float16
NP-Online Doc Reference:
Developer Tools » Model Development » Neuron SDK » Neuron Compiler (ncc-tflite), "--relax-fp32"
【适用NP版本】
NP4, NP5, NP6
**使用neuron runtime API(V1,V2)进行模型推理时的内存分配&释放过程
【问题描述】
基于neuron runtime进行AI模型部署的过程中,内存的分配方式是如何进行的?比如模型初始化阶段内存是否已经完全分配好了?执行阶段是否有新增内存?反初始化(neuron release)是否完全释放掉内存?
【解答】
以NP5的neuron runtime v2 API为例:
(1)对于MDLA和eDMA,模型初始化阶段不会分配Input/output mem,其他的static 、temporary mem会在此阶段時配好;
但如果dla模型推理中是MVPU参与的,那么初始化的时候不仅会把eDMA、MDLA的static、temporary mem分配好,还会把MVPU的input/output、static、temporary mem分配好。
(2)推理的时候,MDLA和eDMA只會另外配input/output mem(假如有用dmabuf就不會再配,因为在此之前已经分配好)。
(3)推理完毕后,所有的mem會被完全釋放。
【适用NP版本】
NP4, NP5, NP6
**如何解读使用ncc-tflite编译模型时下“—show-memory-summary”参数后印出的数据中Static和Temporary的数据?
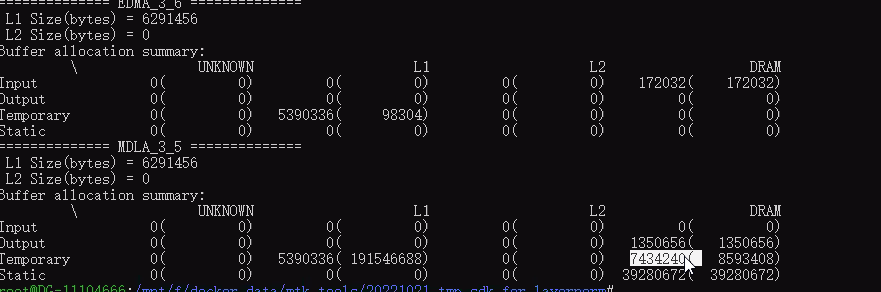
Static是指模型离线编译时就知道的constant 或是tflite檔案裡面就帶有的數值,例如模型透過訓練得到的weight值。
Temporary指的是模型中间张量的working buffer(工作缓冲区),ncc-tflite (compiler)会分析模型中graph的依赖性并会尽量减少缓冲区的使用。
例如,model中有3個op,op1 --> op2 --> op3,執行時,op1算出來的output (也就是op2的input) ,這種就會放在temporary。
【注】但如果用户在使用ncc-tflite编译模型期间下了“–l1-size-kb”配置了APU的L1 cache,那么这里op1算出来的temp data就会尽可能放在L1中(除非放不下才会有额外的temporary mem申请出来存放这部分temp data)。
使用Neuron Runtime API加载模型并初始化创建runtime instance以后, static和temporary对应的mem就会被申请出来(如果是MVPU,则会在此阶段多申请input/output mem),程序就会占用这么多内存。在模型推理过程中,内存占用会在此基础上再增加Input/Output的内存。
不過需要注意的是,V2 API的時候是runtime instance初始化創建起來後就會有,V1 API則是NeuronRuntime_loadNetwork後才會有static + temporary的内存被分配出来。
**使用NP5.x版本的NeuronSDK尝试将Tflite编译为dla档案时遇到“MDLA:data type mismatch for input and filter”问题
使用converter1.4.0转出的Tflite模型可以使用ncc-tflite成功编译为dla,但是使用converter1.5.0转出的Tflite模型使用ncc-tflite编译时会报“MDLA:data type mismatch for input and filter”的错误。
【解决】
1.原因:Converter在1.5.0有一個behavior改動造成了此问题
原本PB模型是asymmetric weight minmax的
在1.4.0的converter轉下來被我們強制改成symmetric quantized,搭配8w16a運算沒有問題 (那時候可能這個強制改動也不會造成太明顯quality issue)
但1.5.0的converter轉下來,我們保留原本asymmetric weight minmax的行為,疑似造成8W16A相關compile error
2.解决方案:
在QAT時改使用symmetric的weight quantization
如果不能改模型,那可能只能先繼續使用v1.4.0的converter了
**使用neuronrt时遇到“error while loading shared libraries: libc++abi.so.1: cannot open shared object file: No such file or directory”报错问题及其解决
【解答】
原因:executor binary找不到相关so导致
解决:在执行binary之前,指定LD_LIBRARY_PATH即可解决,指令:Export LD_LIBRARY_PATH={shared_lib path}
【适用NP版本】
NP4,NP5,NP6
**NeuronRuntimeV2_create API参数解析
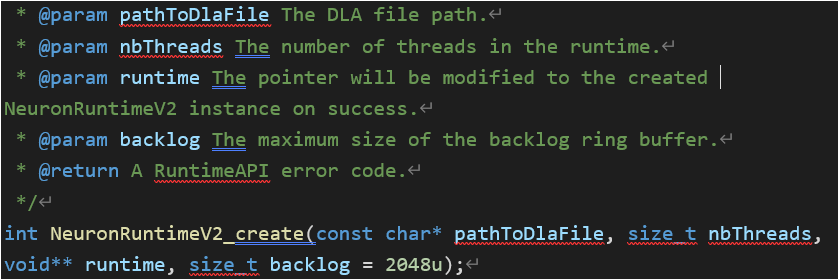
【问题描述】
1)NeuronRuntimeV2_create中的nbThread和backlog参数的含义是什么?
2)应该怎么设置它们? 如果使用SyncInferenceRequest, nbThreads传递0或1?
3)AsyncInferenceRequest和SyncInferenceRequest可以在同一个运行时实例中一起使用吗?
【解答】
1)Neuron5.0 SDK支持线程池。该参数允许用户在自己的代码中管理和维护多线程。此功能与在用户自己的代码中创建多个CPU线程相同,nbthreads的最小值为1。对于同步推理,还可以使用Neuron Runtime V1 API(NeuronRuntime_inference)。
2)Backlog可以理解为在底层可以支持多少推断请求。默认值为2048,一般不需要人为设置。
3)不可以,可能会导致错误。对于同一个运行时实例,你可以先使用Asyn,然后再使用Sync,或者反之亦然,但不能两者都使用。在使用Asyn之前,等待Sync的推断完成。同样,在使用Sync之前,也需要等待Asyn的推理完成。
【适用NP版本】
NP5,NP6
**Neuron Runtime QoS设定说明
【问题描述】
1)Neuron runtime实例创建后是否需要设置NeuronRuntimeV2_setQoSOption(或NeuronRuntime_setQoSOption() ),如果没有设置,默认值是什么?
2)QoSOptions结构中的preference和boostvalue 对APU档位(频率)的影响是什么?会以哪个为准?
3)Neuron runtime setQoSOption需要注意哪些问题?
【解答】
1)参见 Online Doc: Developer Tools » Model Development » Neuron SDK » Neuron Runtime API » QoS Tunning Flow.
用户可以自行设置,如果不设,默认值如下:
// QoS Option for configuration.
typedef struct {
RuntimeAPIQoSPreference preference; // Reserved(可不设)
RuntimeAPIQoSPriority priority; // NEURONRUNTIME_PRIORITY_MED
uint8_t boostValue; //100
uint8_t maxBoostValue; // Reserved(可不设)
uint8_t minBoostValue; // Reserved(可不设)
uint16_t deadline; //0
uint16_t abortTime; //0
int32_t delayedPowerOffTime; //If the customer does not specify how long the APU power should be turned off, it needs to be explicitly set to NEURONRUNTIME_POWER_OFF_TIME_DEFAULT
RuntimeAPIQoSPowerPolicy powerPolicy; // NEURONRUNTIME_POWER_POLICY_DEFAULT
RuntimeAPIQoSAppType applicationType; // NEURONRUNTIME_APP_NORMAL
ProfiledQoSData\* profiledQoSData; //null
} QoSOptions;
2)NP4~6 Neuron Runtime preference设定均为reserved状态,设下去后无效,APU最终的运行档位会以boost value值为准。
3)需要注意的是:
A.QoS设定动作需在inference之前完成;
B.User如果期望只设定QoSOption中的某一个或几个值时,需要同时把其他成员设为以上默认值。
【适用NP版本】
NP5,NP6
**NeuronRuntime_setInput/output的内存操作逻辑和和使用规则是什么?
【问题描述】
对于Neuron RuntimeV1 API中的NeuronRuntime_setInput/output背后的内存操作逻辑是怎样的?且在普通buffer和DMA BUF两种情况下,对于多次inference的场景,设置的规则是怎样的?能否只设置一次然后完成多次推理?
首先,setInput的時候不做Mem Copy,是Inference時才做copy
其次,如果是普通buffer,下一次inference时input内容若有变,就必须重新呼叫setInput。因为setInput會記錄inference時是否要執行memory copy。
但如果是dma buffer,底层是通过fd来操作同一塊內存,没有copy过程,即使下一次inference时input内容有变,也可以不用再次呼叫setInput。
【适用NP版本】
NP4,NP5,NP6
**Neuron Runtime log L1~L4的含义和之间的联系?
【解答】
Runtime Status (LEVEL 1) - Summary: 指user调用libneuron_runtime.so API开始,到整个调用结束后返回的整段在neuron内的耗时。
MicroP Device Status (LEVEL 2) – Summary:neuron中APUSYS Middleware的执行时间,除了Execution time (Execute On Device)外,也包含pre-processing/post-processing等等的时间。
MicroP Driver Execution Time (LEVEL 3) - Summary: 从MDLA driver, MVPU driver, EDMA driver开始,到结果返回后整段在kernel driver层的耗时,可理解为执行在driver层的时间。
MicroP IP Time (LEVEL 4) - Summary: 硬件IP(MDLA, MVPU,EDMA)执行的时间,这层观察到的耗时最接近HW实际运算的时间。
通常,level1的耗时包含level2,level2包含level3,level3包含level4, 剩余多出来的是软件调度切换和等待的时间,统称为SW Overhead.

**Neuron Runtime V1和V2 API的区别是什么?同步和异步模型的典型使用场景分别是什么?MTK是否有这两种模式下的官方推荐AI场景?
NeuroPilot会提供两个版本的Neuron Runtime API,其中V1 API仅支持同步推理模式,V2 API同时支持同步推理和异步推理两种模式。详见:Developer Tools » Model Development » Neuron SDK » Neuron Runtime API » Runtime API Versions
使用同步模式还是异步模式,需要根据用户在具体的AI应用场景中的需求来决定,异步模式可以完成某种程度的平行处理以提升性能。
需要注意的是:
如果使用场景限制了只能使用同步推理模式,则推荐使用V1 API,因为V2 API可能会带来功耗增加的side-effect,因为并行执行会使用更多的硬件资源。且V2 API还可能会增加内存占用,因为每个并行任务都维护自己的工作缓冲区。
【适用NP版本】
NP4,NP5,NP6
模型性能问题分析与优化
**如何分析模型各层算子的耗时占比?
【解答】
1.使用Per-OP (Per-Operation) Performance Profiling工具:
1)使用ncc-tflite编译dla时加入“--gen-debug-info”参数;
2)使用neuronrt进行模型推理时,设定环境变数export MTKNN_PER_OP_PROFILE=1, 且Per-OP耗时不支持设定loop值。
更多细节可以参考NP-Online Doc:Developer Tools » Model Development » Neuron SDK » Neuron Runtime Profiler章节。
但需要注意的是:使用Per-OP Profile方式观测到的耗时是个别OP在某个模型推理过程中的相对占比,而非循环推理过程中的真实耗时。
2.同样也可以使用AI Simulator 确认各层算子耗时,详见NP-Online Doc AI Simulator章节。(https://neuropilot.mediatek.com/ => AI Simulator)
注:当前使用AISIM需要另外开通NeuroPilot Online Doc权限,请转至开发者中心的“联系我们”获取。
【适用NP版本】
NP5,NP6
**如何分析AI模型推理期间的内存占用mem footprint(静态/动态方法)?
【问题描述】
通常在AI应用开发过程中,需要评估AI模型推理期间的APU内存占用(mem footprint)。
【解答】
1.AI模型编译期间DRAM mem footprint评估 (静态方法):
使用NeuronSDK中的ncc-tflite编译模型期间,特别下“--show-memory-summary”参数,结果如下:

1)红色实线框这里,括号内的是AI模型推理期间总共需要进出DRAM的量,括号外的是推理期间某时刻的peak mem access量。
2)我们想要的AI模型推理期间的内存占用量就是指括号外的值加总(input+output+temp+static,虚线框数据) ,然后再加上runtime运行时预留分配的cmd buffer 4MB,来作为单纯AI模型推理过程的内存增量参考数据。
有关其中各项的数据含义解读,请参考:Neuron SDK常见问题(包括Tools和Neuron RuntimeAPI) ==>“如何解读使用ncc-tflite编译模型时下“—show-memory-summary”参数后印出的 Buffer allocation summary各项数据含义?”
2. AI模型集成到具体APP中(Native APP or APK)的mem footprint评估(动态方法):
1)整个AI APP进程Total内存占用,以使用neuronrt或其他neuron_runtime API demo为例:
①进程Total PSS:neuronrt期间执行“dumpsys meminfo + {process name}”命令,会得到neuronrt进程的Total PSS值以及EGL mtrack值:

②进程Total DMA-BUF:
I.系统亮屏静息状态执行“dmabuf_dump -b”命令,得到系统Total DMA-BUF值
II.系统亮屏运行neuronrt期间执行“dmabuf_dump -b”命令,得到系统Total DMA-BUF值
III.两次diff得到neuronrt进程执行期间的Total DMA-BUF值

③neuronrt进程运行期间的Total内存占用(mem footprint)为:
ION/DMABUF + PSS – EGL
2)模型inference期间,APU使用的dmabuf用量数据(纯AI模型的mem footprint)
Neuronrt连续推理期间执行“dmabuf_dump -b”命令,关注DMA-BUF exporter stats中Exporter Name为“apusys”栏位中Total Size(bytes):
I.系统亮屏静息状态执行“dmabuf_dump -b”命令,得到apusys DMA-BUF值
II.系统亮屏运行neuronrt期间执行“dmabuf_dump -b”命令,得到apusys DMA-BUF值
III.两次diff得到neuronrt进程执行期间的Total apusys DMA-BUF值

这其中包含了模型的input/output、static和temp加总的dmabuf内存消耗。
【注】neuronrt默认会分配dmabuf做模型inference期间的input/output buf,因此可以通过下面的方式观察模型推理期间的dmabuf用量。客户自己写的demo可能使用普通buf,因此可能观测不到dmabuf用量。
【适用NP版本】
NP4, NP5, NP6
模型精度问题分析
**模型精度问题分析流程
【问题描述】
客户AI模型适配和评估阶段经常会遇到Accuracy不达预期的问题,那么模型精度问题通常分为哪几种类型?分别应该遵循怎样的SOP去分析与Debug?有哪些工具可以使用?以及相应的example?
【解答】
1.目前客户将pb模型部署到MTK device上一般会经历以下三个步骤(Online compile和Offline compile都会经历):

(1) Pb模型文件用mtk. mtk_converter 工具(或官方转换工具)转换成tflite格式;
(2) Tflite模型文件用ncc-tflite 转换成dla格式;
(3) 在device上运行dla文件。
2.精度问题,目前主要有以下几种类型:
(1) 客户测试所用input文件错误。如:input值没有与模型op的datatype保持一致;
(2) 客户模型中本身的错误,客户未能按照要求提前处理好转换的模型。如:模型中某些op的参数范围超过数据能够容纳的上下限。
(3) converter tool使用错误,如:客户需要uint8格式模型,结果使用mtk_converter转出时配置为int8。
(4) mtk bug或者mtk硬件限制。
3.精度问题SOP(For OEM客户):
Step1:首先应该得到Pb模型的input和golden output。
Step2:使用mtk_converter将pb转换成tflite,参见NP-Online Doc:Developer Tools » Model Development » Converter » Converter Tool Examples。
Step3:确认转出的tflite在PC端运行是否存在精度问题(pb/pt转为tflite阶段):
将上述input输入转换出来的tflite模型,用TFLiteExecutor在PC上跑出结果(参见NP-Online Doc:Developer Tools » Model Development » Converter » Converter Tool Examples » Executing the Converted Model on a Computer), 然后计算两者(golden与PC端运行的)output的余弦相似度(余弦相似度对比代码见附件),如果精度符合预期,说明pb-->tflite步骤不存在精度损失问题。
import numpy as np
tflite_output = np.fromfile('dla.bin', dtype = np.uint8).astype(np.float32)
dla_output = np.fromfile(‘tflite.bin', dtype = np.uint8).astype(np.float32)
cs_tflite_dla = np.dot(tflite_output, dla_output) / np.linalg.norm(tflite_output) / np.linalg.norm(dla_output)
print(cs_tflite_dla)
如果step3中PC端运行的tflite output不满足预期, 则pb转出的tflite已经存在精度损失,进而使用mtk_converter.plot_model_quant_error 查出差异点在哪里,将结果反馈给mtk。参见NP-Online Doc:Developer Tools » Model Development » Converter » Converter Tool Introduction » Error Analysis After Conversion。
Note:
分析问题重点应该先看summary.png这个图,这个图一共包含6个子图:
1.cumulative output difference--number of quant scales
2.cumulative output difference--min(absolute diff, relative diff)
3.layer-wise output difference-- number of quant scales
4.layer-wise output difference--min(absolute diff, relative diff)
5.layer-wise weight difference-- number of quant scales:识别某些特定的算子是否会产生不合理的高量化误差。
6.layer-wise weight difference--min(absolute diff, relative diff):识别某些特定的算子是否会产生不合理的高量化误差。
典型的error: For convolutional operators such as Conv2D, DepthwiseConv2D,and TransposeConv2D
如果step3中PC端运行的tflite output满足预期,但tflite在部署到device端后还是存在精度问题,则进入step4。
Step4:确认模型在device端运行期间出现精度问题:
使用mtk_converter.dissect_tflite_model API将Tflite模型逐层切分(使用最开始的那份input),得到PC的reference result(相当于上述TFLiteExecutor在PC上跑出的结果),其中包含每层OP的input,output,operation sub-model,如下图所示。


(1)如果客户选择的集成方式为online compile method(tflite集成),则将上述一系列sub-models依次加载到device端的应用程序(native executor binary或APK),输入还使用最开始的那份input,最终得到每层sub-model的output*,将其与切分出来的output进行对比,找到有差异的output,最终定位问题OP(方法为对比两份output的余弦相似度)。
(2)如果客户选择的集成方式为offline compile method(dla集成),则将上述一系列sub-models首先通过NeuronSDK编译为dla,然后加载到device端的应用程序(native executor binary,如neuronrt等),输入还使用最开始的那份input,最终得到每层sub-model的output*,将其与切分出来的output进行对比,找到有差异的output,最终定位问题OP(方法为对比两份output的余弦相似度)。
注:过程中如果遇到不预期的问题,请直接联系MTK。
【适用NP版本】
NP5,NP6
模型功耗问题分析
**集成AI Feature后发现整机功耗高,如何理清APU功耗?客户应该遵循怎样的SOP并提供哪些资讯给MTKer分析理清?
【问题描述】
集成AI应用后发现整机功耗高,如何理清APU功耗?客户应该遵循怎样的SOP并提供哪些资讯给MTKer分析理清?
【解答】
1)如果有Power Monitor和功耗拆解板,则可以先进行功耗拆解的实验并将数据提供给MTK(用来佐证功耗上升是否确为APU导致)。
2)如果没有Power Monitor + 功耗拆解板的实验条件,则按照以下步骤2)中说明的方式进行实验并提供MTK需要的数据。
请在目标场景下抓取LTR log + APU Trace + Mobile log(需要包含Neuron runtimeL1-L4的时间)*
提供给MTK进行进一步分析,这样可以理清究竟是不是APU导致的功耗上升,且具体是哪一部分异常导致的功耗上升。
*注:
(1)抓取LTR Log和APU Trace的工具和使用方法请联系AI DRI获取;
(2)抓取符合要求的Mobile log(需要包含Neuron runtimeL1-L4的时间) 需要打开以下Log option:
adb shell setprop debug.neuron.runtime.EnableProfiler true
【适用NP版本】
NP5,NP6
模型集成常见问题
** MTK平台APU Spec与NeuroPilot/Android版本支持逻辑

【说明】
1)NeuroPilot包括:
工具(例如转换器、量化、NAS、AI模拟器、APU Systrace 等)
SDKs(例如NeuronSDK、OpenVX SDK、MVPU SDK等)
APIs(例如TFLite Shim API、Neuron Adapter API、Compiler Custom API、HMP API等)
文档(NeuroPilot在线文档,例如平台-APU规格、Platform-Aware Model Design Guide、Mediatek API Reference等)
教程和示例
2)VF(Vendor Freeze):
它是由Google在2020年提出的,旨在允许只进行Android系统升级,而不改变Vendor。 Vendor Freeze在Android T (NP6.0, D9200)开始正式实施。在此之前平台,除D9000系列/D8000系列原生支持NP5.0的功能外,其他旧平台(D9000以前的芯片,标记了yes*),仅保留API兼容的支持,并不支持新功能。
3)示例:
例如D9000 MT6983平台,根据其发布时间,其最初对应的NeuroPilot和Android版本分别是5.0和S,因此其原生支持NP5.0 + Android S。 随着Android和NeuroPilot的升级进版,该平台系统将继续升级至Android T,但是由于Vendor Freeze,它将不会升级以支持NP6.0的新功能。 后续的其他芯片平台也会遵循这个规则。
**如何确认特定MTK平台中APU的算子支持列表?
【解答】
首先确认目标平台中是否存在APU,首先在“MTK平台APU Spec与NeuroPilot/Android版本支持逻辑”中查看平台APU配置情况。
然后进入https://neuropilot.mediatek.com/ -> Platforms -> {目标平台} -> 登陆账号 -> {目标平台} Documentation (如:Dimensity 9000 Documentation)
【适用NP版本】
NP4, NP5, NP6
**如何评估AI模型在某个MTK平台上的APU兼容性?
评估模型是否能够在给定MTK平台中的APU上跑起来,并且模型的OPs具体跑在哪个硬件上?CPU、GPU、VPU还是MDLA?
【解答】
首先确认平台中配置了APU,该信息可在在“MTK平台APU Spec与NeuroPilot/Android版本支持逻辑”中查询。
1.如果选择offline compile method使用Neuron SDK集成dla的方式,则可以利用NeuronSDK中的compiler(ncc-tflite)工具,使用下面的步骤来检查TFlite模型的平台兼容性
1)./ncc-tflite {filename} --arch {target architecture} --check-target-only
如果支持模型中的所有OPs,则不会印任何信息。
如果模型中有不支持的OP,则会印出unsupported ops和相应的error info,如下所示:

表示MT6877平台的APU(MDLA2.0) 不支持模型中BidirectionalSequenceLSTM OP以及不支持CONV_2D、MUL、ADD OPs的 Float32数据类型。
2)进一步地,如果想了解模型中的OPs在APU上的执行情况,可以使用指令:./ncc-tflite {filename} --arch {target architecture} --show-exec-plan
如果支持模型中的所有OPs,则会印出以下资讯:
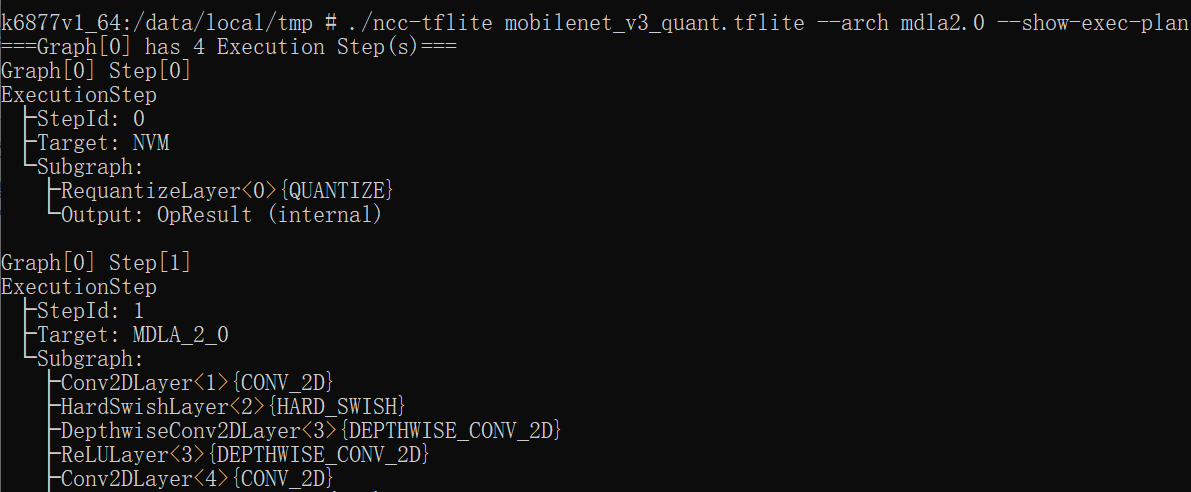

表示MT6877平台的APU(MDLA2.0)支持该模型的所有OPs,并且整个执行过程分为4个STEPs:NVM-->APU(EDMA+MDLA)-->NVM--> APU(EDMA+MDLA)
如果模型中有不支持的OP,则会印出如上文所述的unsupported ops和相应的error info。
【注】:①NVM是Neuron中负责处理APU不支持OP的组件(硬件实体为CPU),EDMA是APU中负责为MDLA做数据搬移和前后处理的组件。
②确认特定平台APU target architecture信息的方法:将NeuronSDK中的ncc-tflite push进手机后执行指令:“./ncc-tflite --arch=?”
2.如果选择online compile method使用Java API 或C++ Shim API集成TFlite的方式,则可以通过mobile log + 开启对应log options的方式来分析:
1)保证测试机是userdebug load或已取得root权限,使用指令“adb shell setenforce 0”关闭Selinux,连接手机后执行以下log options:
adb shell setprop debug.neuron.runtime.ShowTargetReport true
(Enable showing Neuron target report for unsupported OPs)
adb shell setprop debug.neuron.runtime.ShowExecPlan true
(Enable showing Neuron execution plan)
2)运行APK或Native Executor Binary进行模型推理,使用指令“adb shell logcat”抓取完整执行过程的Android log。
①NP4(D9000之前)平台Example:
i.模型Target Report log:
11-23 17:02:55.506 7187 7187 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: Target report:
11-23 17:02:55.506 7187 7187 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: NIR[1]: Conv2DLayer<2>{CONV_2D}
11-23 17:02:55.507 7187 7187 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ MDLA: per channel quantization is unsupported
11-23 17:02:55.508 7187 7187 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ MDLA: Filter data type and input data type should be consistent
11-23 17:02:55.509 7187 7187 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: NIR[3]: Conv2DLayer<3>{CONV_2D}
11-23 17:02:55.510 7187 7187 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ MDLA: per channel quantization is unsupported
11-23 17:02:55.511 7187 7187 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ MDLA: Filter data type and input data type should be consistent
ii.模型Execution Plan log:
11-23 17:02:54.974 7201 7201 I Manager : Found interface mtk-neuron
11-23 17:02:55.600 7201 7201 I ExecutionPlan: ModelBuilder::findBestDeviceForEachOperation(DEQUANTIZE:0) = 3 (mtk-neuron)
11-23 17:02:55.600 7201 7201 I ExecutionPlan: ModelBuilder::findBestDeviceForEachOperation(QUANTIZE:1) = 3 (mtk-neuron)
11-23 17:02:55.600 7201 7201 I ExecutionPlan: ModelBuilder::findBestDeviceForEachOperation(CONV_2D:2) = 3 (mtk-neuron)
11-23 17:02:55.600 7201 7201 I ExecutionPlan: ModelBuilder::findBestDeviceForEachOperation(CONV_2D:3) = 3 (mtk-neuron)
11-23 17:02:55.600 7201 7201 I ExecutionPlan: ModelBuilder::findBestDeviceForEachOperation(MAX_POOL_2D:4) = 3 (mtk-neuron)
……
11-23 17:02:56.216 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: Execution plan:
11-23 17:02:56.216 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ===Graph[0] has 2 Execution Step(s)===
11-23 17:02:56.217 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: Graph[0] Step[0]
11-23 17:02:56.218 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ExecutionStep
11-23 17:02:56.219 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ StepId: 0
11-23 17:02:56.220 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ Target: MDLA_1_0
11-23 17:02:56.222 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ Subgraph:
11-23 17:02:56.223 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ RequantizeLayer<1>{QUANTIZE}
11-23 17:02:56.224 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ Output: OpResult (internal)
11-23 17:02:56.225 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron:
11-23 17:02:56.226 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: Graph[0] Step[1]
11-23 17:02:56.227 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ExecutionStep
11-23 17:02:56.228 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ StepId: 1
11-23 17:02:56.229 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ Target: VPU
11-23 17:02:56.230 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ Subgraph:
11-23 17:02:56.231 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ Conv2DLayer<2>{CONV_2D}
11-23 17:02:56.232 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ ReLULayer<2>{CONV_2D}
11-23 17:02:56.234 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ Conv2DLayer<3>{CONV_2D}
11-23 17:02:56.235 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ ReLULayer<3>{CONV_2D}
11-23 17:02:56.236 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ MaxPool2DLayer<4>{MAX_POOL_2D}
……
11-23 17:02:56.256 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ Conv2DLayer<15>{CONV_2D}
11-23 17:02:56.257 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ ReLULayer<15>{CONV_2D}
11-23 17:02:56.258 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ RequantizeLayer
11-23 17:02:56.259 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ RequantizeLayer
11-23 17:02:56.260 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ RequantizeLayer
11-23 17:02:56.261 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ RequantizeLayer
11-23 17:02:56.262 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ RequantizeLayer
11-23 17:02:56.263 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ Output: OpResult (external)
11-23 17:02:56.264 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ Output: OpResult (external)
11-23 17:02:56.265 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ Output: OpResult (external)
11-23 17:02:56.267 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ Output: OpResult (external)
11-23 17:02:56.268 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ Output: OpResult (external)
11-23 17:02:56.269 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron:
11-23 17:02:56.270 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ===End of Graph[0]===
11-23 17:02:56.271 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron:
11-23 17:02:56.272 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: TargetExecutionOrder:
11-23 17:02:56.273 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: ├ MDLA_1_0
11-23 17:02:56.274 7187 7190 I android.hardware.neuralnetworks@1.3-service-mtk-neuron: └ VPU
i.模型Target Report log:
08-25 06:25:38.147 4815 4815 E neuron : ERROR: Target report:
08-25 06:25:38.147 4815 4815 E neuron : ERROR: NIR[0]: Conv2DLayer<0>{CONV_2D}
08-25 06:25:38.148 4815 4815 E neuron : ERROR: ├ EDMA: unsupported operation
08-25 06:25:38.149 4815 4815 E neuron : ERROR: ├ MVPU: Can't find mvpu op in registration table. opcode(3), custom op name()
08-25 06:25:38.150 4815 4815 E neuron : ERROR: ├ MVPU: Can't find mvpu op in registration table. opcode(3), custom op name()
08-25 06:25:38.150 4815 4815 E NeuronCanonicalDelegate: Model operations are not fully supported
ii.模型Execution Plan log:
08-25 06:25:38.104 4815 4815 I neuron : INFO: Execution plan:
08-25 06:25:38.104 4815 4815 I neuron : INFO: ===Graph[0] has 1 Execution Step(s)===
08-25 06:25:38.105 4815 4815 I neuron : INFO: Graph[0] Step[0]
08-25 06:25:38.106 4815 4815 I neuron : INFO: ExecutionStep
08-25 06:25:38.107 4815 4815 I neuron : INFO: ├ StepId: 0
08-25 06:25:38.108 4815 4815 I neuron : INFO: ├ Target: MDLA_3_5
08-25 06:25:38.110 4815 4815 I neuron : INFO: └ Subgraph:
08-25 06:25:38.111 4815 4815 I neuron : INFO: ├ SliceLayer<1>{QUANTIZE}
08-25 06:25:38.112 4815 4815 I neuron : INFO: ├ RequantizeLayer<1>{QUANTIZE}
08-25 06:25:38.113 4815 4815 I neuron : INFO: ├ SpaceToDepthLayer<2>{SPACE_TO_DEPTH}
08-25 06:25:38.114 4815 4815 I neuron : INFO: ├ SliceLayer<1>{QUANTIZE}
08-25 06:25:38.115 4815 4815 I neuron : INFO: ├ RequantizeLayer<1>{QUANTIZE}
08-25 06:25:38.116 4815 4815 I neuron : INFO: ├ SpaceToDepthLayer<2>{SPACE_TO_DEPTH}
08-25 06:25:38.117 4815 4815 I neuron : INFO: ├ ConcatLayer<2>{SPACE_TO_DEPTH}
08-25 06:25:38.118 4815 4815 I neuron : INFO: ├ SliceLayer<1>{QUANTIZE}
08-25 06:25:38.119 4815 4815 I neuron : INFO: ├ RequantizeLayer<1>{QUANTIZE}
08-25 06:25:38.121 4815 4815 I neuron : INFO: ├ SpaceToDepthLayer<2>{SPACE_TO_DEPTH}
08-25 06:25:38.122 4815 4815 I neuron : INFO: ├ SliceLayer<1>{QUANTIZE}
08-25 06:25:38.123 4815 4815 I neuron : INFO: ├ RequantizeLayer<1>{QUANTIZE}
08-25 06:25:38.124 4815 4815 I neuron : INFO: ├ SpaceToDepthLayer<2>{SPACE_TO_DEPTH}
08-25 06:25:38.125 4815 4815 I neuron : INFO: ├ ConcatLayer<2>{SPACE_TO_DEPTH}
08-25 06:25:38.126 4815 4815 I neuron : INFO: ├ ConcatLayer<2>{SPACE_TO_DEPTH}
08-25 06:25:38.127 4815 4815 I neuron : INFO: └ Output: OpResult (external)
08-25 06:25:38.128 4815 4815 I neuron : INFO:
08-25 06:25:38.129 4815 4815 I neuron : INFO: ===End of Graph[0]===
08-25 06:25:38.130 4815 4815 I neuron : INFO:
08-25 06:25:38.131 4815 4815 I neuron : INFO: TargetExecutionOrder:
08-25 06:25:38.132 4815 4815 I neuron : INFO: ├ EDMA_3_6
08-25 06:25:38.134 4815 4815 I neuron : INFO: └ MDLA_3_5
08-25 06:25:38.135 4815 4815 I neuron : INFO:
08-25 06:25:38.136 4815 4815 I neuron : INFO:
08-25 06:25:38.136 4815 4815 I ExecutionPlan: ExecutionPlan::SimpleBody::finish: compilation finished successfully on mtk-neuron
08-25 06:25:38.136 4815 4815 I ExecutionPlan: SIMPLE for mtk-neuron
【适用NP版本】
NP4, NP5, NP6
**选择NeuroPilot Online Compile Method基于TFlite模型集成时Neuron Delegate与NNAPI Delegate的选择
1)当User选择NeuroPilot Online Compile Method基于TFlite模型集成时,Neuron Delegate相比于NNAPI Delegate的优势是什么?
2)三方客户从使用NNAPI Delegate切换到使用Neuron Delegate需要考虑哪些问题?改动的effort大吗?
3)前后多代MTK平台中Neuron Delegate的一致性和兼容性如何?客户维护Neuron delegate 的effort会比NNAPI大吗?
【解答】
优势:
1)更少的SW Stack,因此性能更好。
2)更佳的灵活性: NNAPI Delegate通路中存在一些Google对OP的限制(Google代码,不能修改);Neuron Delegate完全由MTK开发维护,允许用户创建TensorFlow Lite内置操作之外的自定义OP,可扩展性更好。
改动的Effort:
1)将AOSP NNAPI Delegate run pass的模型和代码,切换到Neuron Delegate,effort较小;除了Option有差异外,用法基本一致;
2)通常平台升级都会考虑到软件兼容性的问题并且会做相应的测试,这方面问题需要case by case来看。
【适用NP版本】
NP4,NP5,NP6
**MTK Neuron支持动态分辨率和动态batch输入么?
==》
1)D9000(NP5)及之前的平台均不支持动态分辨率(Dynamic shape)和动态batch输入。
2)D9200(NP6)以后的平台,可以支持动态batch输入的功能。
动态batch输入功能详见:NP6 Online Doc:Developer Tools » Model Development » Neuron SDK » Neuron DLA Muxer API
**APU是否支持多核并发机制?具体如何实现模型在做推理的时候调用APU实现多核并发加速推理?
【解答】
1.如果选择offline compile method使用Neuron SDK集成dla的方式,可以使用以下方式完成多核并发加速推理:
1)硬件级别多核并发:
在ncc-tflite编译dla的时候特别下优化编译指令可以实现APU SMP多核并行,规则如下(cmd1和cmd2等效):
开SMP compile cmd1:“--opt 3” + “--num-mdla > 1 (≤max_mdla)”
开SMP compile cmd2:“--gno SMP” + “--num-mdla > 1(≤max_mdla)”
注意:
I.只要当“--num-mdla = 1”,则SMP多核并行将不会生效。
II. “--num-mdla > 1(only)” or “--opt=3(only)” ,则不会开SMP。
2)CPU 多线程级别并发:
针对NP4的Neuron RuntimeV1 API,上层user可以通过创建CPU多线程的方式实现APU多核并发。
针对NP5以后的Neuron RuntimeV2 API,NeuronRuntimeV2_create() API中提供了“nbThreads”参数,其最小值为1,最大值建议设为平台MDLA核数+1(不宜过大),user可以直接设置该参数来开启CPU多线程以实现APU多核并发(注意与SMP硬件级多线程不同)。
2.如果选择online compile method使用Java API 或C++ Shim API集成TFlite的方式,可以使用以下方式完成多核并发加速推理:
1)上层user可以分别在AAR(Java)代码中设neuron_options.setEnableLowLatency(true) 来hint底层完成APU SMP硬件级多核并发。
或在C++ Shim API代码中设ANeuralNetworksTFLiteOptions_setLowLatency(enableLowLatency=true)来hint底层完成APU SMP硬件级多核并发。
注:上层调用setLowLatency API后,系统会根据平台中MDLA的最大核数来进行SMP配置。
2)上层user还可以分别在Java代码或C++ Shim API代码中自行起CPU多线程来开启CPU多线程以实现APU多核并发(注意与SMP硬件级多线程不同)。
【适用NP版本】
NP4,NP5,NP6
**是否可以通过NeuroPilot使用MTK平台的GPU进行模型的推理?
【解答】
MTK NeuroPilot SDK对所有智能手机平台(with APU, without APU)均不开放user 自主选择GPU来进行AI模型推理的自由度。
1.对于选择online compile method使用Java API 或C++ Shim API集成TFlite的开发者来说,GPU被使用的情况仅仅是选择进入neuron delegate或nnapi delegate后如果某个op不能被APU支持的情况下被动dispatch到GPU上进行运算的结果。
1)APU平台,存在CPU、NNAPI Delegate、Neuron Delegate三个选择
2)No APU平台,存在CPU、NNAPI Delegate、Neuron Delegate三个选择,实际只有CPU和NNAPI Delegate两个(Neuron SW在NoAPU平台不存在,会自动切NNAPI)
2.对于选择offline compile method使用Neuron SDK集成dla的开发者来说,NeuronSDK不支持GPU Backend(neuron compiler编译模型时无法选择GPU)。



